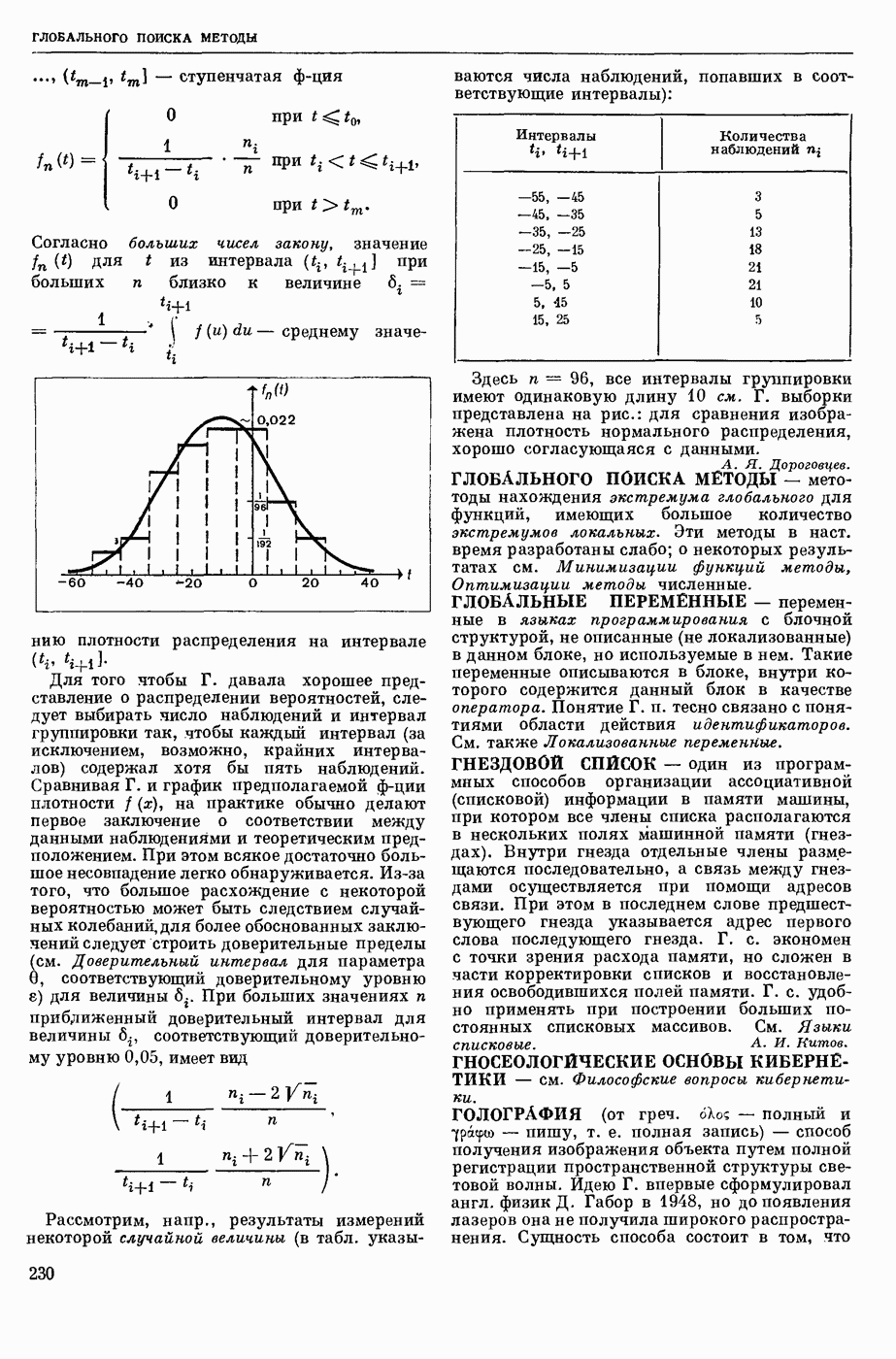
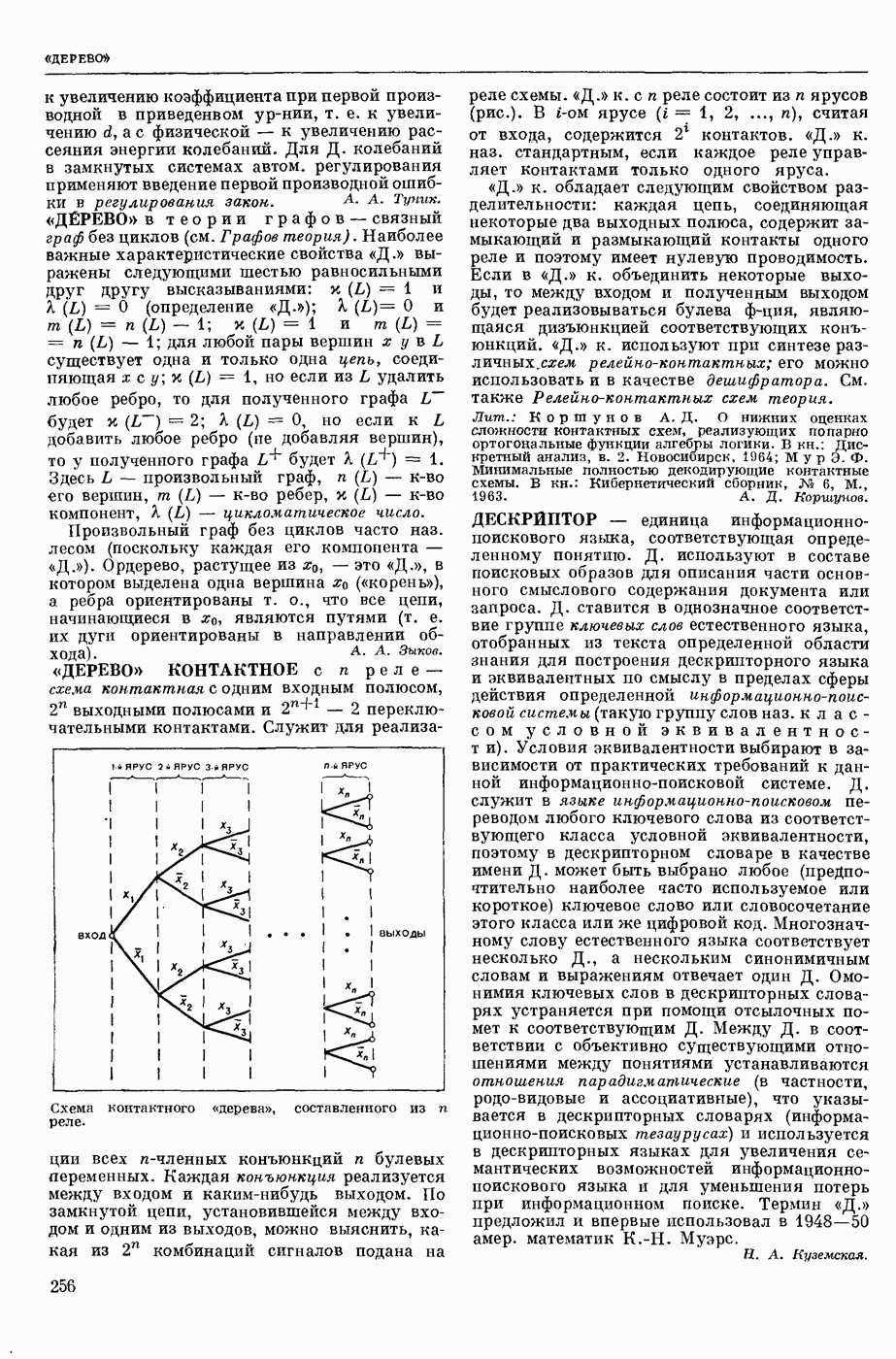
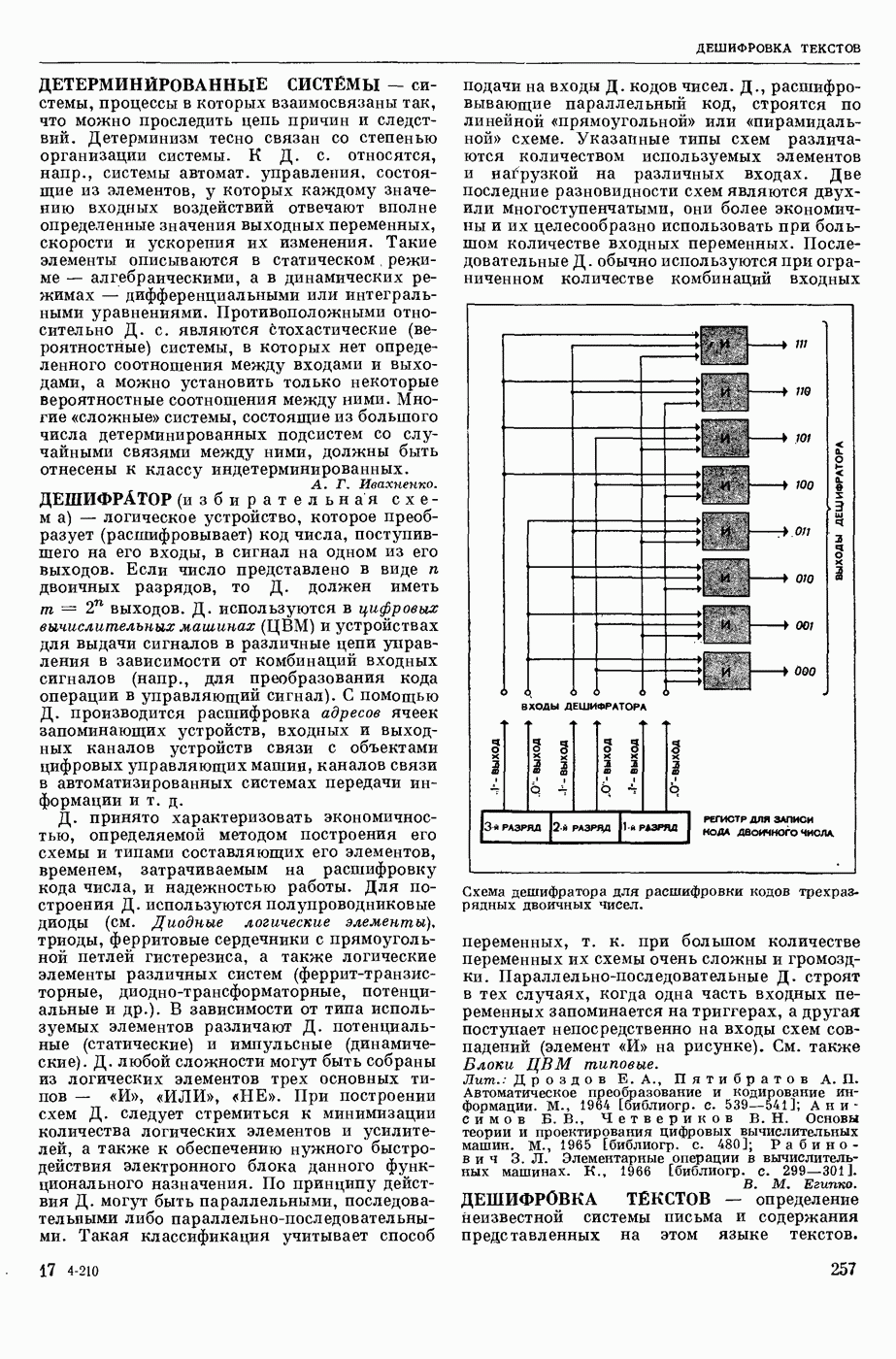
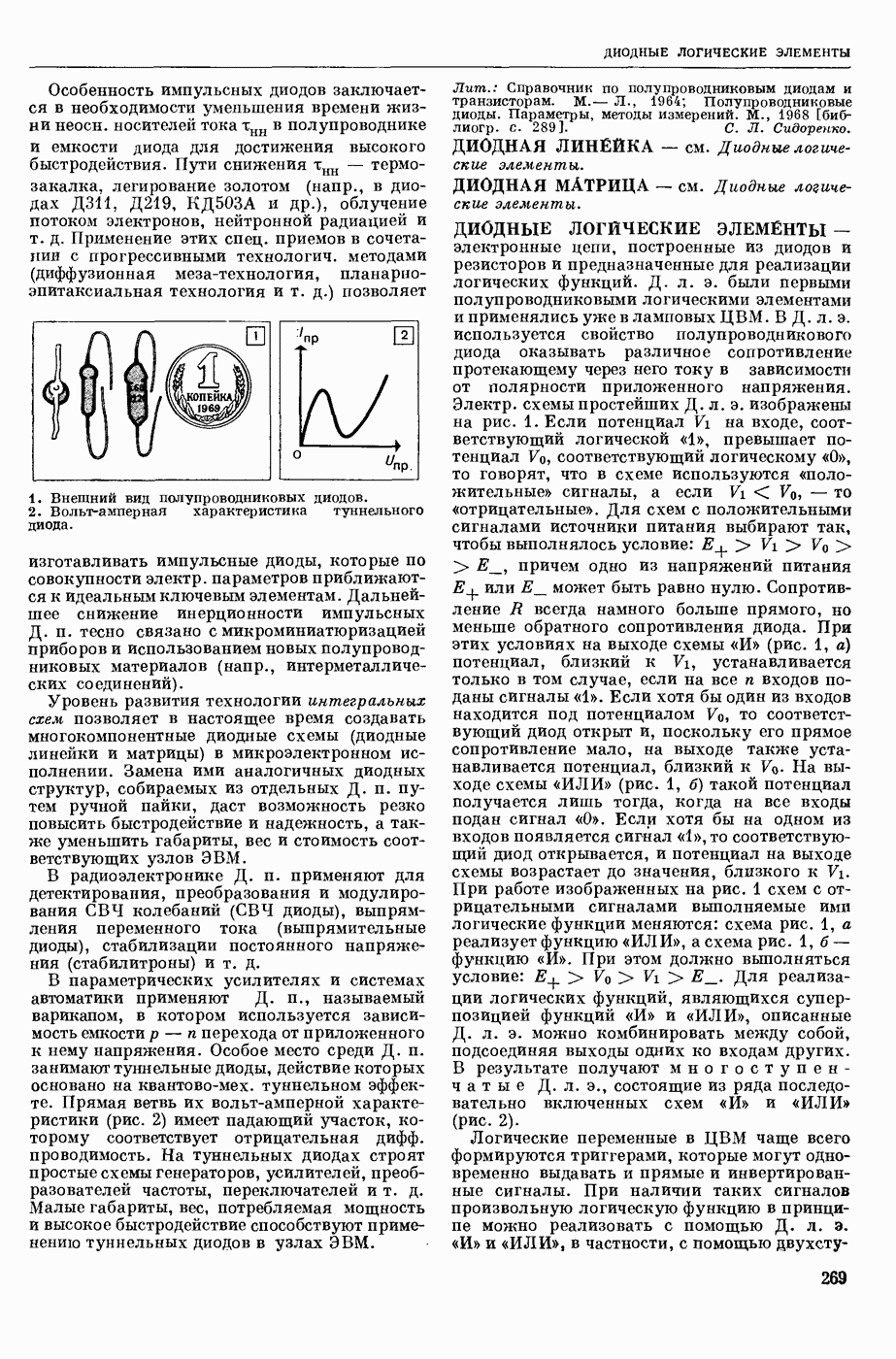
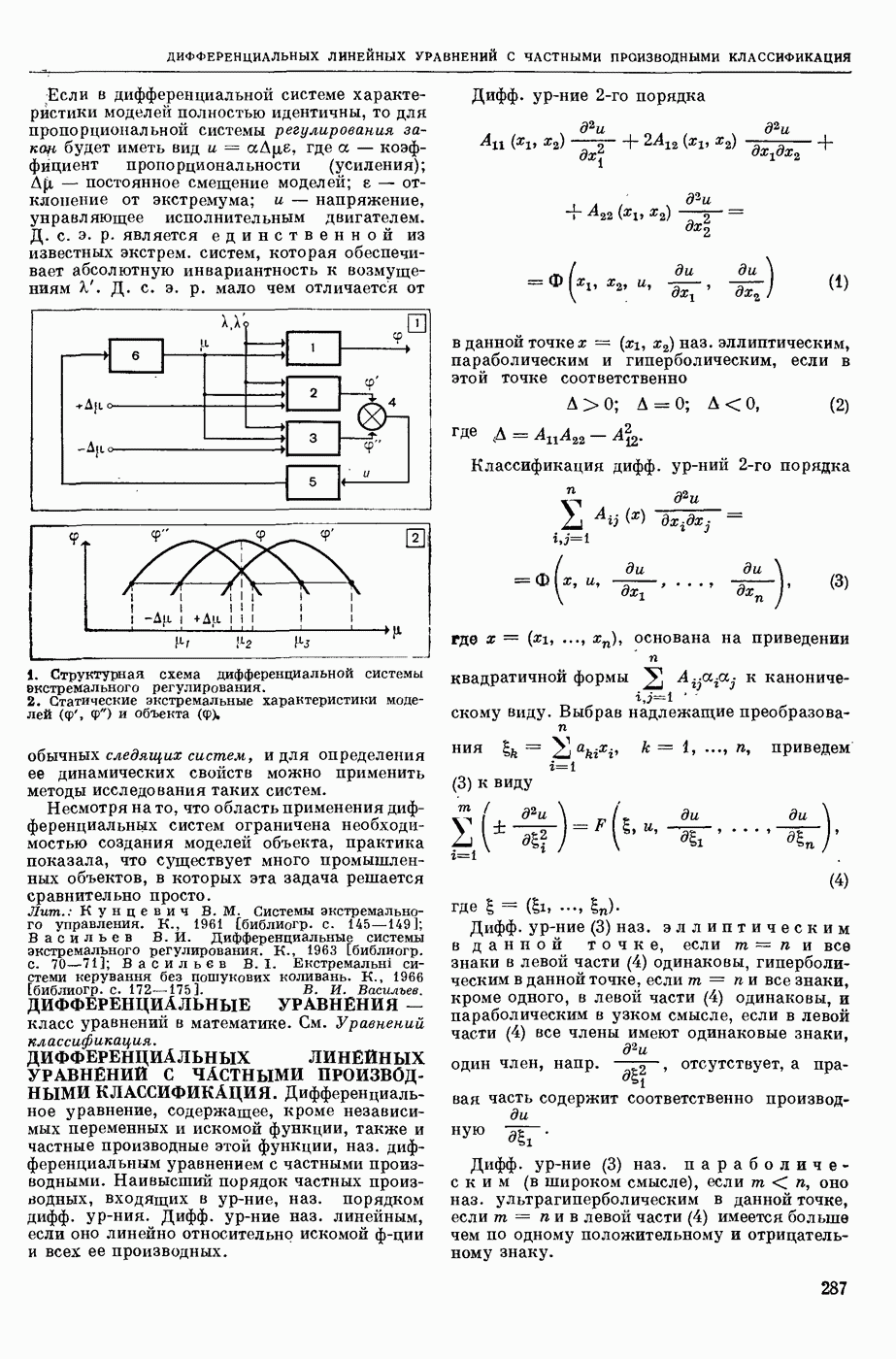
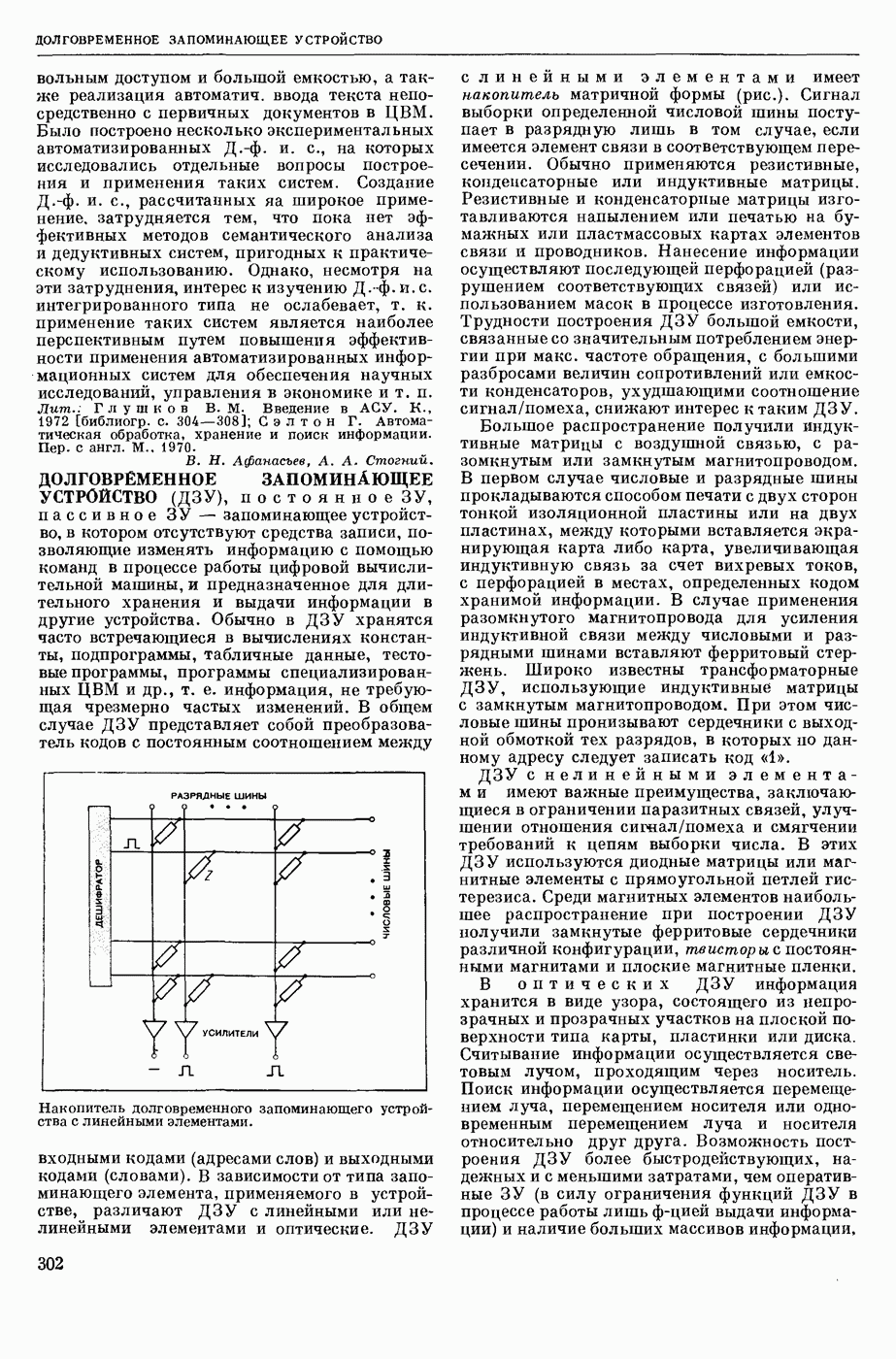
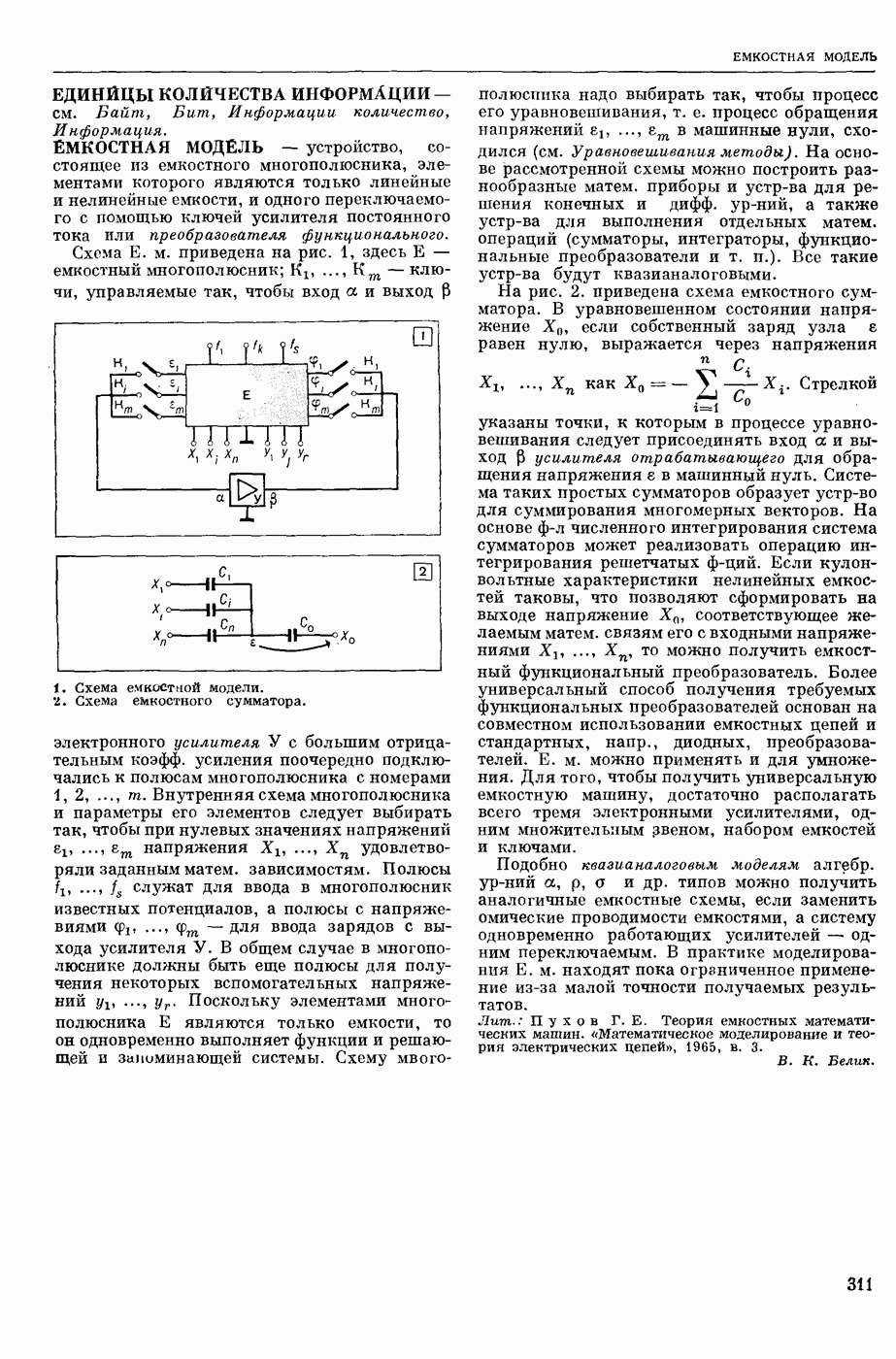
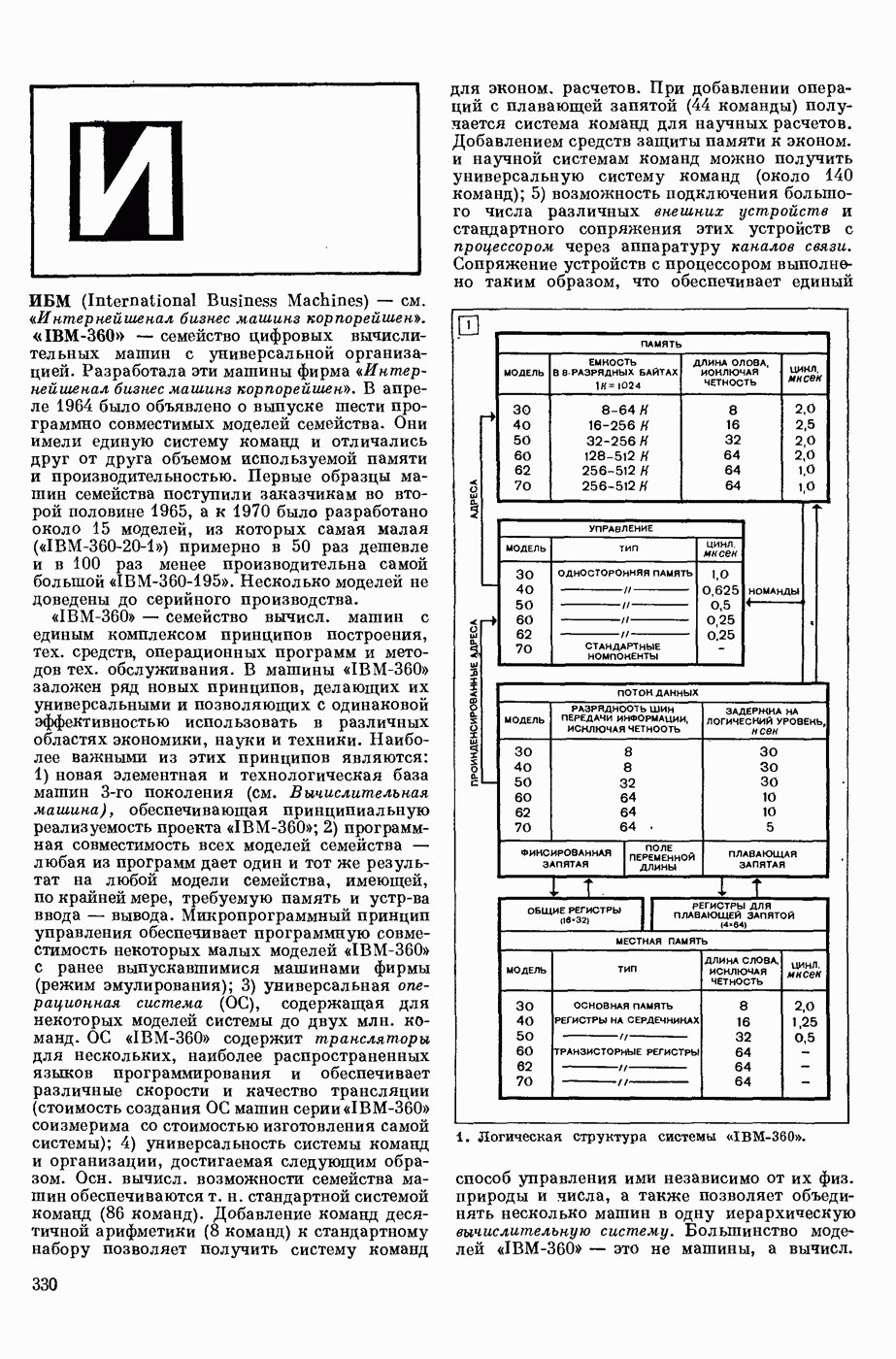
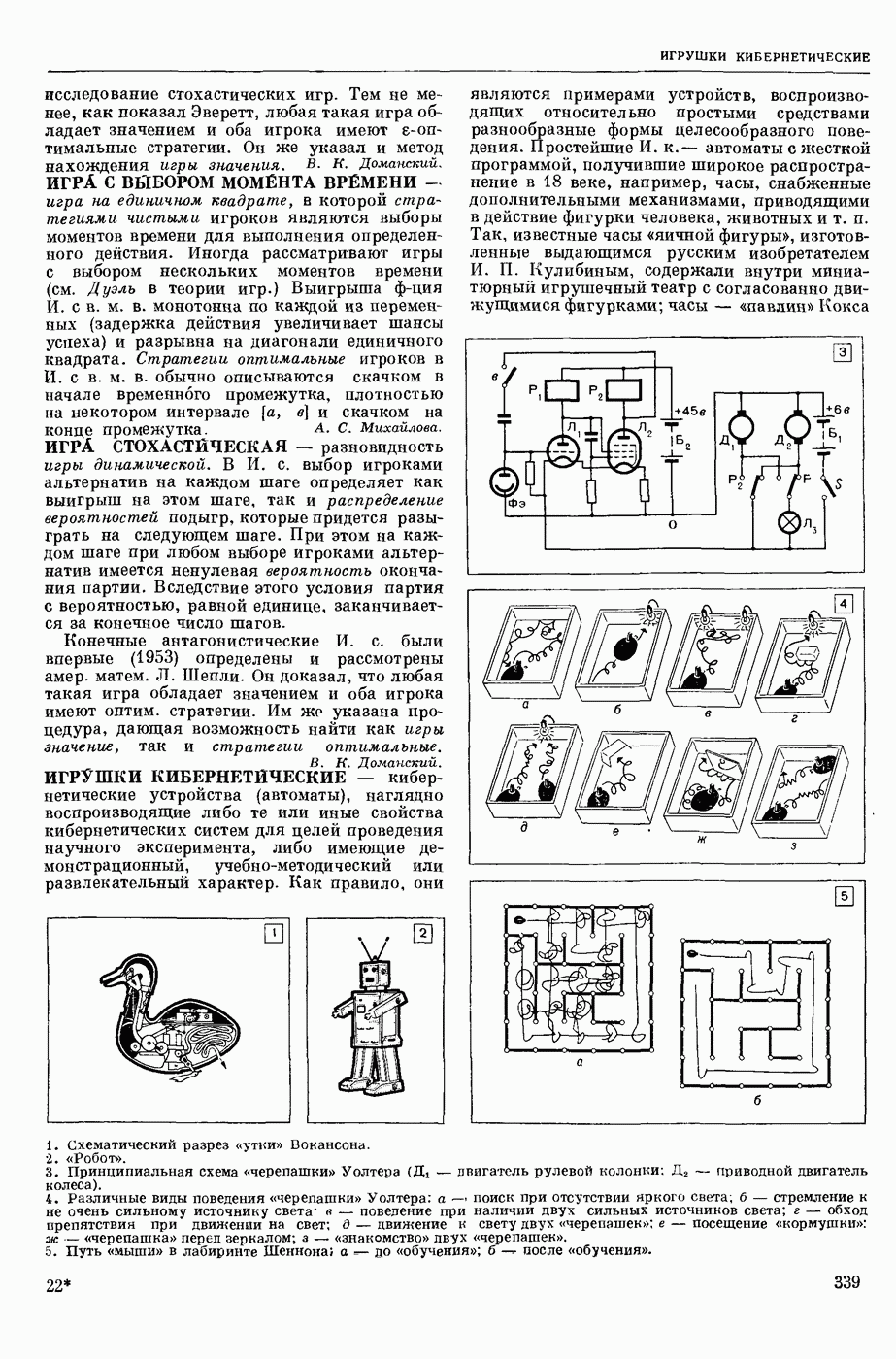
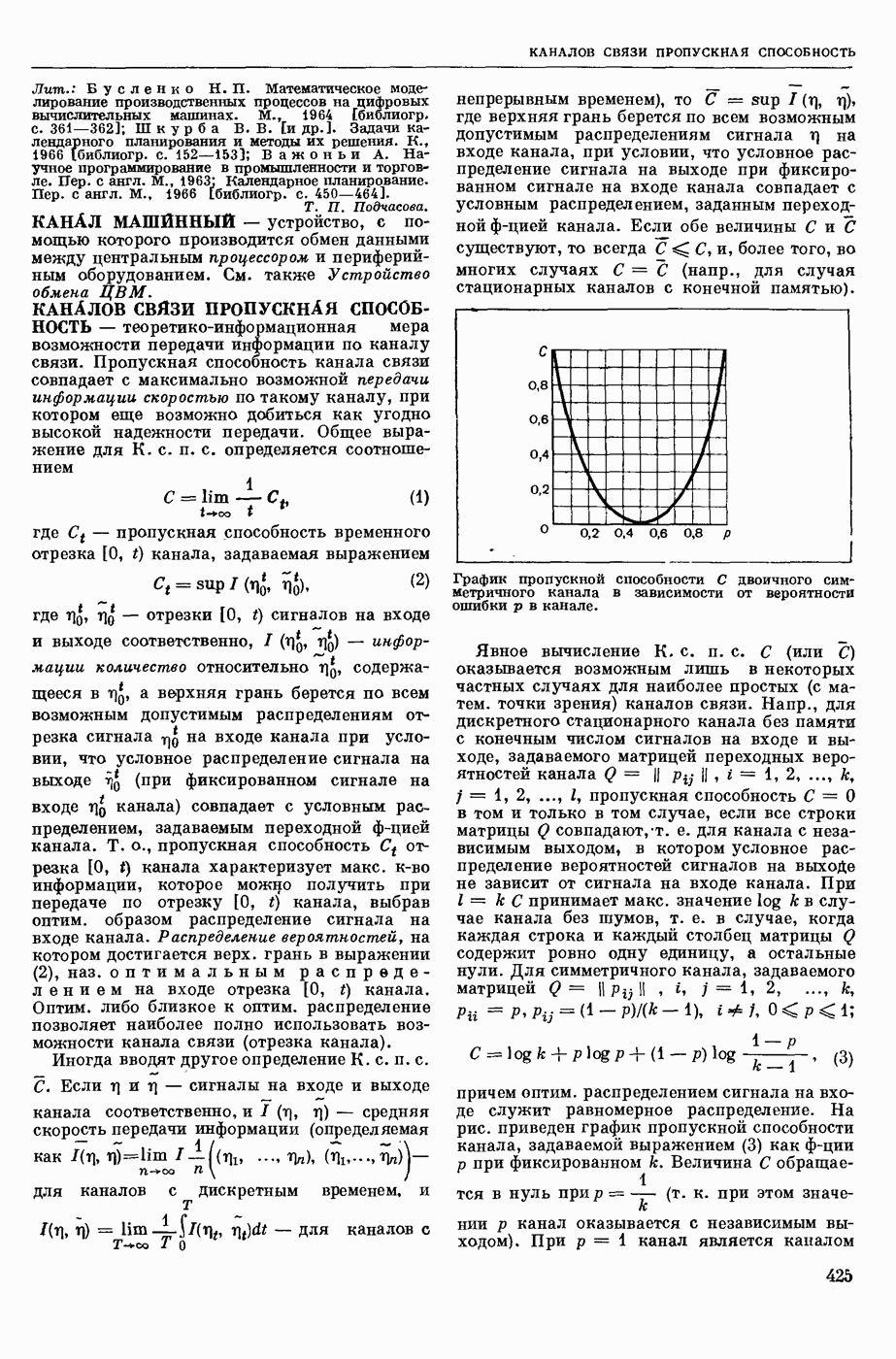
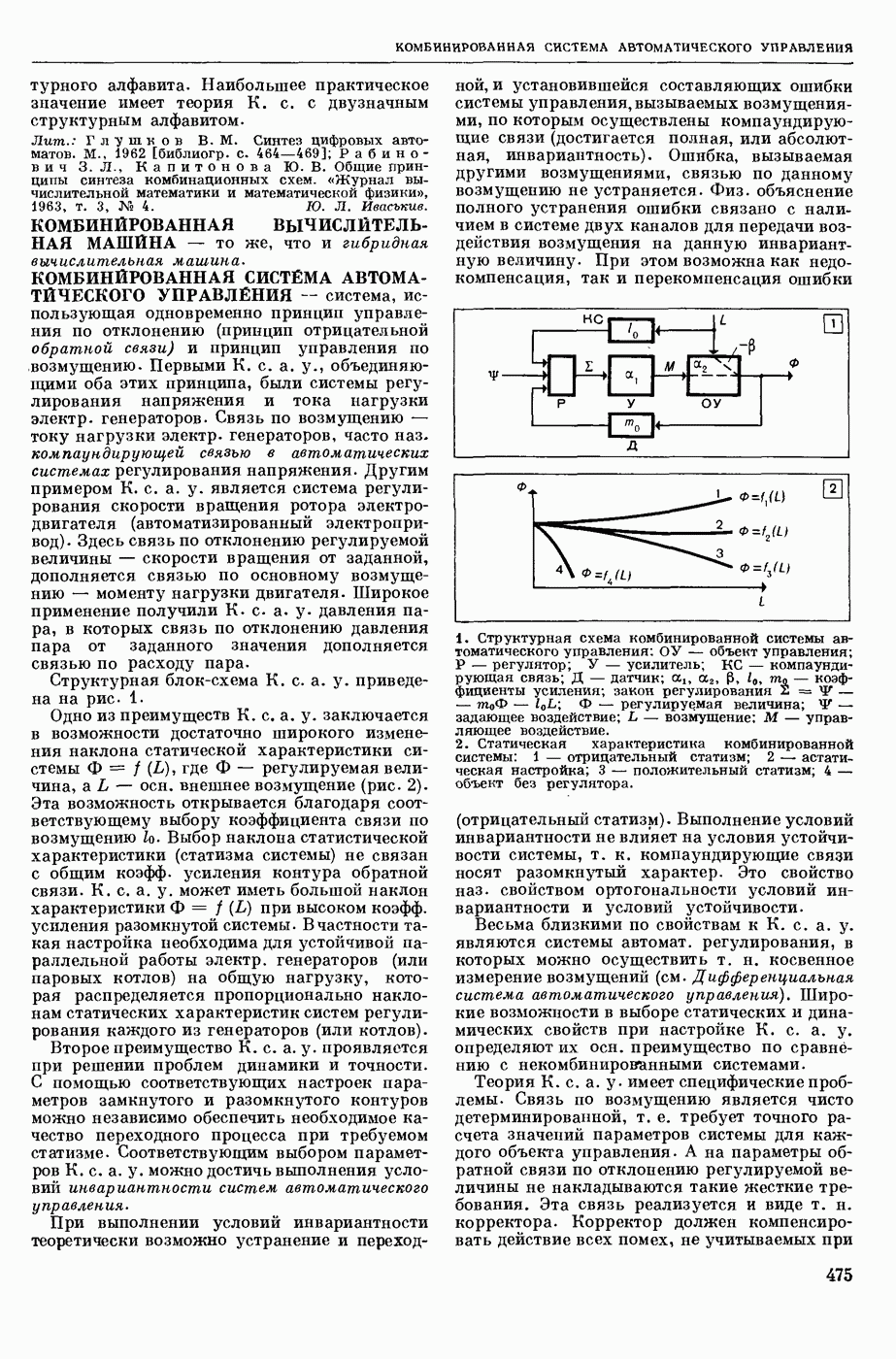
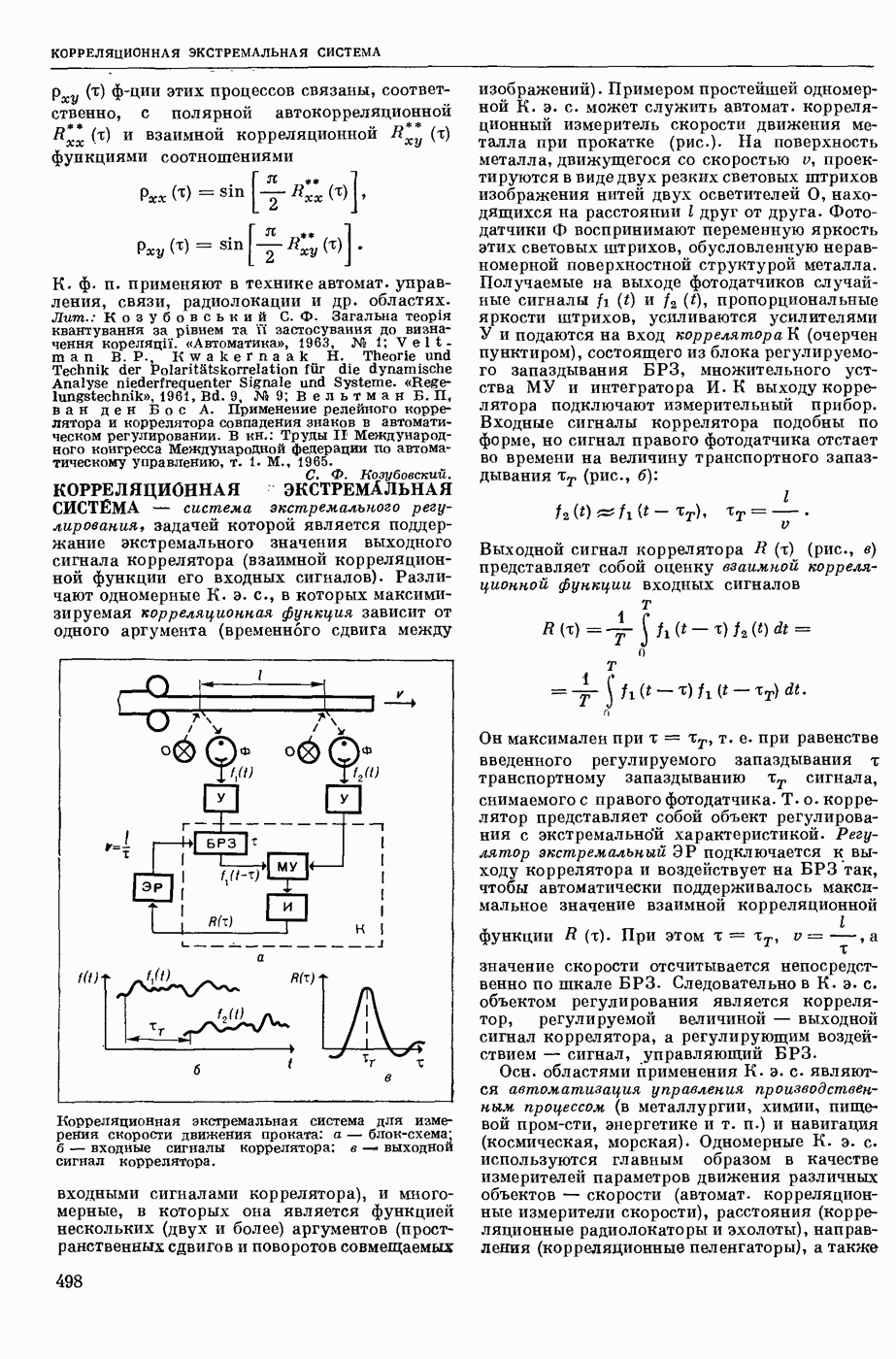
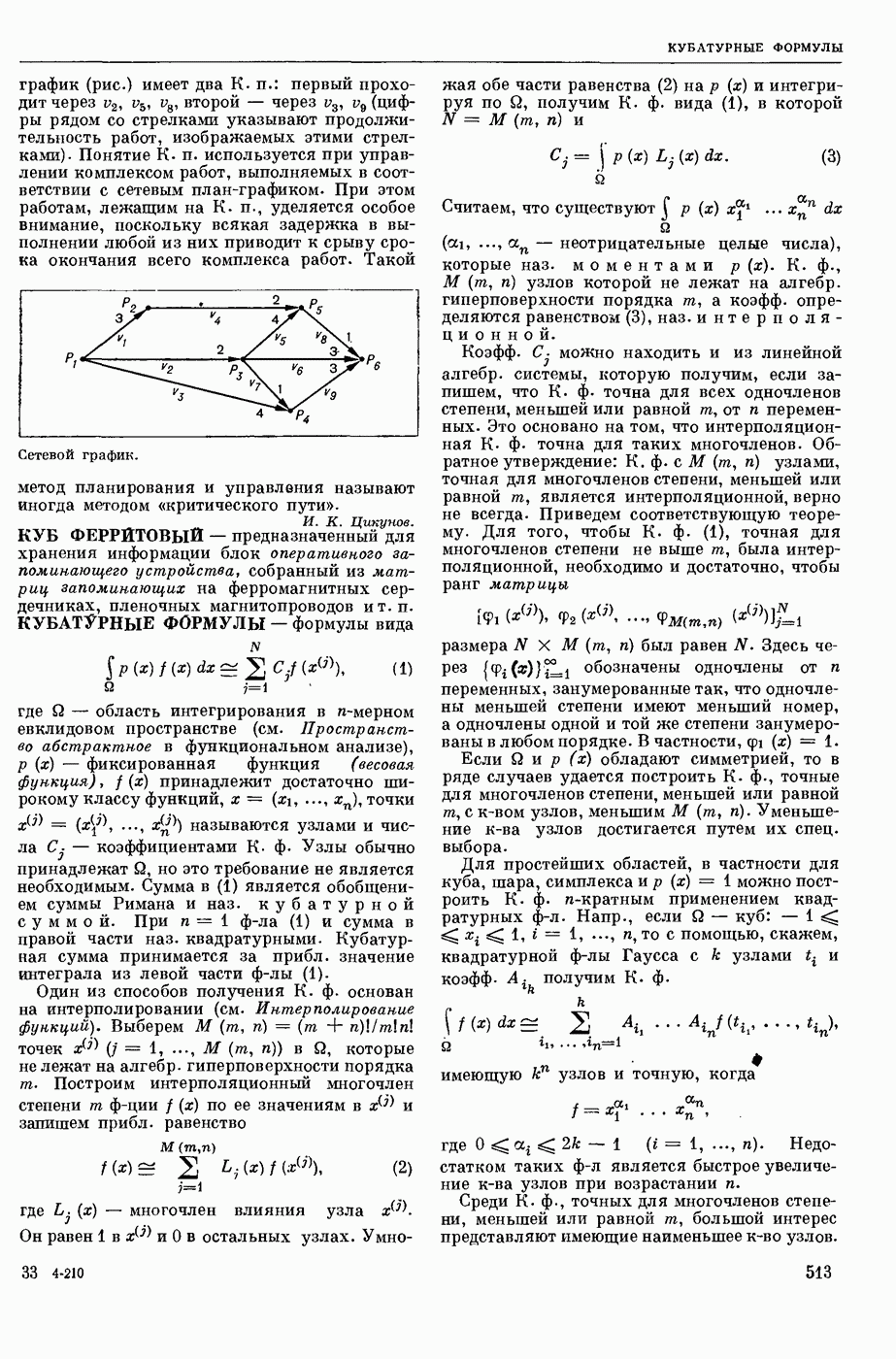
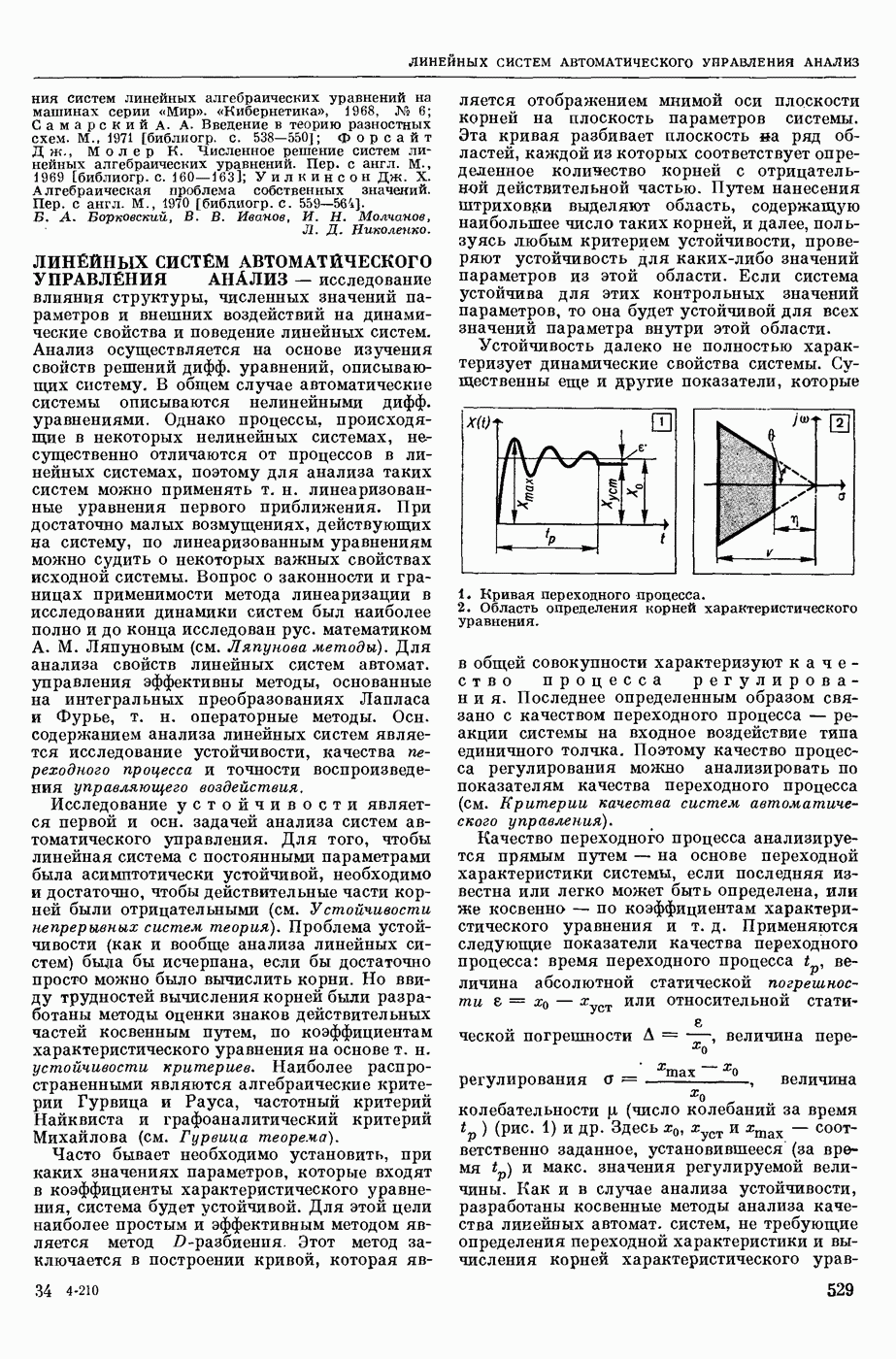
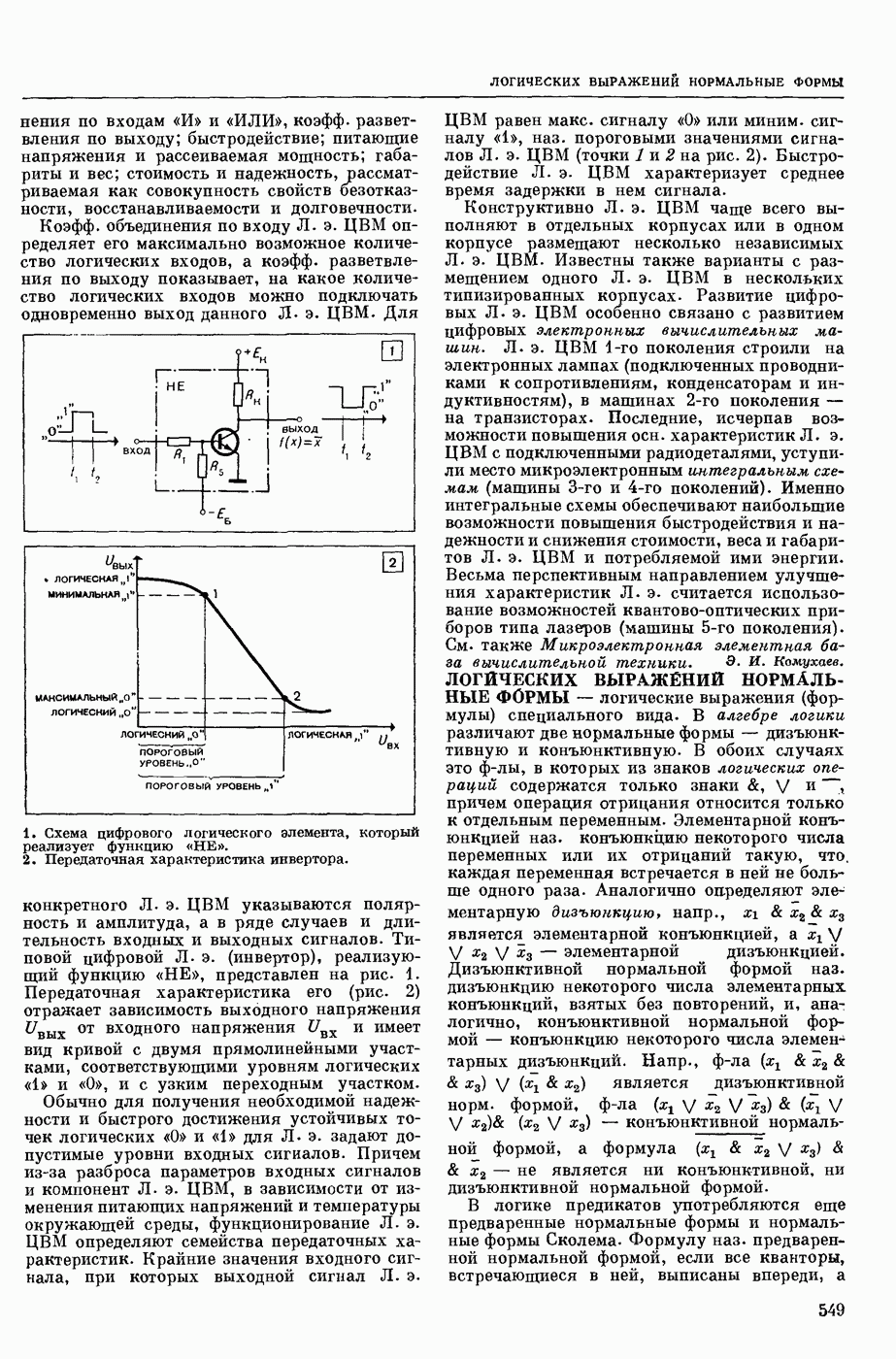
АВТОМАТИЗАЦИЯ ЛИНГВИСТИЧЕСКИХ ИССЛЕДОВАНИЙ
— использование вычислительных машин для лингвистического — преимущественно комбинаторного и статистического — анализа текста как последовательности лингвистических форм.
Сущность лингвистического анализа заключается в том, что на мн-ве лингвистических форм одного уровня (напр., на множестве звуков речи, представленных в тексте буквами, или на мн-ве слов текста) определяются отношения эквивалентности и порядка, ставящие в соответствие каждой форме класс, к которому она принадлежит, и каждой паре в последовательности форм — направление синтаксической связи между ними. Миним. классами форм являются лингвистические единицы — фонемы, конкретными представителями которых являются звуки речи, морфемы (миним. значимые единицы языка), представляемые в тексте морфами (миним. значимыми частями слов), лексемы, представляемые в тексте словоформами, модели словосочетаний и модели предложений. На множестве лингвистических единиц могут быть вновь определены отношения эквивалентности и получены классы лингвистических единиц, такие, как гласные и согласные фонемы, служебные и знаменательные морфемы, имена и глаголы и т. п., и вновь определены отношения порядка. Такие процедуры лингвистического анализа имеют алгоритмический характер и опираются в большой степени на информацию о совместной встречаемости лингвистических форм в текстах. При этом учитывается не только информация о составе лингвистических форм в окружения, но и условная частота появления одних форм при условии появления других. Одна из типичных задач автоматического лингвистического анализа состоит в переводе текста, заданного как последовательность знаков алфавита, в последовательность лингвистических форм заданного уровня, в отождествлении различных употреблений одной и той же формы, в построении классов лингвистических форм и единиц.
В зависимости от того, предшествует ли автомат. обработке текста обработка его человеком или нет, различают полуавтоматический и автоматический анализ. При полуавтоматическом анализе текст заранее членится на формы заданного уровня (напр., на слова) и раждая форма снабжается набором признаков, в котором указывается принадлежность этой формы к определенному классу форм и его подклассам и связь этой формы с другими формами текста. Проанализированный таким образом лингвистом текст переносится на носители информации (перфокарты, перфоленты) и поступает на обработку в ЦВМ. Обычными задачами такой обработки являются: 1) отождествление индивидуальных формоупотреблений внутри каждого из классов форм или единиц; 2) подсчет числа тождественных или эквивалентных формоупотреблений; 3) подсчет условной частоты совместной встречаемости форм или единиц, или классов единиц; 4) построение инвентарей лингвистических форм, единиц и классов; 5) структурный и лингвостатистический анализ инвентарей (см. Лингвистическая статистика) и др. Различаются следующие виды инвентарей: инвентари фонем и графем (букв) и их сочетаний, инвентари слогов, морфов и морфем, а иногда — и основ слов; инвентари словоформ и лексем [списки (индексы) слов, словари частотные]; инвентари словосочетаний.
В случае, если предварительной обработки текста лингвист не производит, говорят об автоматическом анализе. В частности, автоматический анализ является осн. частью машинной дешифровки письменностей (см. Дешифровка текстов). Автоматический лингвистический анализ производится либо путем сравнения форм и их окружений в тексте с заданными в таблицах эталонами, которым сопоставлены наборы признаков, либо методами комбинаторного или комбинаторно-статистического анализа совместных встречаемостей форм. В последнем случае он базируется на предположении о том, что статистически значимые отклонения частот совместной встречаемости форм от матем. ожиданий, вычисленных в предположении об их случайном совместном появлении в тексте, свидетельствуют об определенной близости этих форм. Таким образом удается установить морфологические типы форм, синтаксические структуры и семантические группы (поля). Автоматический анализ переводимого текста является первым этапом машинного перевода.
Кроме задач, связанных непосредственно с лингвистическим анализом текстов, ЦВМ используют как средство автоматизации труда лингвиста, напр., при каталогизации лингвистических явлений, требующей сортировки и подсчета числа явлений по группе признаков. Как правило, машины используют в лингвистических исследованиях, связанных с обработкой больших массивов лингвистической информации, насчитывающих сотни тысяч формоупотреблений. При этом часто собственно лингвистический - анализ сопровождается вычислением различных статистик (частоты форм, единиц и классов, длины форм — слов, предложений), проверкой статистических гипотез о равенстве вероятностей, с которыми одни и те же формы, единицы или классы употребляются в различных текстах, гипотез о наличии корреляций между частотами форм в разных текстах. С помощью ЦВМ решаются также собственно лингвостатистические задачи, связанные с изучением механизма функционирования языка в статистическом аспекте, — изучение функций распределения лингвистических статистик в словаре и в тексте.
Лит.: Шайкевич А. Я. Распределение слов в тексте и выделение семантических полей. В кн.: Иностранные языки в высшей школе, в. 2. М., 1963; Фрумкина Р. М. Автоматизация исследовательских работ в лексикологии и лексикографии. «Вопросы нзыковнания», 1964, N 2; Автоматизация в лингвистике. М. П., 1966; Засорина П. Н. Автоматизация и статистика в лексикографии. П., 1966; Москович В. А. Автоматизация некоторых аспектов лингвистической работы. «Вопросы языкознания», 1966, М 1; Севбо И. П. Структура связного текста и автоматизация реферирования. М., 1969; Перебийнiс B.C. Кшьгасш та  характеристики системи фонем
характеристики системи фонем  мови. К., 1970. В. М. Андрющенко.
мови. К., 1970. В. М. Андрющенко.