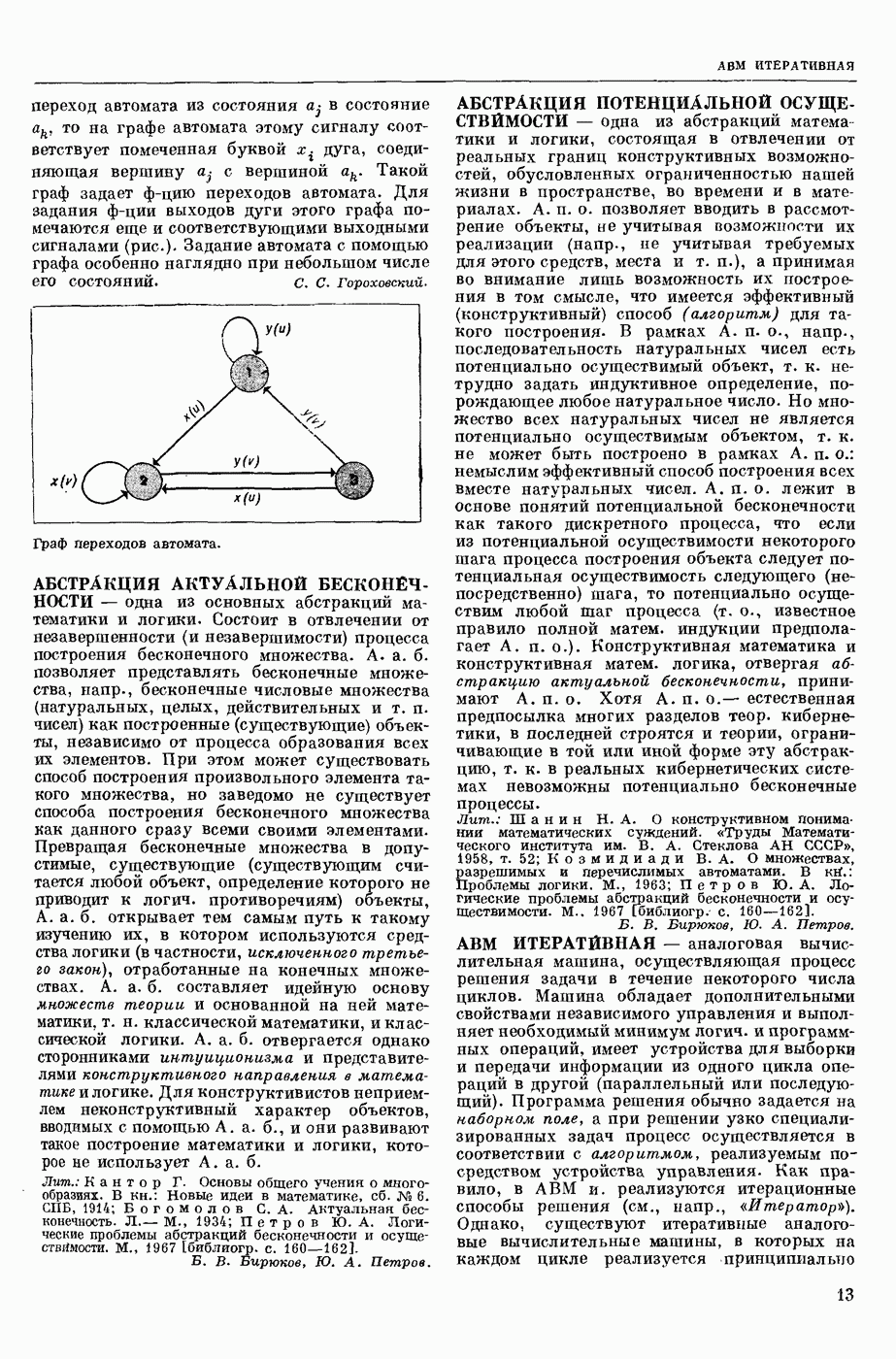
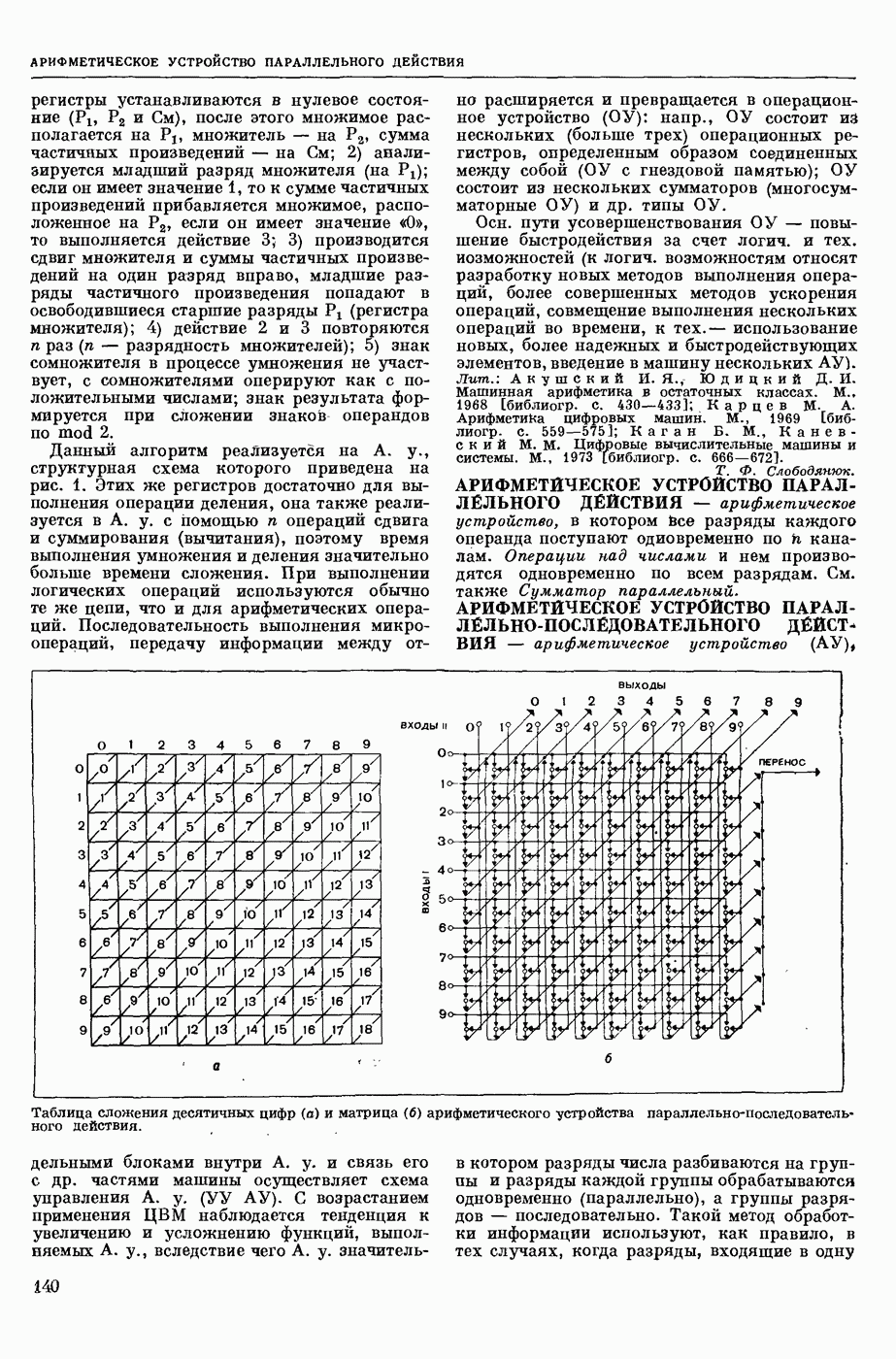
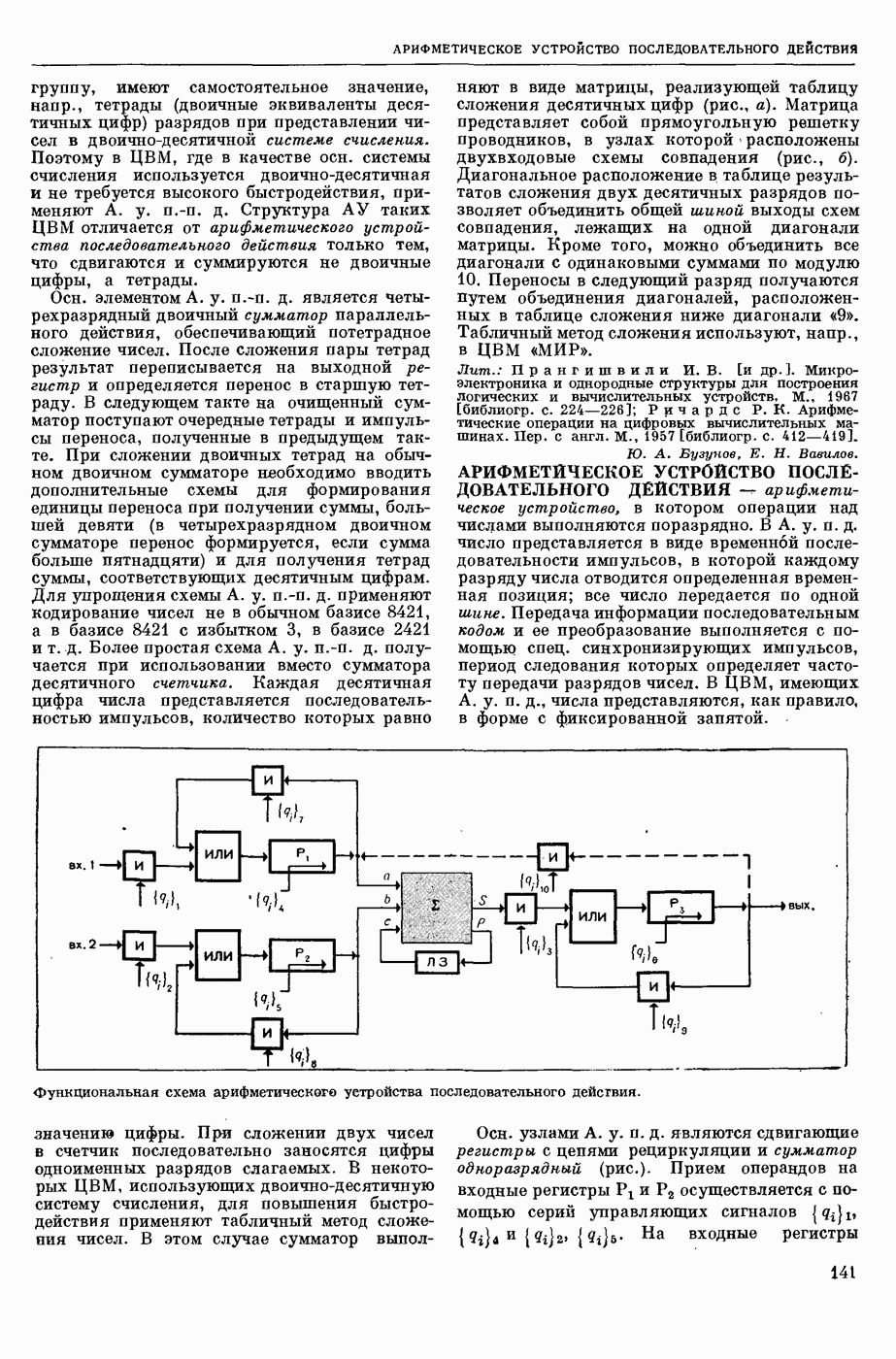
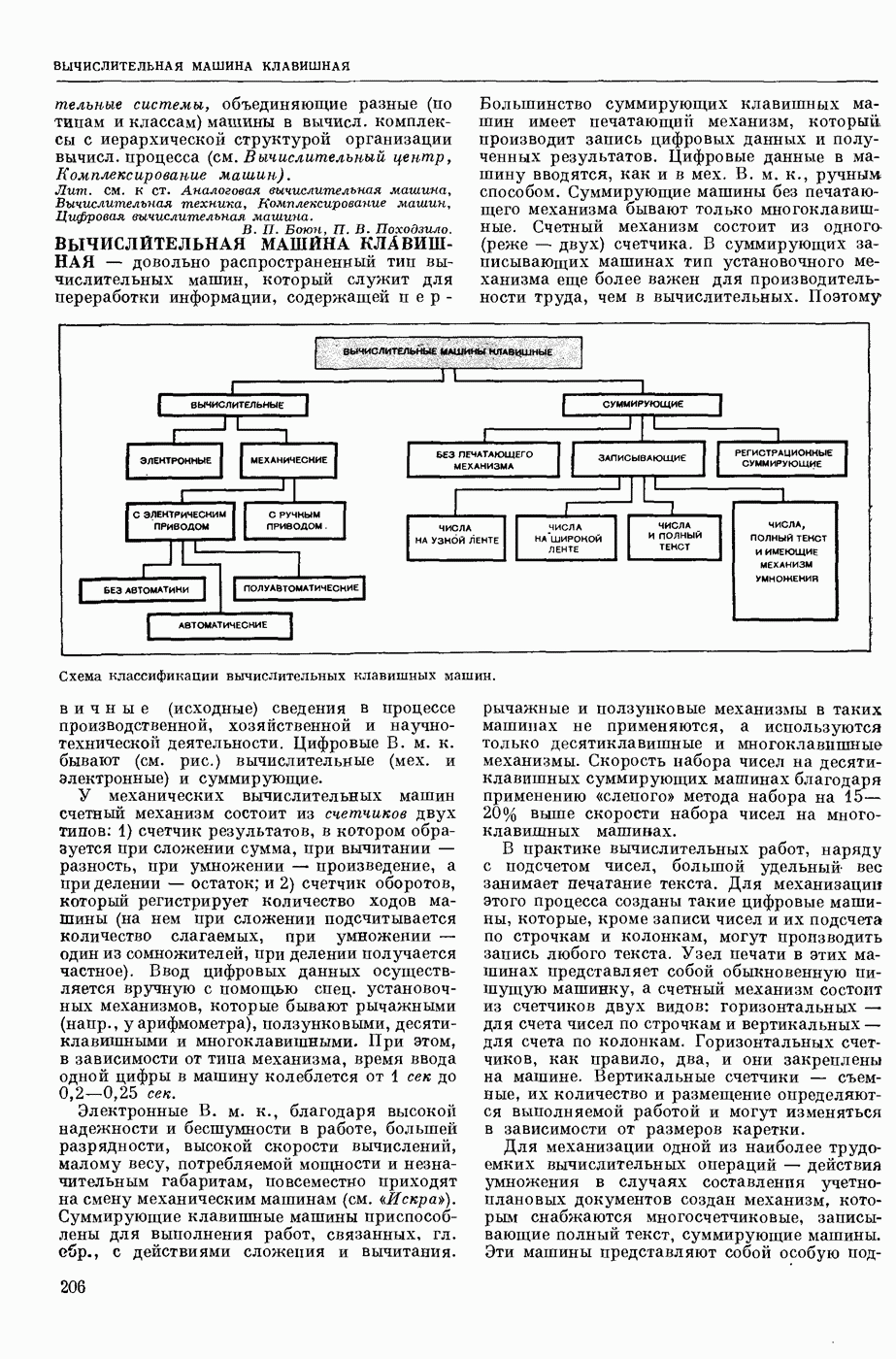
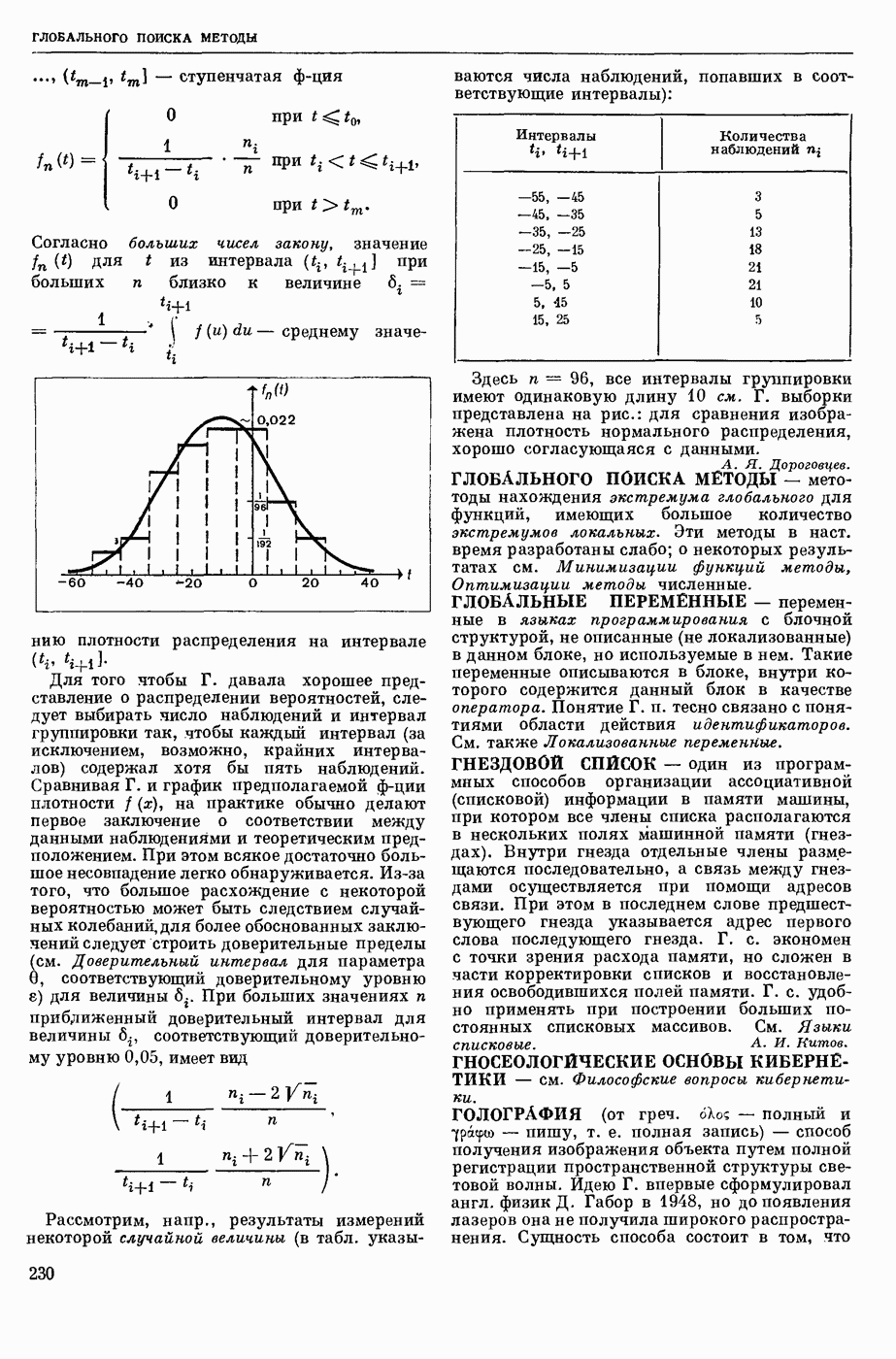
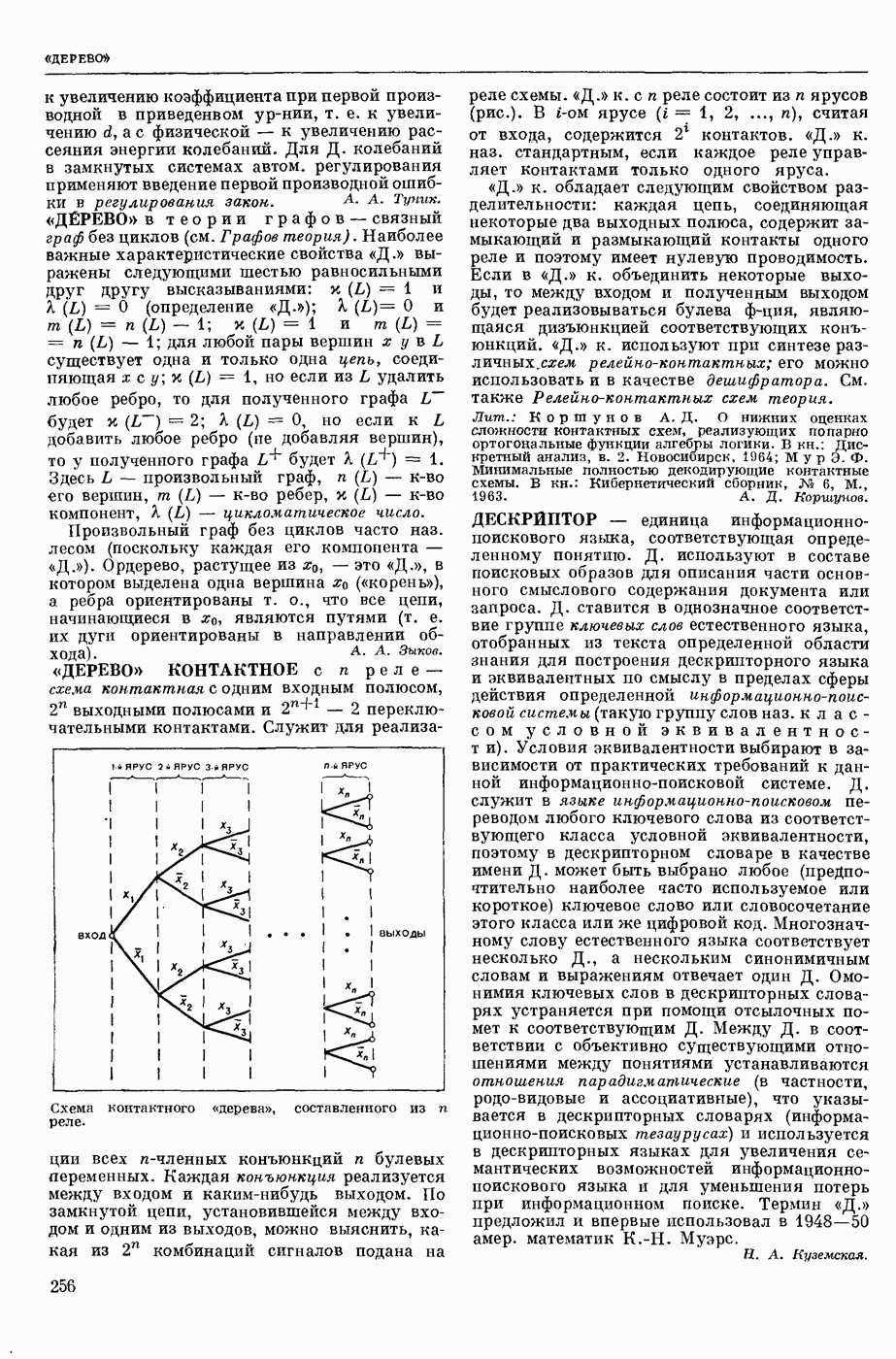
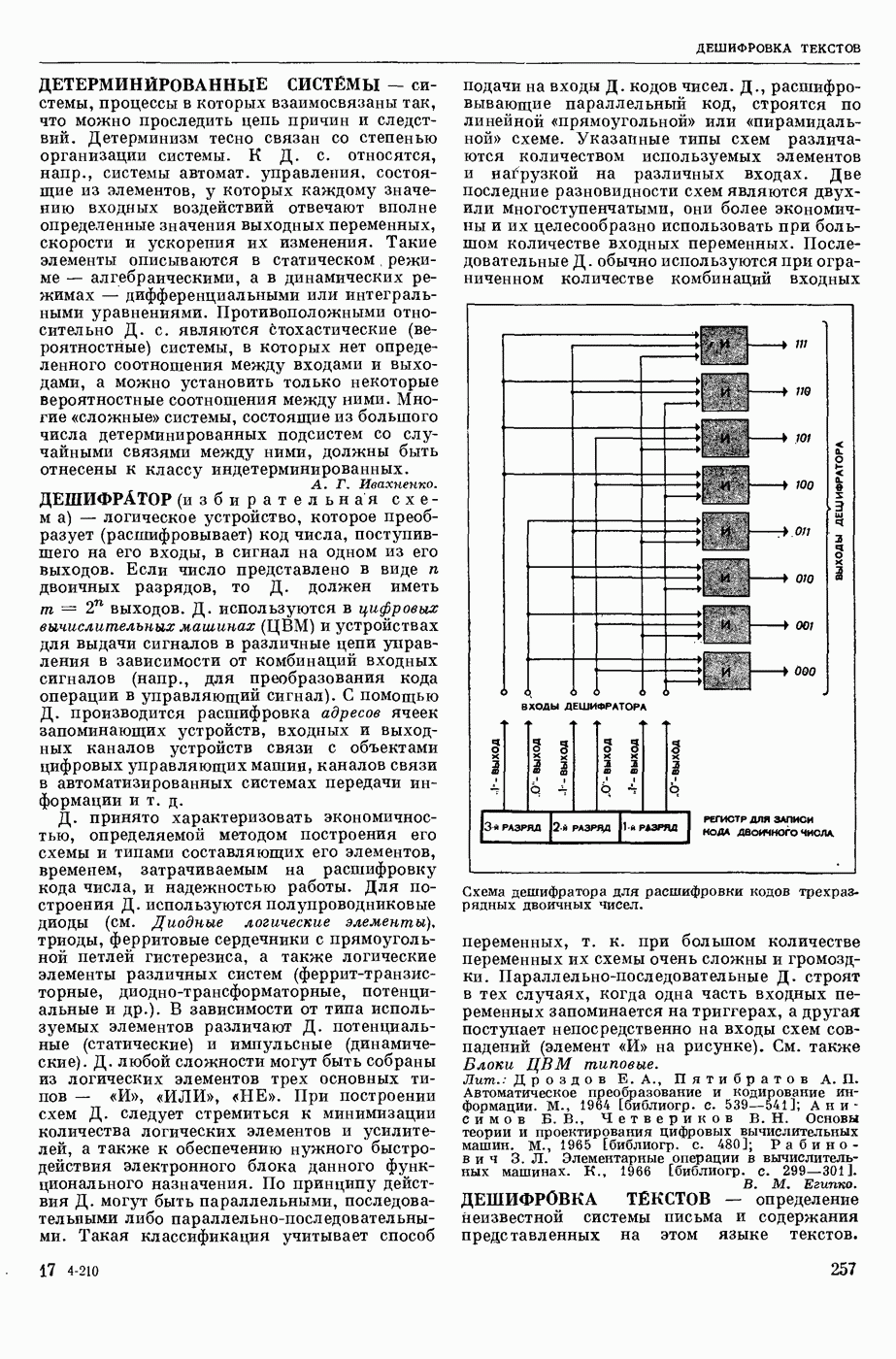
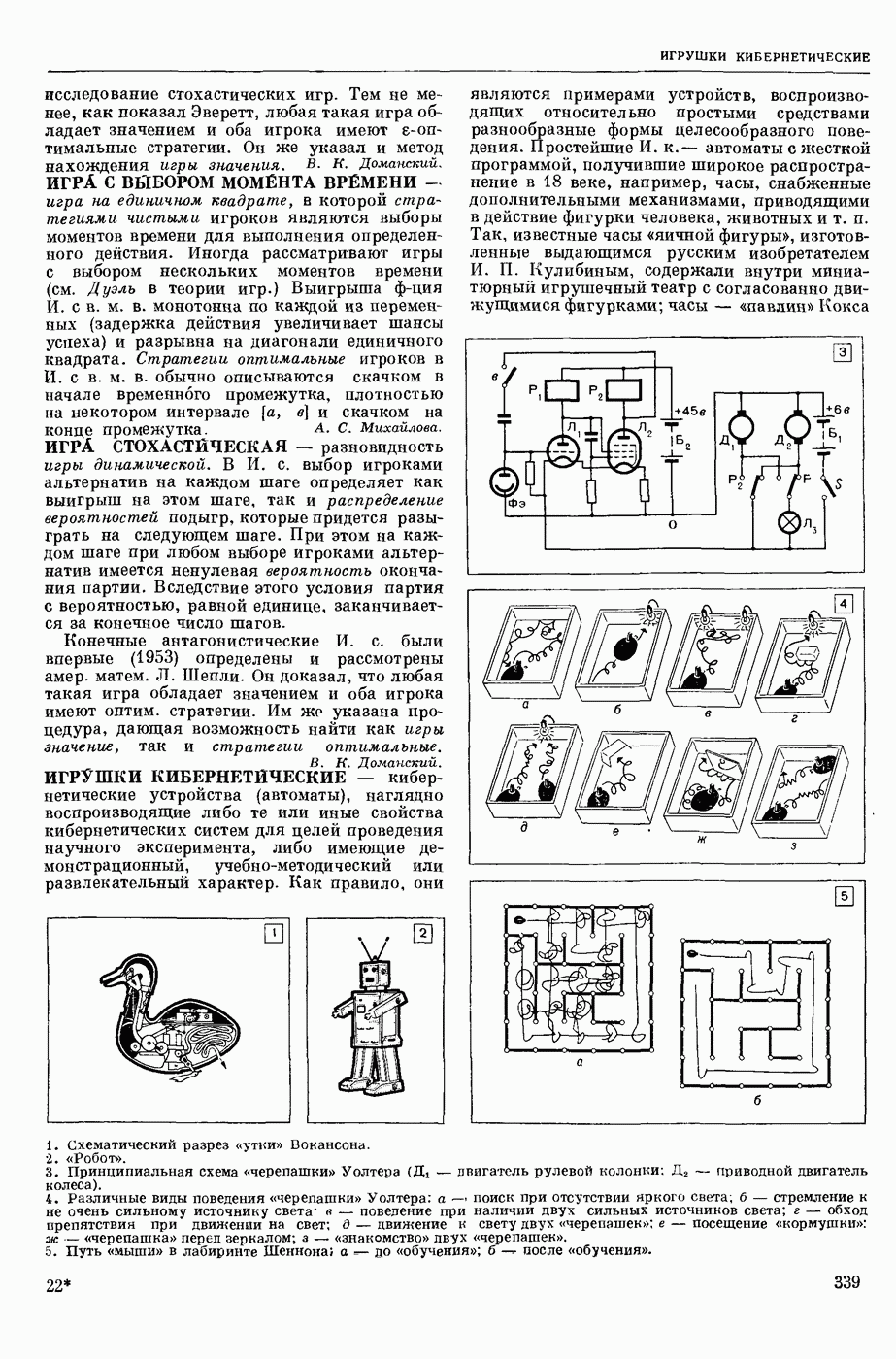
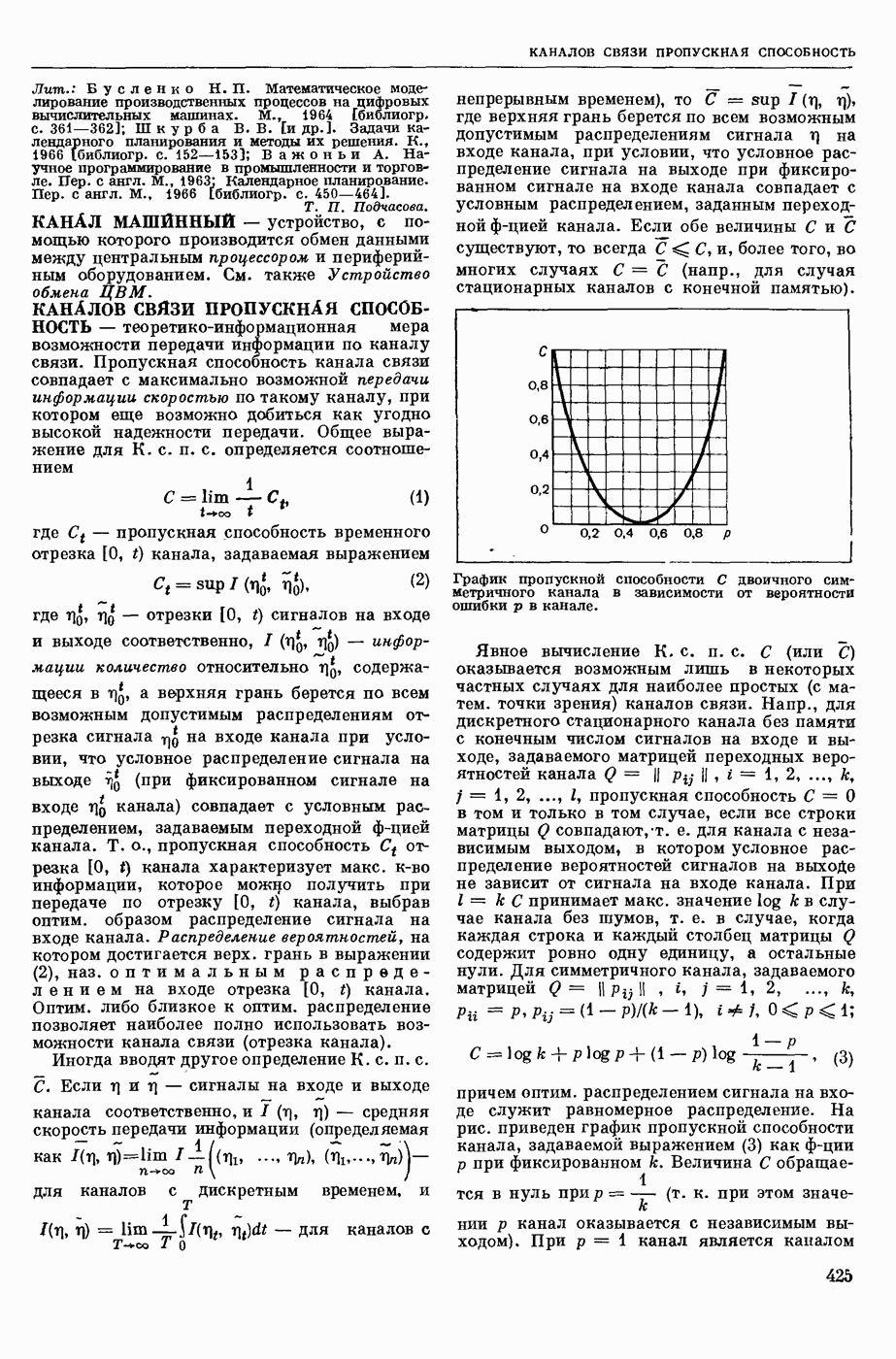
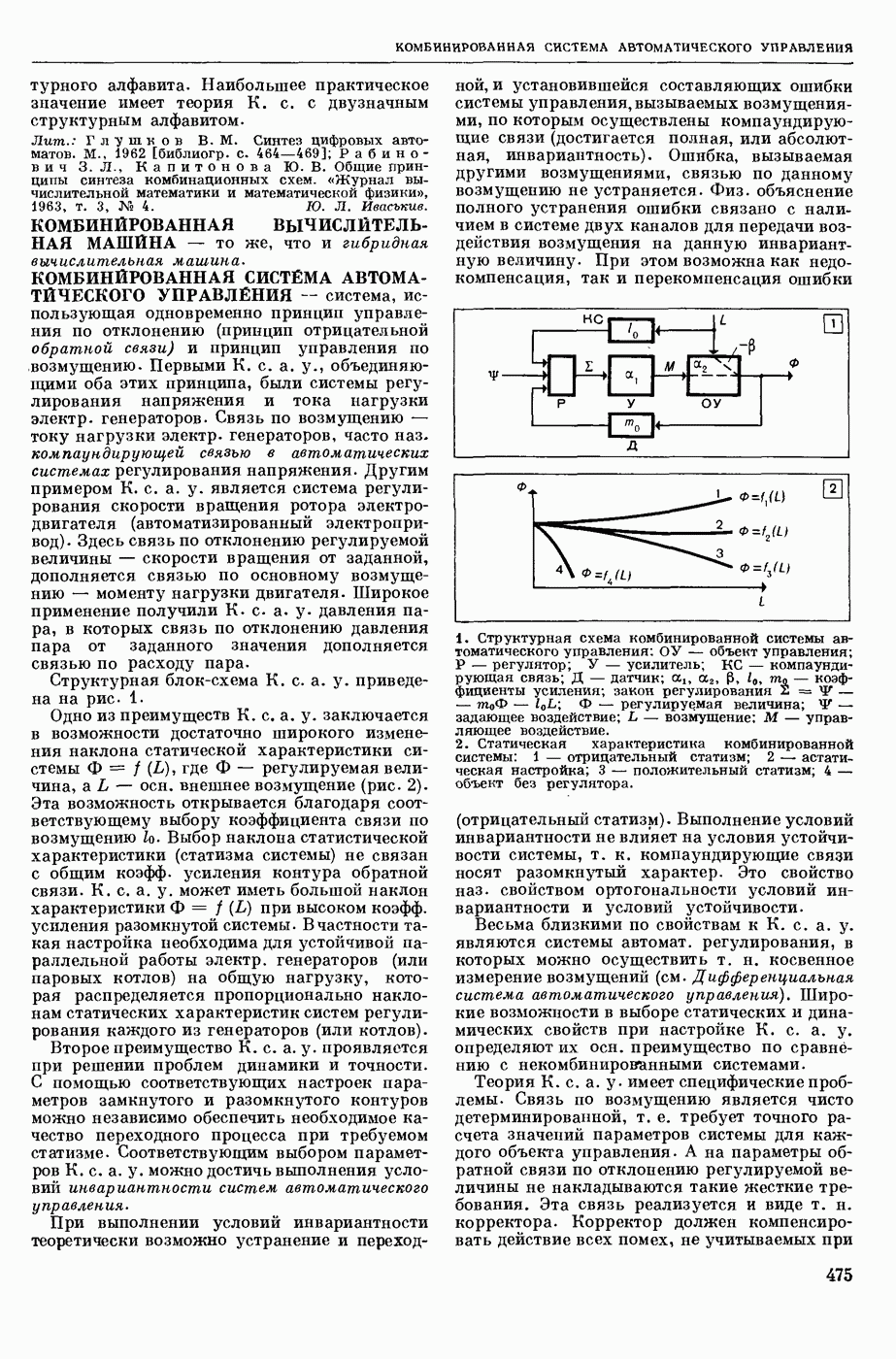
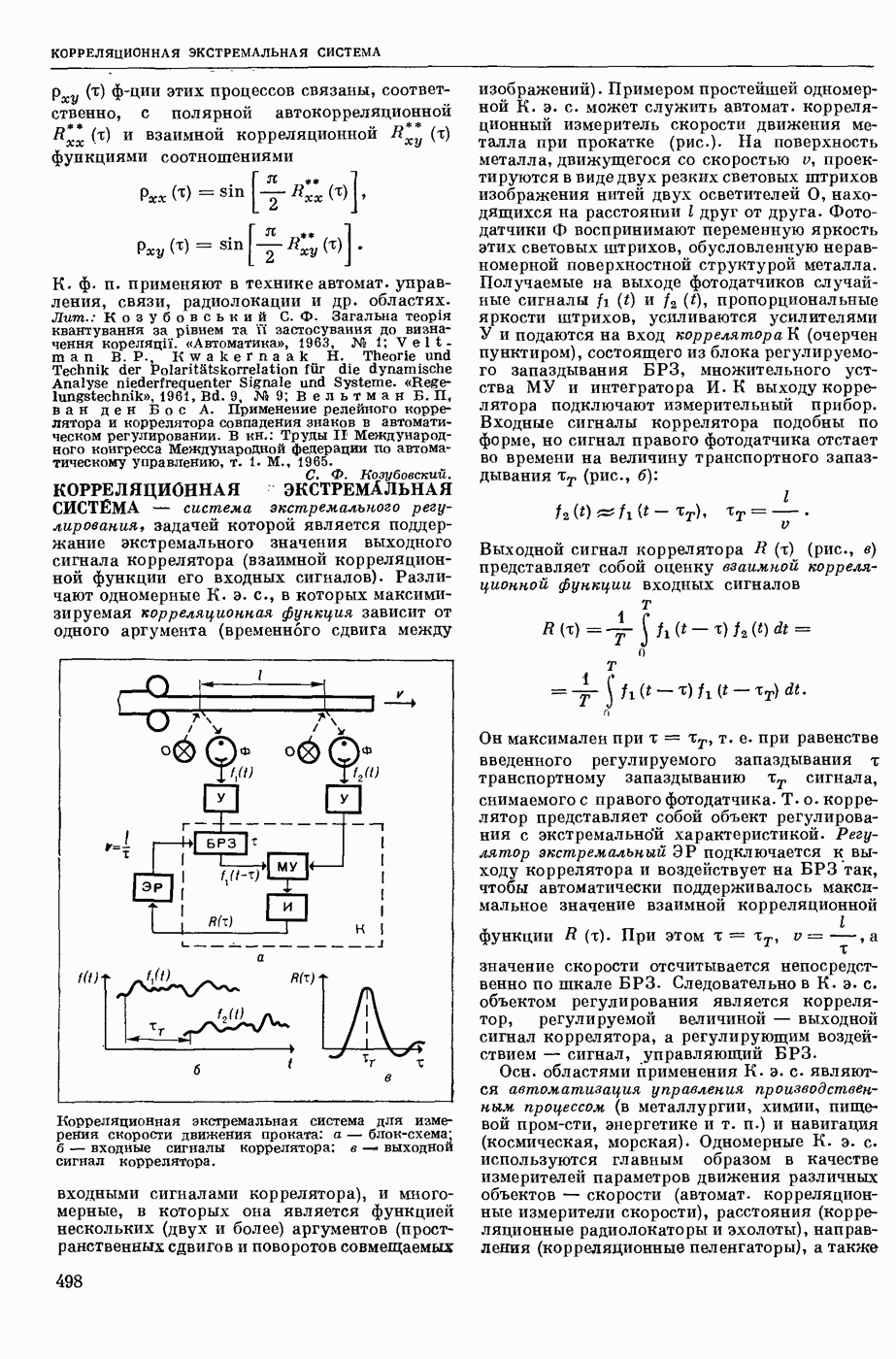
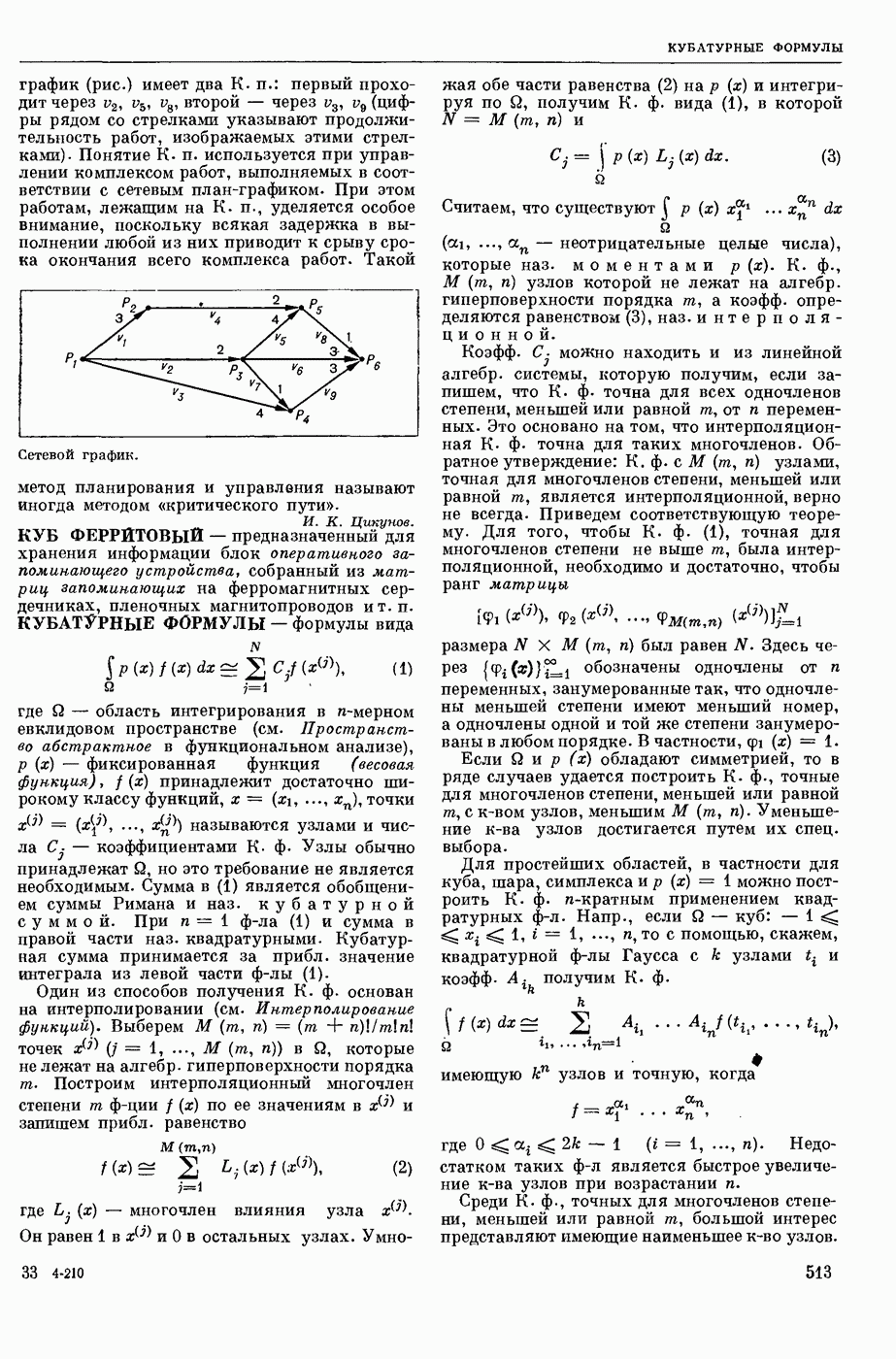
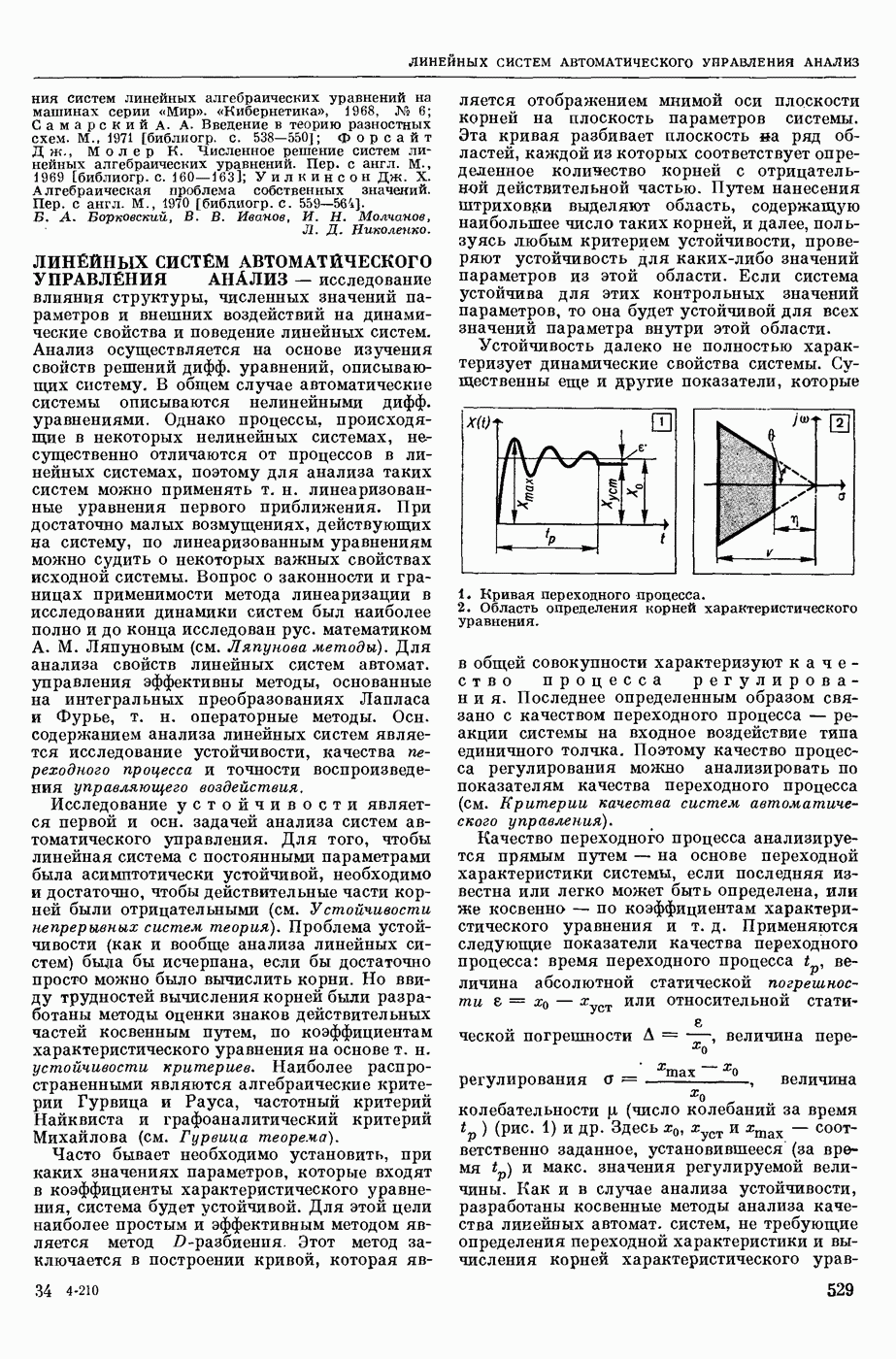
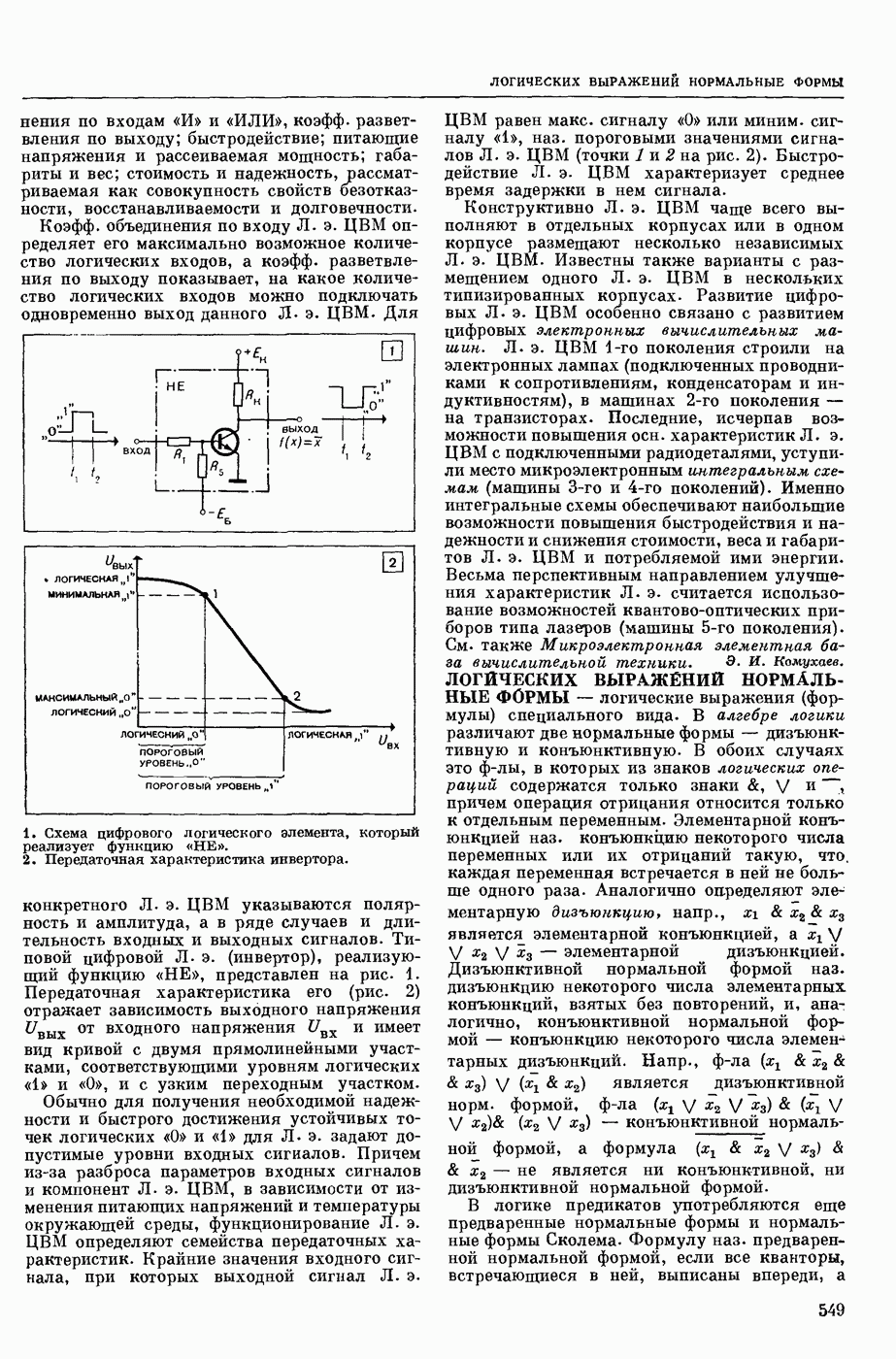
КОДИРОВАНИЕ АВТОМАТНОЕ
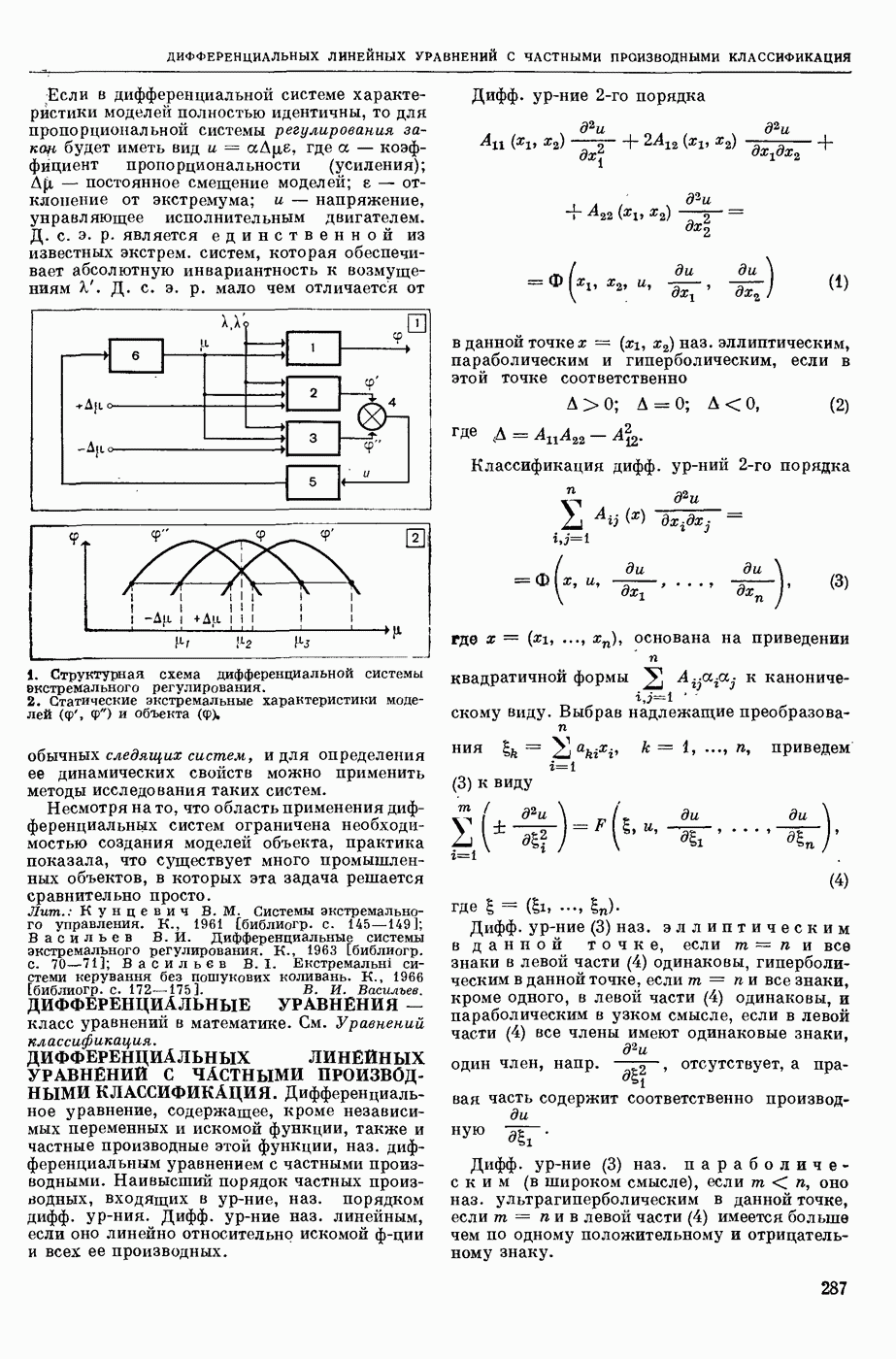
— кодирование, описываемое с помощью обобщенного конечного автомата, выход которого в каждый момент времени есть некоторое, быть может, пустое слово в выходном алфавите. Большинство задач теории кодирования укладывается в следующую схему: рассматривается класс автоматных кодирований, обладающих определенными свойствами; требуется построить кодирование из рассматриваемого класса, оптимальное в некотором заранее заданном смысле. Обычно критерий оптимальности кодирования так или иначе связан с минимизацией длин выходных слов, в то время как требуемые свойства кодирования могут быть весьма разнообразными. Такими свойствами могут быть существование однозначного обратного отображения (декодирования), возможность исправления при декодировании ошибок различного типа, возможность простой тех. реализации кодирования и декодирования и т. п.
Основы кодирования теории заложил амер. ученый К. Э. Шеннон (р. 1916). Наиболее полно исследованы К. а. с одним состоянием, называемые алфавитными кодированиями. При алфавитном кодировании Ф каждой букве входного алфавита  ставится в соответствие некоторое слово
ставится в соответствие некоторое слово  в выходном алфавите
в выходном алфавите  . Произвольное входное слово (сообщение)
. Произвольное входное слово (сообщение)  отображается в слово
отображается в слово  в алфавите ВТ. Мн-во
в алфавите ВТ. Мн-во  кодом.
кодом.
Код  разделимым, если из любого равенства
разделимым, если из любого равенства  в алфавите
в алфавите  следует, что
следует, что  п. Разделимость кода равносильна взаимной однозначности алфавитного кодирования ф. В частности, код является разделимым, если никакое кодовое слово не является
п. Разделимость кода равносильна взаимной однозначности алфавитного кодирования ф. В частности, код является разделимым, если никакое кодовое слово не является  Такие коды (и соответствующие им алфавитные кодирования) наз. префиксными. Существуют разделимые, но не префиксные коды. Для любого разделимого кода
Такие коды (и соответствующие им алфавитные кодирования) наз. префиксными. Существуют разделимые, но не префиксные коды. Для любого разделимого кода  в алфавите
в алфавите  выполняется неравенство
выполняется неравенство

где  - длина слова
- длина слова  . Справедливо и обратное: если
. Справедливо и обратное: если  набор целых положительных чисел, для которых выполняется приведенное выше неравенство, то в алфавите
набор целых положительных чисел, для которых выполняется приведенное выше неравенство, то в алфавите  существует префиксный код
существует префиксный код  в котором слово V. имеет длину
в котором слово V. имеет длину  . Если числа I. упорядочены по возрастанию, то, согласно Шеннону, в качестве слова v. можно взять первые после запятой I. символов
. Если числа I. упорядочены по возрастанию, то, согласно Шеннону, в качестве слова v. можно взять первые после запятой I. символов
разложения числа  бесконечную
бесконечную  -ичную дробь. Код
-ичную дробь. Код  сильно разделимым, если из любого равенства
сильно разделимым, если из любого равенства  бесконечных последовательностей в
бесконечных последовательностей в  следует, что
следует, что  Простейшим примером разделимого, но не сильно разделимого кода является код
Простейшим примером разделимого, но не сильно разделимого кода является код  . Автомат
. Автомат  со входным алфавитом
со входным алфавитом  и выходным
и выходным  декодирующим для алфавитного кодирования
декодирующим для алфавитного кодирования  если существует такое число t, что автомат
если существует такое число t, что автомат  выдает каждое слово а.
выдает каждое слово а.  а; через t тактов после того, как в него поступило слово
а; через t тактов после того, как в него поступило слово 
Для алфавитного кодирования  существует декодирующий автомат тогда и только тогда, когда код является сильно разделимым. Код
существует декодирующий автомат тогда и только тогда, когда код является сильно разделимым. Код  вполне разделимым, если в алфавите
вполне разделимым, если в алфавите  невозможны равенства вида
невозможны равенства вида  где Р — непустое начало слова
где Р — непустое начало слова  отличное от
отличное от  Для алфавитного кодирования
Для алфавитного кодирования  существует дефинитный декодирующий автомат тогда и только тогда, когда код V является вполне разделимым. Автомат дефинитный позволяет в течение ограниченного времени устранить влияние сбоев во входной последовательности или в работе самого автомата. Для распознавания указанных свойств кода
существует дефинитный декодирующий автомат тогда и только тогда, когда код V является вполне разделимым. Автомат дефинитный позволяет в течение ограниченного времени устранить влияние сбоев во входной последовательности или в работе самого автомата. Для распознавания указанных свойств кода  строится вспомогательный граф, вершины которого — непустые слова, являющиеся и началами, и окончаниями некоторых кодовых слов. При этом вершина
строится вспомогательный граф, вершины которого — непустые слова, являющиеся и началами, и окончаниями некоторых кодовых слов. При этом вершина  соединяется с Р ребром, направленным от
соединяется с Р ребром, направленным от  к
к  если существует кодовое слово v. такое, что
если существует кодовое слово v. такое, что  или
или  Построение завершается объединением всех вершин, соответствующих кодовым словам, в одну общую вершину, обозначаемую символом
Построение завершается объединением всех вершин, соответствующих кодовым словам, в одну общую вершину, обозначаемую символом  . Код V является: 1) разделимым, 2) сильно разделимым или 3) вполне разделимым тогда и только тогда, когда в построенном графе нет соответственно: 1) ориентированных циклов, проходящих через вершину
. Код V является: 1) разделимым, 2) сильно разделимым или 3) вполне разделимым тогда и только тогда, когда в построенном графе нет соответственно: 1) ориентированных циклов, проходящих через вершину  ; 2) ориентированных циклов, в которые можно попасть из вершины
; 2) ориентированных циклов, в которые можно попасть из вершины  ; 3) никаких ориентированных циклов.
; 3) никаких ориентированных циклов.
Наиболее законченные результаты в теории кодирования связаны с построением кодов, обладающих миним. избыточностью при заданных значениях свободных параметров. Предложенные конструкции используются на практике при сжатии информации и выборке её из памяти. В простейшем варианте задачи предполагается, что последовательные появления букв входного алфавита  статистически независимы и подчинены некоторому распределению вероятностей
статистически независимы и подчинены некоторому распределению вероятностей 
Каждое К. а.  характеризуется средним числом (Р) букв выходного алфавита
характеризуется средним числом (Р) букв выходного алфавита  приходящихся на одну букву входного алфавита
приходящихся на одну букву входного алфавита  Для алфавитного кодирования
Для алфавитного кодирования  , где — длина слова
, где — длина слова  в алфавите ВТ. Если К. а.
в алфавите ВТ. Если К. а.  является взаимно однозначным, то
является взаимно однозначным, то 
Величина  избыточностью кодирования
избыточностью кодирования  при распределении Р. Задача состоит в отыскании в заданном классе взаимно однозначных кодирований кодирования, обладающего миним. избыточностью. Так как при
при распределении Р. Задача состоит в отыскании в заданном классе взаимно однозначных кодирований кодирования, обладающего миним. избыточностью. Так как при  выполняется неравенство (1), то по методу Шеннона можно построить алфавитное префиксное кодирование с избыточностью, меньше единицы (здесь и далее
выполняется неравенство (1), то по методу Шеннона можно построить алфавитное префиксное кодирование с избыточностью, меньше единицы (здесь и далее  наименьшее целое, не меньше числа
наименьшее целое, не меньше числа  целая часть числа
целая часть числа  т. е. наибольшее целое, не превышающее числа
т. е. наибольшее целое, не превышающее числа  ).
).
Одним из осн. достижений теории кодирования является метод Хаффмена построения префиксного алфавитного кодирования, имеющего миним. избыточность в классе всех взаимно однозначных алфавитных кодирований. Существенного уменьшения избыточности можно достичь, разбивая сообщения на блоки длины к и используя алфавитное кодирование  этих
этих  блоков. Методами Шеннона или Хаффмена можно построить префиксное кодирование
блоков. Методами Шеннона или Хаффмена можно построить префиксное кодирование  блоков длины к такое, что
блоков длины к такое, что  причем эта оценка не может быть улучшена по порядку (при к
причем эта оценка не может быть улучшена по порядку (при к  ) ни для какого распределения Р, кроме распределения, при котором все числа
) ни для какого распределения Р, кроме распределения, при котором все числа  являются целыми. Методы Шеннона и Хаффмена применимы в том случае, когда известно распределение вероятностей. Для случая неизвестных вероятностей доказано, что существует префиксное кодирование
являются целыми. Методы Шеннона и Хаффмена применимы в том случае, когда известно распределение вероятностей. Для случая неизвестных вероятностей доказано, что существует префиксное кодирование  блоков длины к такое, что для любого распределения вероятностей Р имеет место
блоков длины к такое, что для любого распределения вероятностей Р имеет место  где с — некоторая величина, не зависящая от к. С другой стороны, установлено, что для любого префиксного кодирования
где с — некоторая величина, не зависящая от к. С другой стороны, установлено, что для любого префиксного кодирования  блоков длины к существует распределение Р такое, что
блоков длины к существует распределение Р такое, что  где d — некоторая величина, не зависящая от к.
где d — некоторая величина, не зависящая от к.
Большинство работ, относящихся к теории кодирования, посвящено задаче построения
кодов, допускающих исправление ошибок (см. Коды корректирующие). Были исследованы преимущественно т. н. блочные коды, являющиеся подмножествами мн-ва  всех слов длины
всех слов длины  в алфавите
в алфавите  При этом оказалось удобным рассматривать алфавит
При этом оказалось удобным рассматривать алфавит  как кольцо вычетов по
как кольцо вычетов по  или как поле Галуа
или как поле Галуа  если
если  является степенью простого числа, а мн-во В рассматривать как
является степенью простого числа, а мн-во В рассматривать как  -мерное векторное пространство над
-мерное векторное пространство над  Код
Код  наз. линейным, если он образует линейное подпространство размерности к в пространстве
наз. линейным, если он образует линейное подпространство размерности к в пространстве  Под ошибкой типа замещения (или просто ошибкой) понимается случайный переход одной буквы алфавита
Под ошибкой типа замещения (или просто ошибкой) понимается случайный переход одной буквы алфавита  другую. В пространстве
другую. В пространстве  вводится метрика Хемминга, как число координат, в которых два вектора различаются, или, что то же самое, как миним. число ошибок, переводящих один вектор в другой. Каждый код
вводится метрика Хемминга, как число координат, в которых два вектора различаются, или, что то же самое, как миним. число ошибок, переводящих один вектор в другой. Каждый код  характеризуется параметрами:
характеризуется параметрами:  — длина кода,
— длина кода,  — основание кода, m — число векторов кода, к — размерность линейного кода и d — кодовое расстояние, равное минимуму расстояний между различными векторами кода. Имеется возможность исправить t или менее ошибок в каждом векторе, принадлежащем коду V, тогда и только тогда, когда
— основание кода, m — число векторов кода, к — размерность линейного кода и d — кодовое расстояние, равное минимуму расстояний между различными векторами кода. Имеется возможность исправить t или менее ошибок в каждом векторе, принадлежащем коду V, тогда и только тогда, когда  Избыточность алфавитного кодирования с помощью кода
Избыточность алфавитного кодирования с помощью кода  равновероятных входных буквах) характеризуется величиной
равновероятных входных буквах) характеризуется величиной  . Поэтому при построении кода с заданным числом исправляемых ошибок желательно минимизировать длину
. Поэтому при построении кода с заданным числом исправляемых ошибок желательно минимизировать длину  и максимизировать число элементов m (или размерность к в случае линейных кодов). Код, обладающий макс. числом элементов при заданных значениях остальных параметров, наз. максимальным.
и максимизировать число элементов m (или размерность к в случае линейных кодов). Код, обладающий макс. числом элементов при заданных значениях остальных параметров, наз. максимальным.
Примером кодов для исправления одиночных ошибок являются двоичные линейные коды Хемминга

где  вектор из 0 и 1, являющийся двоичной записью числа
вектор из 0 и 1, являющийся двоичной записью числа  , т. е. такой, что
, т. е. такой, что 
Коды  обладают параметрами:
обладают параметрами:  — любое,
— любое, 
Вслед за кодами Хемминга были предложены двоичные линейные коды Рида — Маллера порядка h, которые можно определить как мн-во столбцов значений функций алгебры логики от I переменных, которые представимы полиномами степени не выше h. Эти коды обладают параметрами:  допускают мажоритарный способ исправления
допускают мажоритарный способ исправления  ошибок.
ошибок.
Существенный прогресс в построении корректирующих кодов связан с дальнейшей алгебраизацией пространства  в том случае, когда
в том случае, когда  является степенью простого числа (в этом случае вместо
является степенью простого числа (в этом случае вместо  будем писать q). Если каждому вектору
будем писать q). Если каждому вектору  над полем Галуа из
над полем Галуа из  элементов
элементов  поставить в соответствие полином
поставить в соответствие полином  всякий линейный код в
всякий линейный код в  можно рассматривать как подпространство в алгебре полиномов по модулю
можно рассматривать как подпространство в алгебре полиномов по модулю  Код наз. циклическим, если он вместе с каждым вектором содержит все его циклические сдвиги. Линейный код является циклическим тогда и только тогда, когда он образует идеал в алгебре полиномов по модулю
Код наз. циклическим, если он вместе с каждым вектором содержит все его циклические сдвиги. Линейный код является циклическим тогда и только тогда, когда он образует идеал в алгебре полиномов по модулю  . Т. о., каждый линейный циклический код (ЛЦ код) размерности к можно рассматривать как мн-во всех полиномов, кратных в алгебре полиномов по модулю
. Т. о., каждый линейный циклический код (ЛЦ код) размерности к можно рассматривать как мн-во всех полиномов, кратных в алгебре полиномов по модулю  некоторому полиному
некоторому полиному  над
над  степени
степени  . Полином
. Полином  порождающим полиномом кода.
порождающим полиномом кода.
Плодотворным оказался метод построения ЛЦ кодов, основанный на задании корней порождающего полинома, лежащих в некотором расширении поля  . В частности, ЛЦ коды Боуза — Чоудхури — Хоквингема (БЧХ коды) для исправления
. В частности, ЛЦ коды Боуза — Чоудхури — Хоквингема (БЧХ коды) для исправления  ошибок на длине
ошибок на длине  определяются с помощью порождающего полинома, который имеет среди своих корней
определяются с помощью порождающего полинома, который имеет среди своих корней  где
где  первообразный элемент поля
первообразный элемент поля  БЧХ коды обладают параметрами:
БЧХ коды обладают параметрами:  если
если  или к
или к  если
если  . При
. При  эти коды (называемые кодами Рида — Соломона) максимальны при любом t, а при
эти коды (называемые кодами Рида — Соломона) максимальны при любом t, а при  и
и  они являются циклическими аналогами макс. кодов Хемминга длины
они являются циклическими аналогами макс. кодов Хемминга длины 
Циклические аналоги кодов Рида — Маллера (ЦРМ коды) порядка h с длиной  определяются с помощью порождающего полинома, который ймеет в качестве своих корней все степени
определяются с помощью порождающего полинома, который ймеет в качестве своих корней все степени  первообразного элемента g поля
первообразного элемента g поля  такие, что сумма цифр в
такие, что сумма цифр в  -ичном представлении числа j меньше
-ичном представлении числа j меньше  Эти коды имеют параметры:
Эти коды имеют параметры:


где  число упорядоченных разбиений числа
число упорядоченных разбиений числа  на I целых неотрицательных слагаемых, каждое из которых не превышает
на I целых неотрицательных слагаемых, каждое из которых не превышает  . В частности, ЦРМ код 1-го порядка имеет параметры:
. В частности, ЦРМ код 1-го порядка имеет параметры:  и является максимальным.
и является максимальным.
Квадратично-вычетными кодами (КВ кодами) наз. двоичные ЛЦ коды простой длины  , где
, где  порождающий полином которых имеет корни где
порождающий полином которых имеет корни где  первообразный корень степени
первообразный корень степени  из единицы, а
из единицы, а  квадратичный вычет по
квадратичный вычет по  . Размерность
. Размерность  кодов равна
кодов равна  а кодовое расстояние нечетно и удовлетворяет неравенствам
а кодовое расстояние нечетно и удовлетворяет неравенствам  если
если  если
если  Отметим также двоичные линейные (но не циклические) коды длины
Отметим также двоичные линейные (но не циклические) коды длины  для исправления
для исправления  ошибок, которые определяются с помощью некоторого первообразного элемента
ошибок, которые определяются с помощью некоторого первообразного элемента  поля
поля  и различных элементов
и различных элементов  поля
поля  следующим образом:
следующим образом:  Коды
Коды  обладают параметрами
обладают параметрами  и принадлежат широкому классу линейных кодов.
и принадлежат широкому классу линейных кодов.
Для выяснения вопроса о том, насколько те или иные коды близки и максимальным, разработаны оригинальные методы получения оценок допустимых параметров кодов. В частности, для кодов, исправляющих t ошибок, установлена граница плотной упаковки

которая достигается при  а также при
а также при  Кроме того, доказано, что эта граница при
Кроме того, доказано, что эта граница при  достигается еще лишь для КВ кода
достигается еще лишь для КВ кода  а также для кода с параметрами
а также для кода с параметрами  . В случае, когда число
. В случае, когда число  исправляемых ошибок достаточно мало по сравнению с
исправляемых ошибок достаточно мало по сравнению с  , параметры двоичных БЧХ кодов достаточно близки к границе плотной упаковки. Однако, для кодов, исправляющих фиксированную долю
, параметры двоичных БЧХ кодов достаточно близки к границе плотной упаковки. Однако, для кодов, исправляющих фиксированную долю  ошибок, существенно более сильной (при условии
ошибок, существенно более сильной (при условии  ) является верхняя граница
) является верхняя граница

где 
Наилучшие коды для исправления фиксированной доли ошибок можно построить методом перебора, их параметры удовлетворяют границе

а в случае линейных кодов — границе

Сближение границ (2) и (3) является одной из осн. нерешенных задач теории кодирования.
Параметры кодов для исправления большого числа ошибок удовлетворяют границе

которая достигается для широкого класса кодов, в частности, ЦРМ кодов 1-го порядка. Для произвольных линейных кодов справедлива оценка  , причем для любых
, причем для любых  и d таких,
и d таких,  существует линейный код с параметрами
существует линейный код с параметрами  размерность которого равна наибольшему к, удовлетворяющему этому неравенству.
размерность которого равна наибольшему к, удовлетворяющему этому неравенству.
Наряду с задачей исправления заданного числа ошибок исследовали задачу исправления пачек ошибок длины b, т. е. ошибок типа замещения, происходящих в пределах отрезка из b последовательных символов, а также задачу исправления ошибок других типов. Среди осн. результатов, полученных в этих направлениях, отметим следующие. Если  неприводимый многочлен степени I над
неприводимый многочлен степени I над  , порядок корней которого равен
, порядок корней которого равен  любое целое, которое не делится на s, то ЛЦ код в
любое целое, которое не делится на s, то ЛЦ код в  где
где  с порождающим полиномом
с порождающим полиномом  имеет размерность к
имеет размерность к  и позволяет исправить любую пачку ошибок длины
и позволяет исправить любую пачку ошибок длины 
Двоичный код

позволяет, когда  простое число и 2 или —2 является первообразным корнем по
простое число и 2 или —2 является первообразным корнем по  исправить любую одиночную арифм. ошибку, состоящую в изменении на
исправить любую одиночную арифм. ошибку, состоящую в изменении на  числового значения кодового вектора. Двоичный код
числового значения кодового вектора. Двоичный код

позволяет исправить любую одиночную несимметричную ошибку типа замещения (напр., замену символа 0 символом 1), а также исправить любую одиночную ошибку типа выпадения (или вставки) символа, сопровождающуюся уменьшением (соответственно увеличением) на единицу длины вектора. Коды  близки к максимальным в классе кодов, исправляющих одиночные ошибки указанных типов. Практическое использование кодов с исправлением ошибок затруднено тем, что стремление к уменьшению избыточности кодов, как правило, приводит к увеличению сложности алгоритма декодирования с исправлением ошибок. Это обстоятельство послужило толчком для глубокого исследования возможных алгоритмов декодирования известных кодов с целью упрощения их.
близки к максимальным в классе кодов, исправляющих одиночные ошибки указанных типов. Практическое использование кодов с исправлением ошибок затруднено тем, что стремление к уменьшению избыточности кодов, как правило, приводит к увеличению сложности алгоритма декодирования с исправлением ошибок. Это обстоятельство послужило толчком для глубокого исследования возможных алгоритмов декодирования известных кодов с целью упрощения их.
Велико влияние теории кодирования на решение других задач кибернетики. Известны примеры, когда использование тех или иных кодовых конструкций приводило к существенному продвижению в вопросах, на первый взгляд весьма далеких от традиционных задач теории кодирования. Следует указать на использование кода Хемминга при получении асимптотики миним. числа контактов, достаточного для реализации любой функции алгебры логики от  переменных; на использование неравенства (1) при оценке сложности реализации формулами одного класса функций алгебры логики; на использование кодов с равными расстояниями между векторами для помехоустойчивого кодирования состояний автомата асинхронного и др. Задачи синтеза самокорректирующихся схем контактных и самокорректирующихся схем из функциональных элементов также подсказаны теорией кодирования, причем при построении асимптотически оптимальных самокорректирующихся схем из функциональных элементов использованы коды для исправления ошибок.
переменных; на использование неравенства (1) при оценке сложности реализации формулами одного класса функций алгебры логики; на использование кодов с равными расстояниями между векторами для помехоустойчивого кодирования состояний автомата асинхронного и др. Задачи синтеза самокорректирующихся схем контактных и самокорректирующихся схем из функциональных элементов также подсказаны теорией кодирования, причем при построении асимптотически оптимальных самокорректирующихся схем из функциональных элементов использованы коды для исправления ошибок.
Лит.: Шеннон К. Работы по теории информации и кибернетике. Пер. с англ. М., 1963 [библиогр. с. 783—820]; Питерсон У. Коды, исправляющие ошибки. Пер. с англ. М., 1964 [библиогр. с. 309—316]: Берлекэмп Э. Алгебраическая теория кодирования. Пер. с англ. М., 1971 [библиогр. с. 449—460].