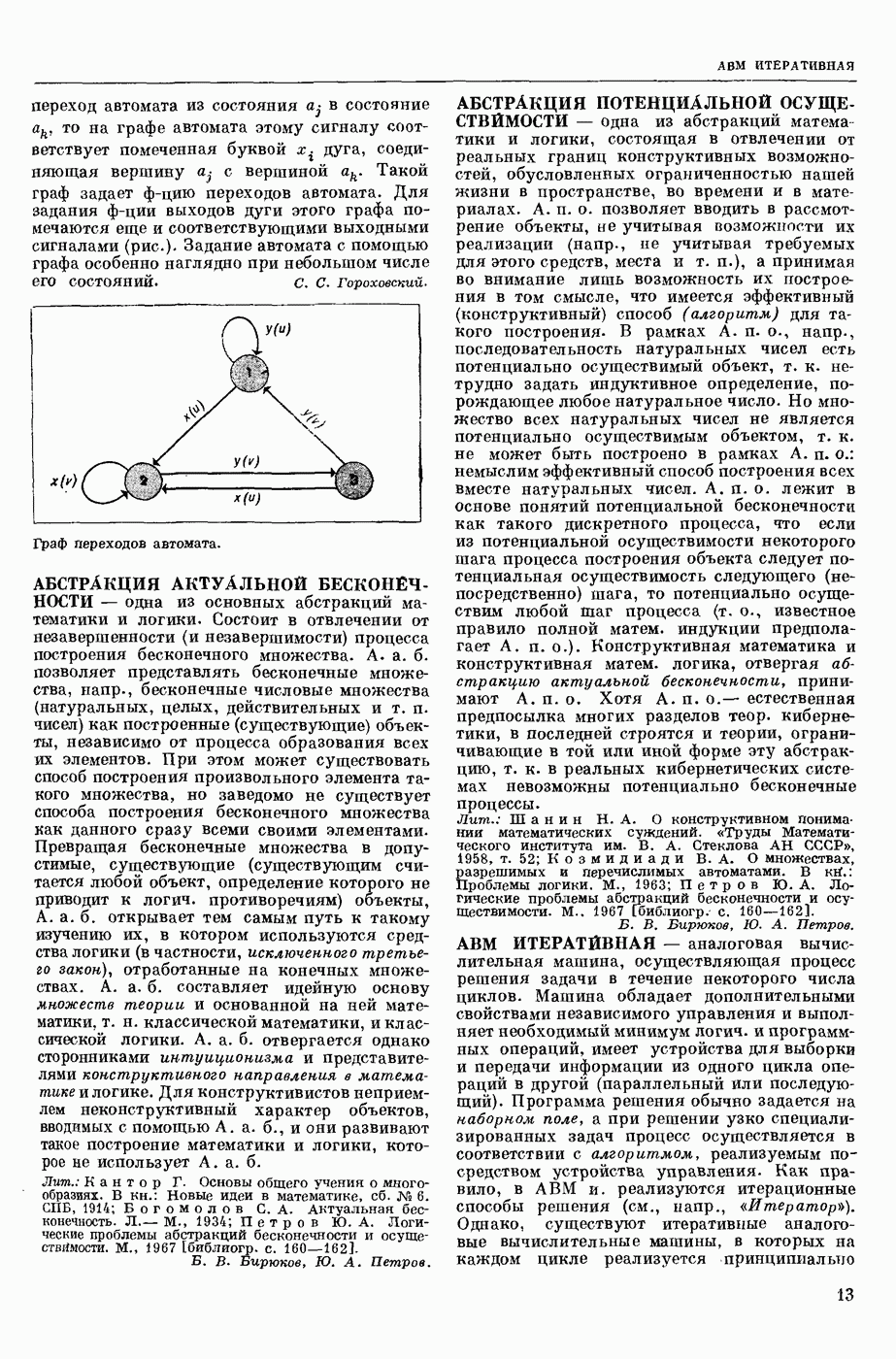
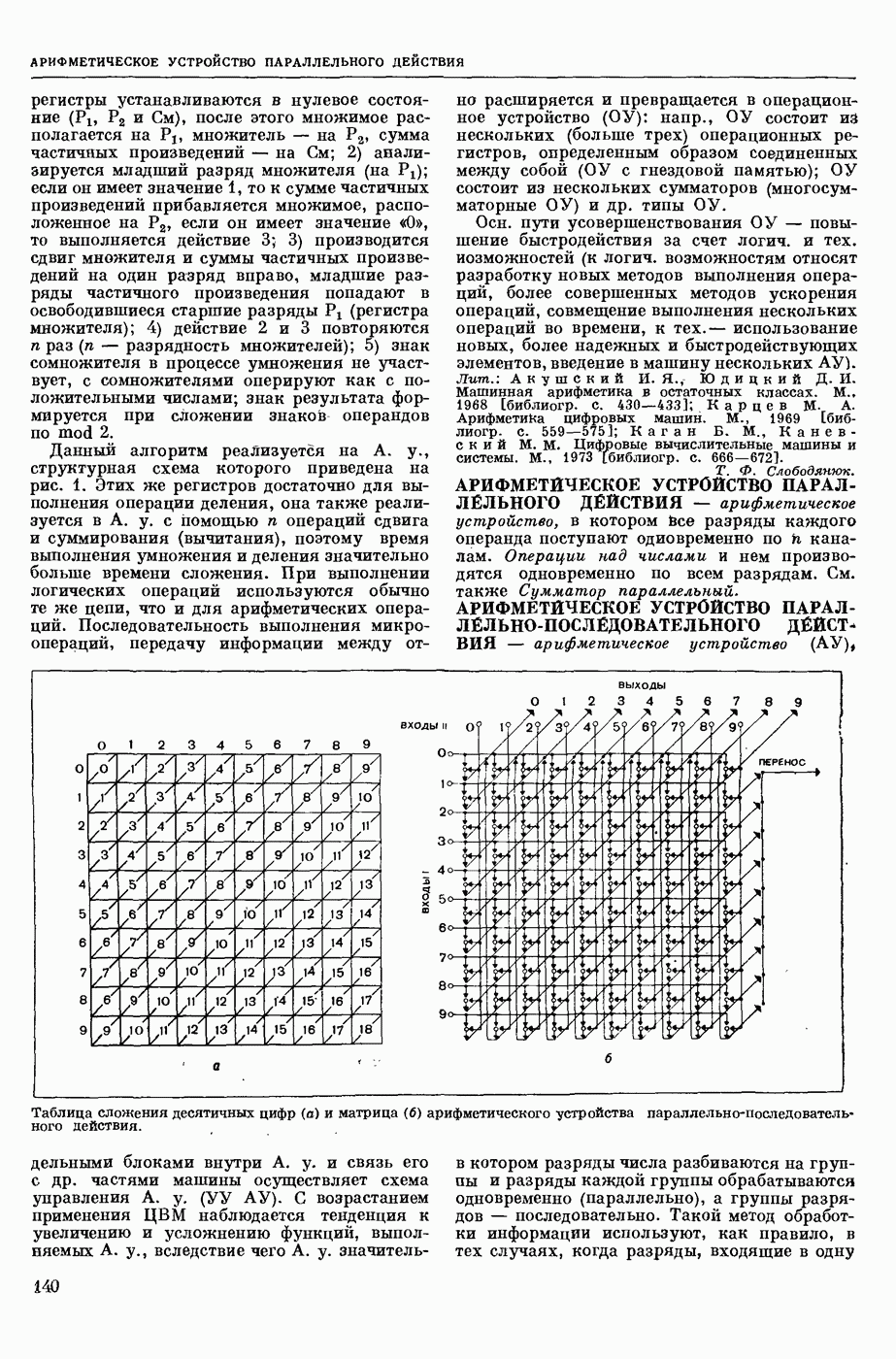
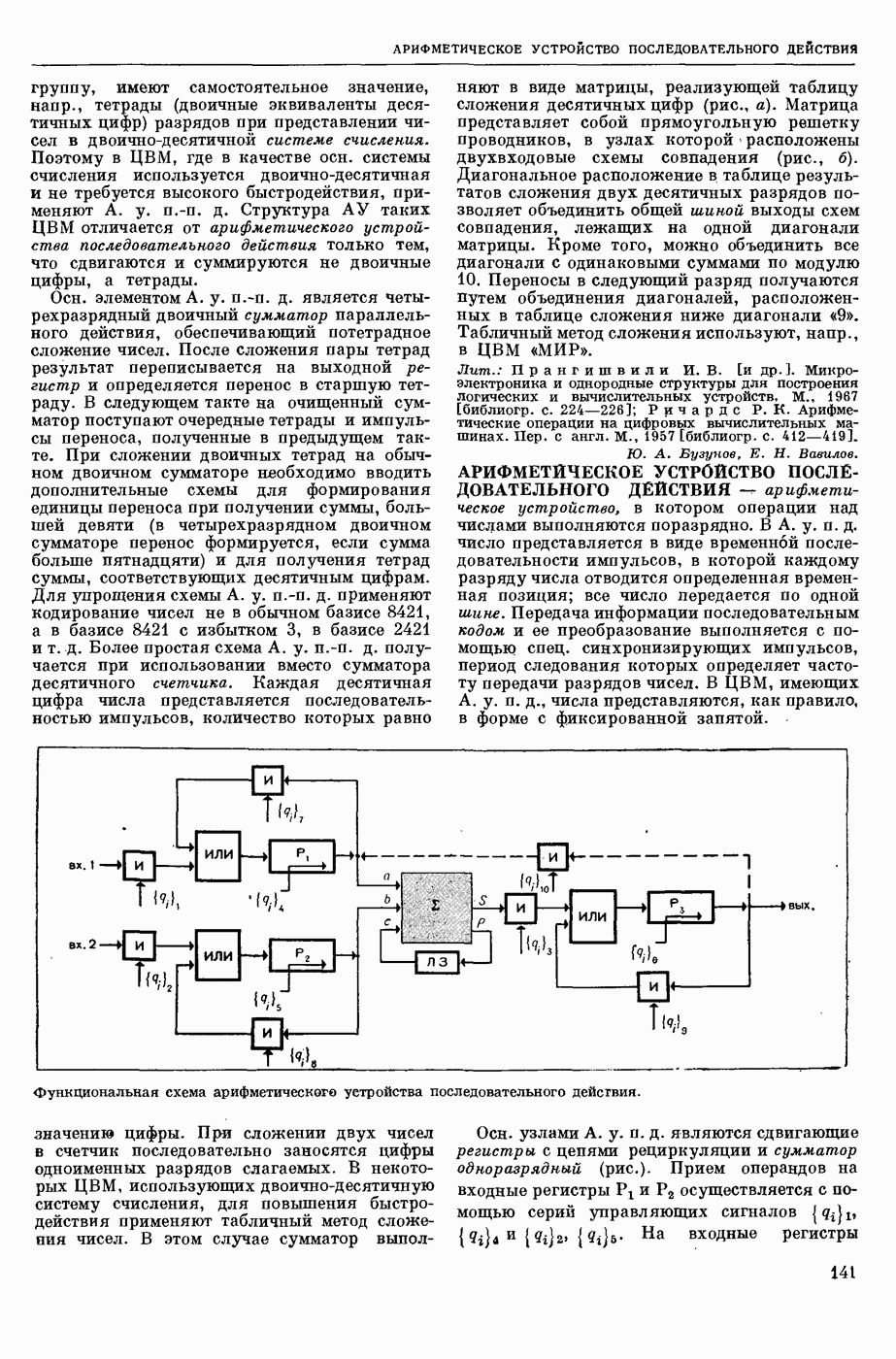
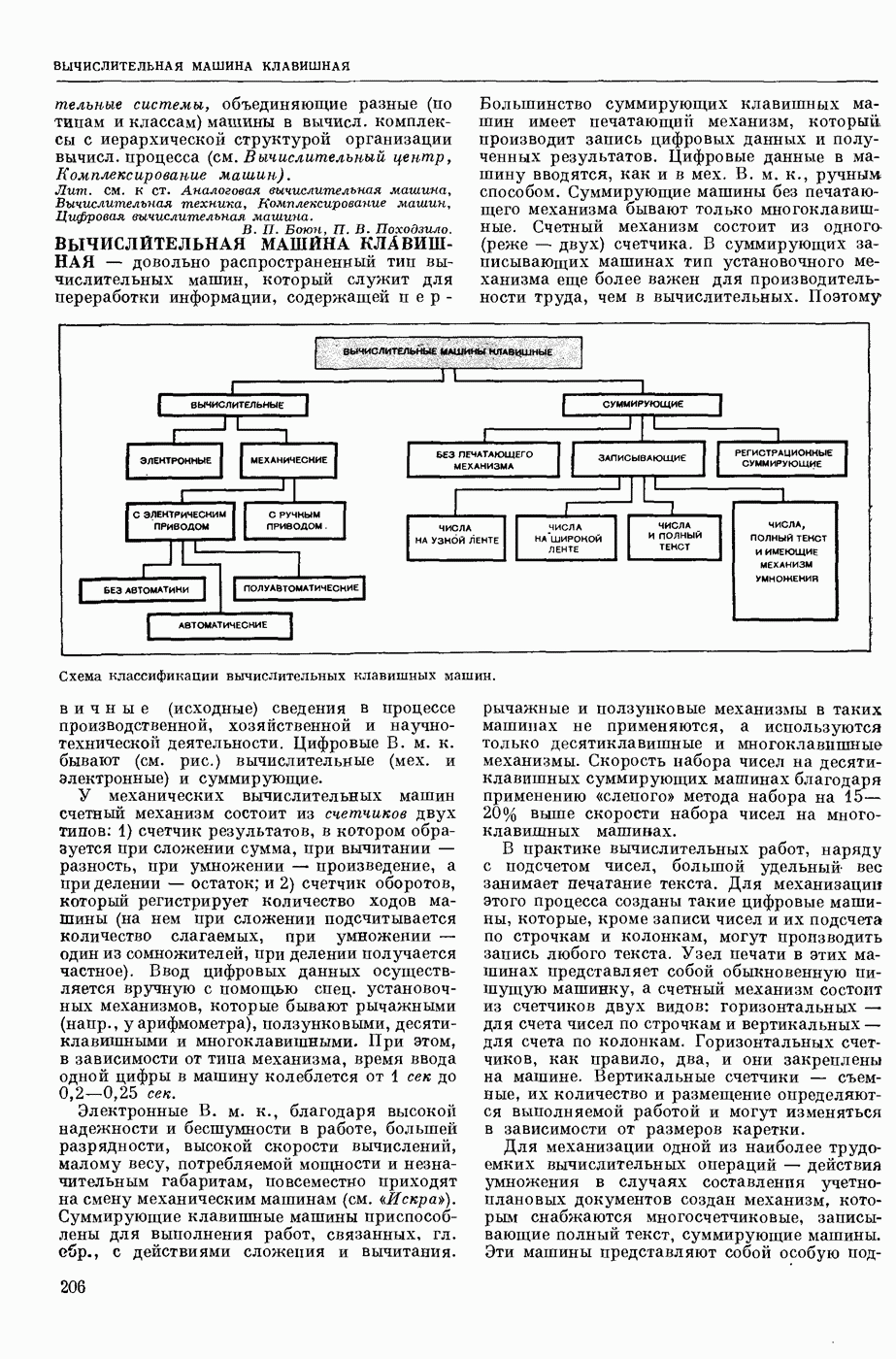
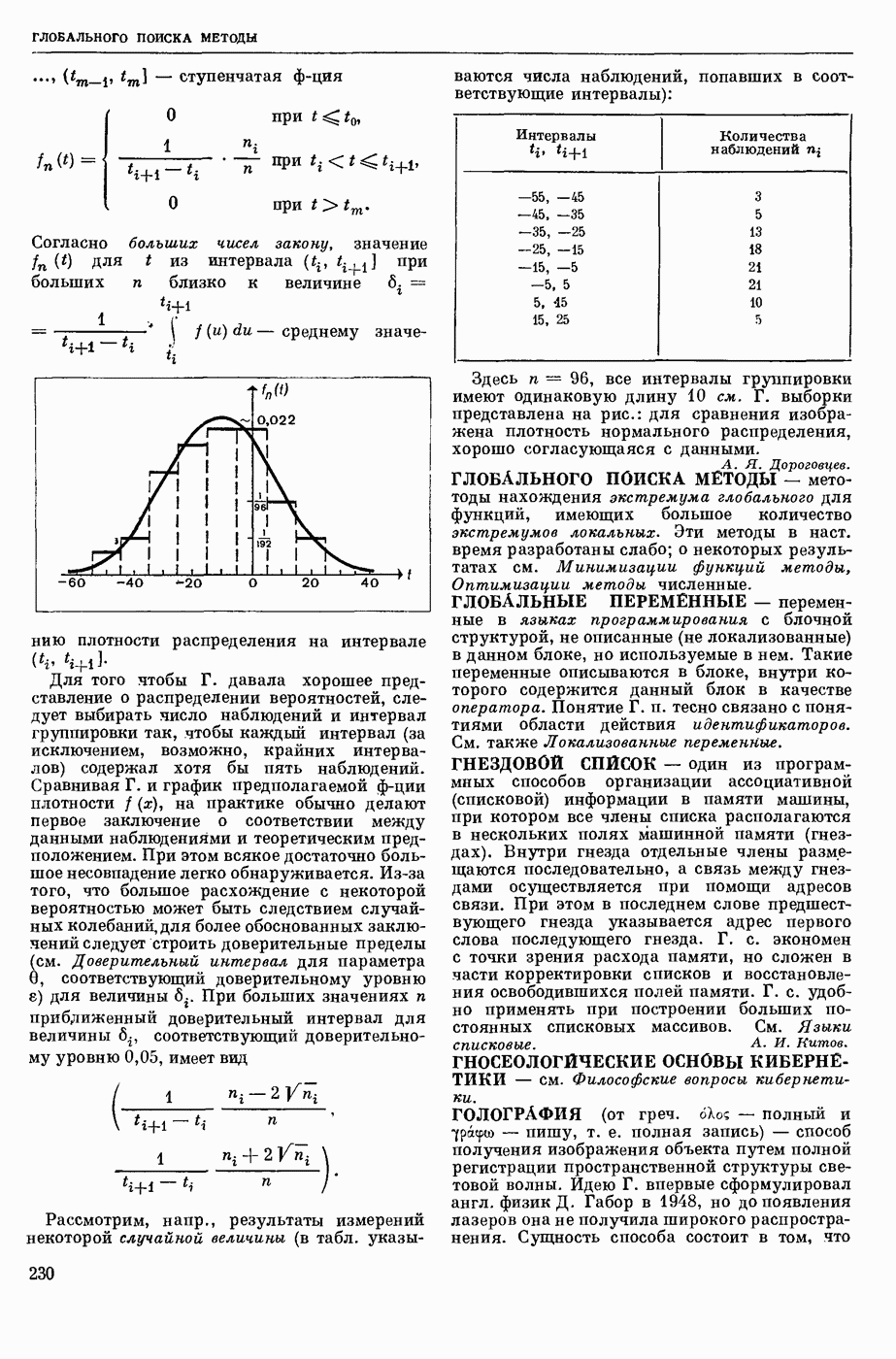
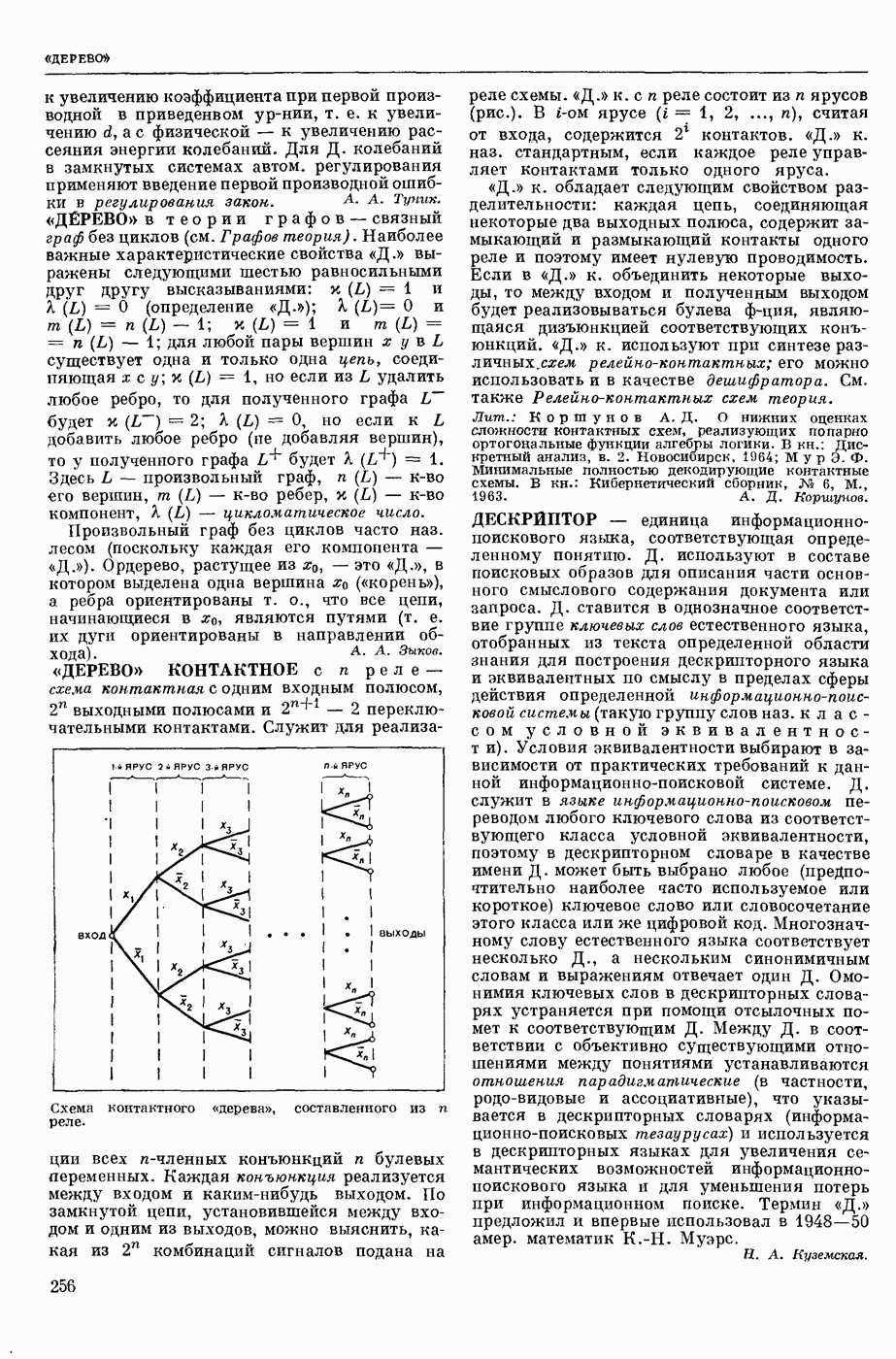
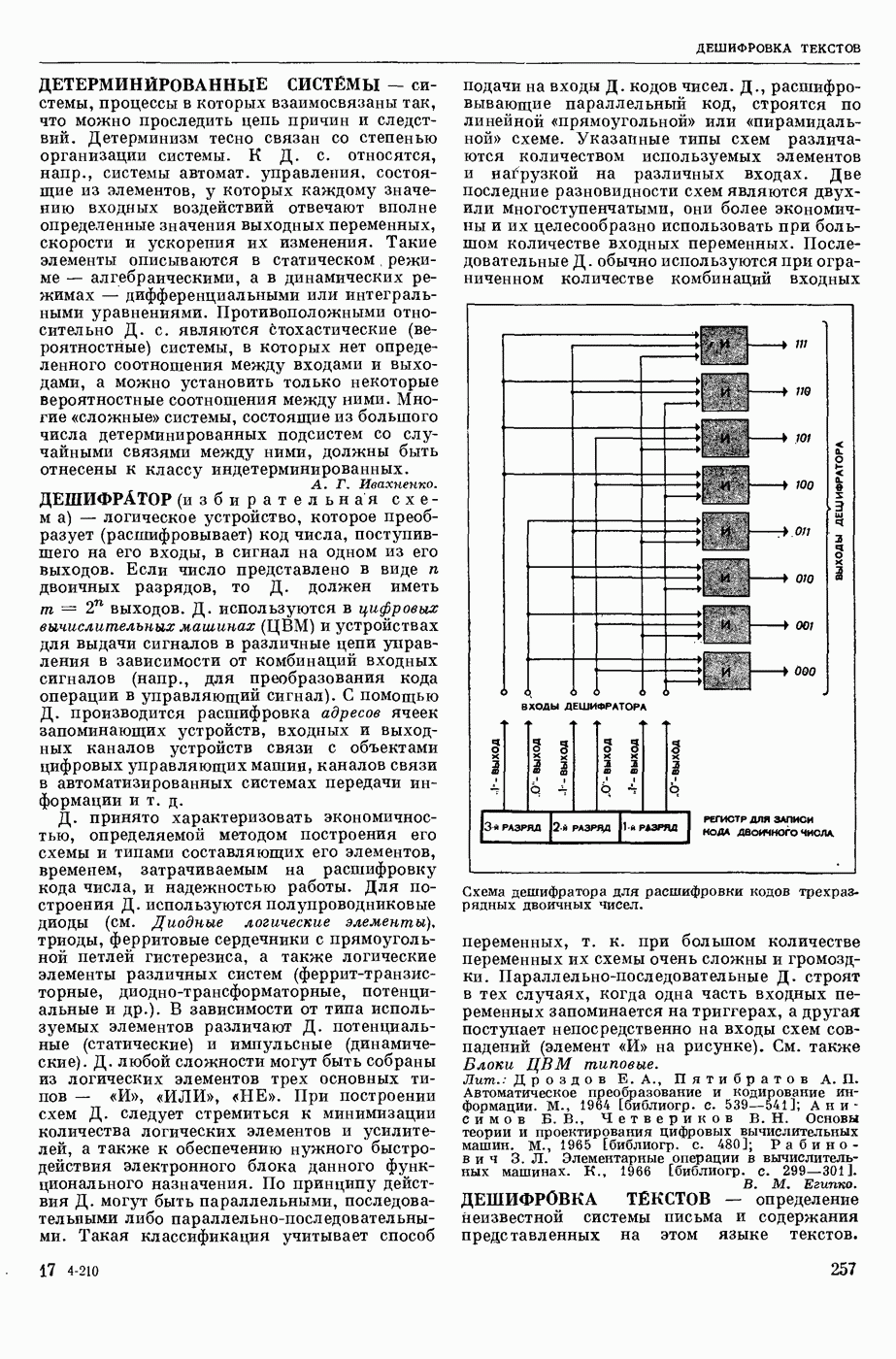
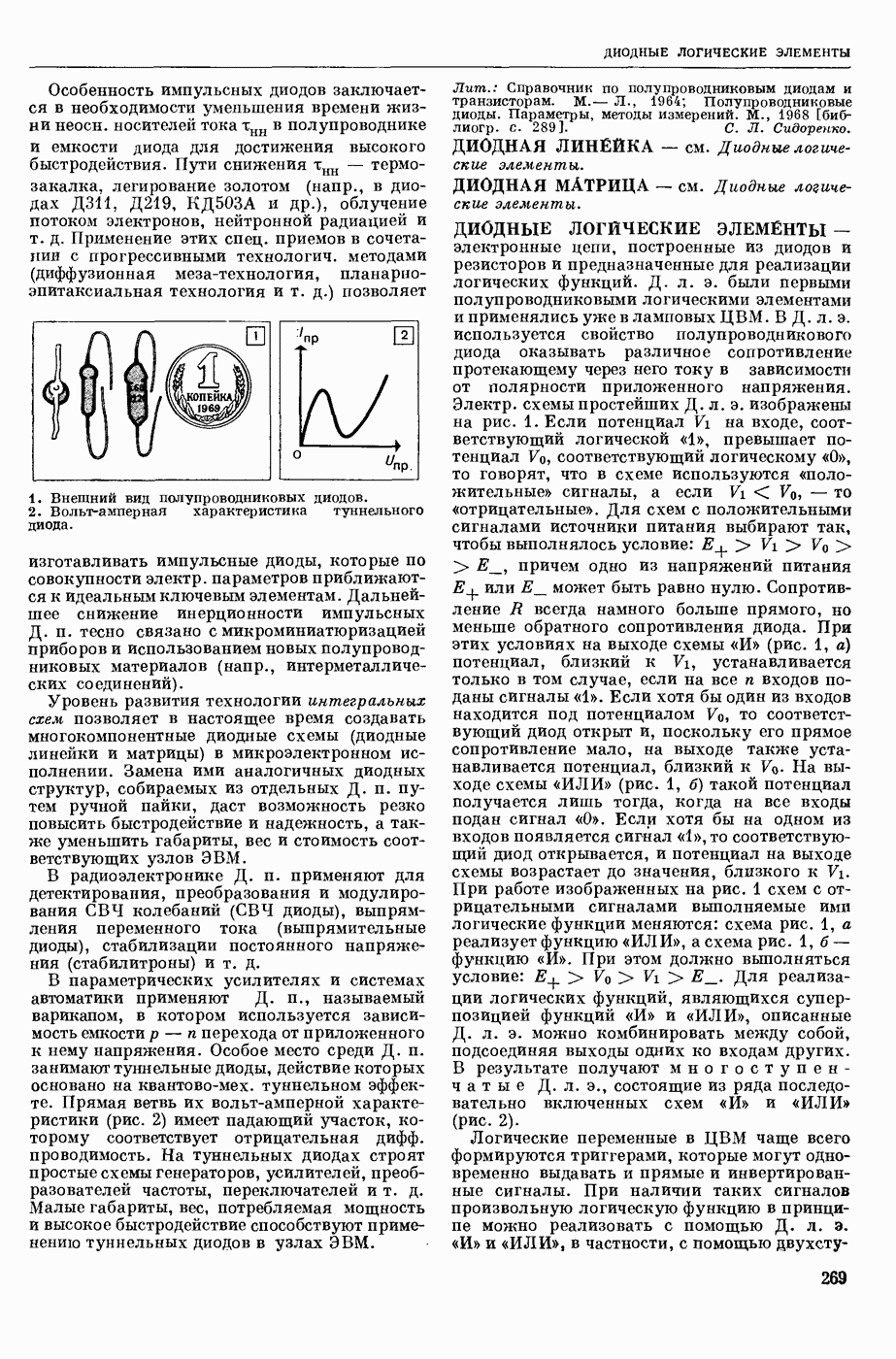
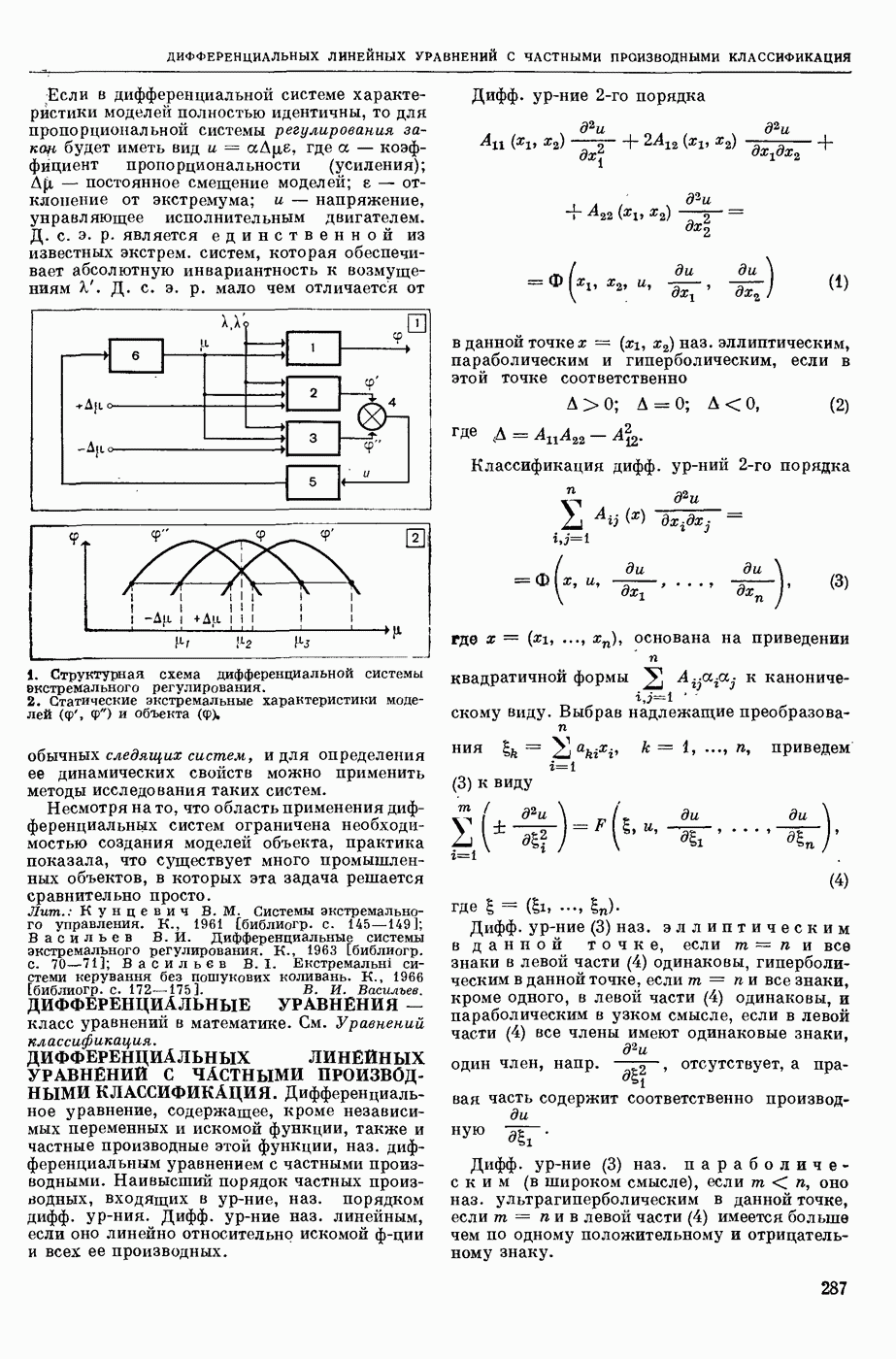
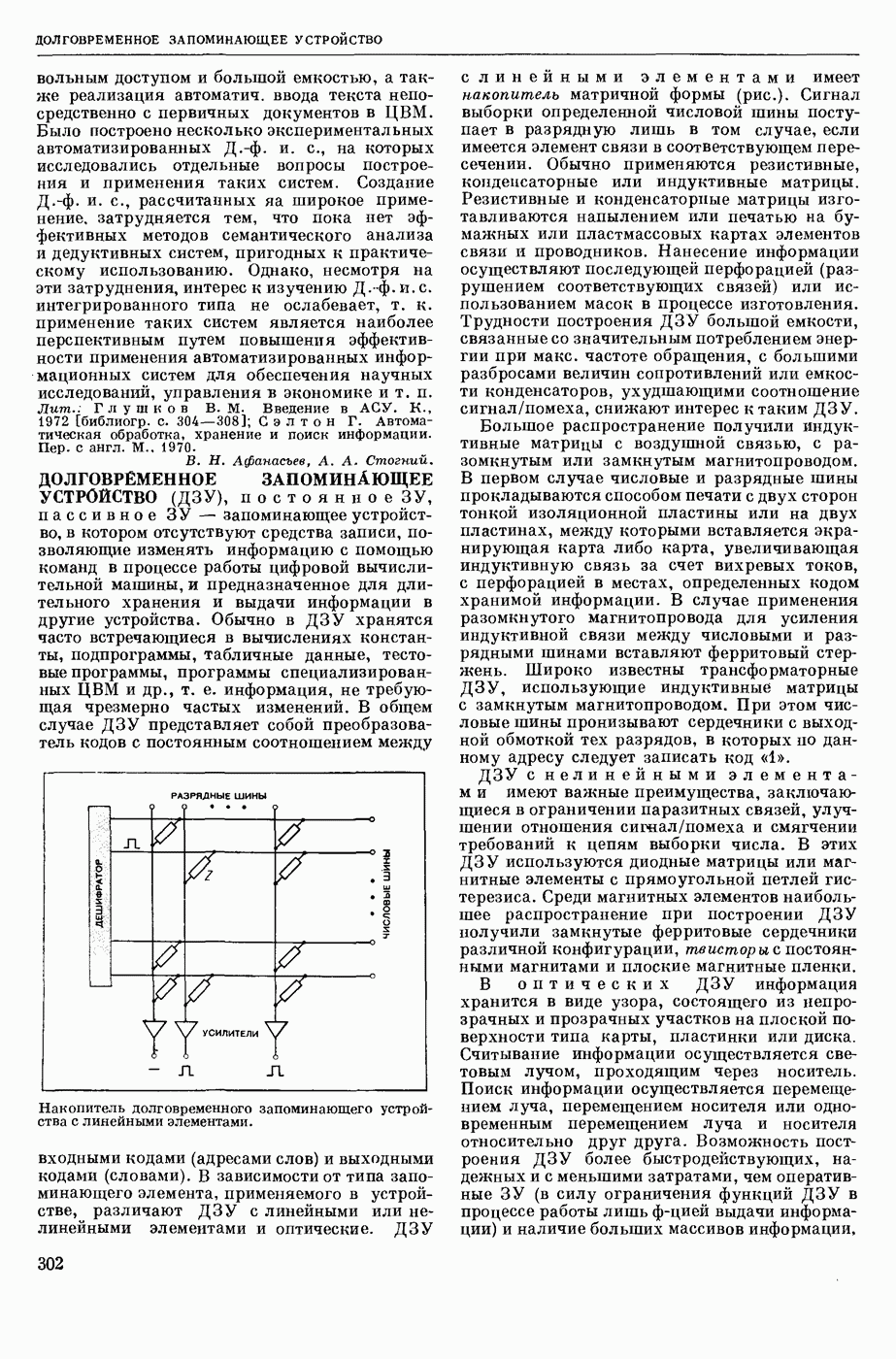
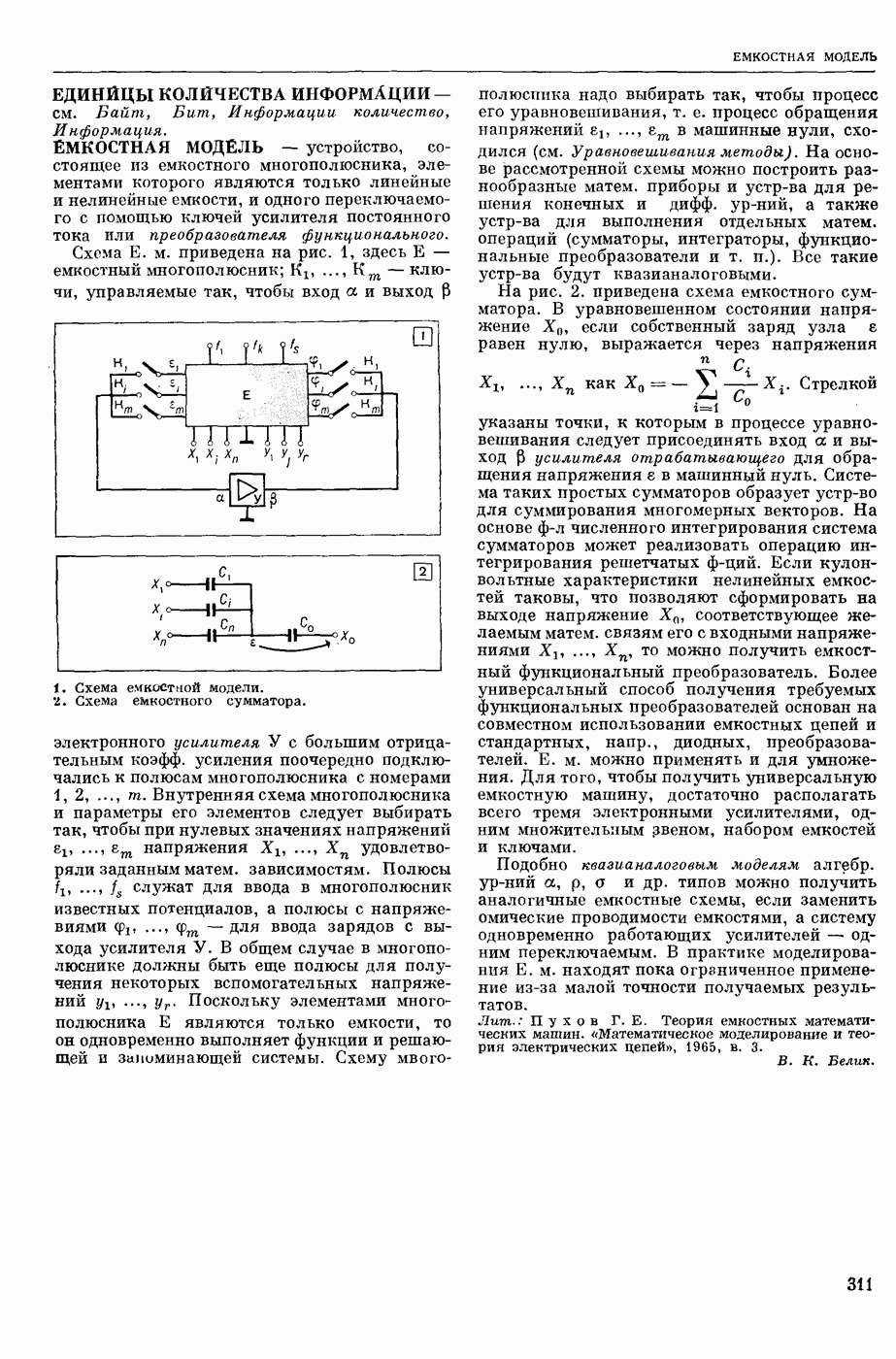
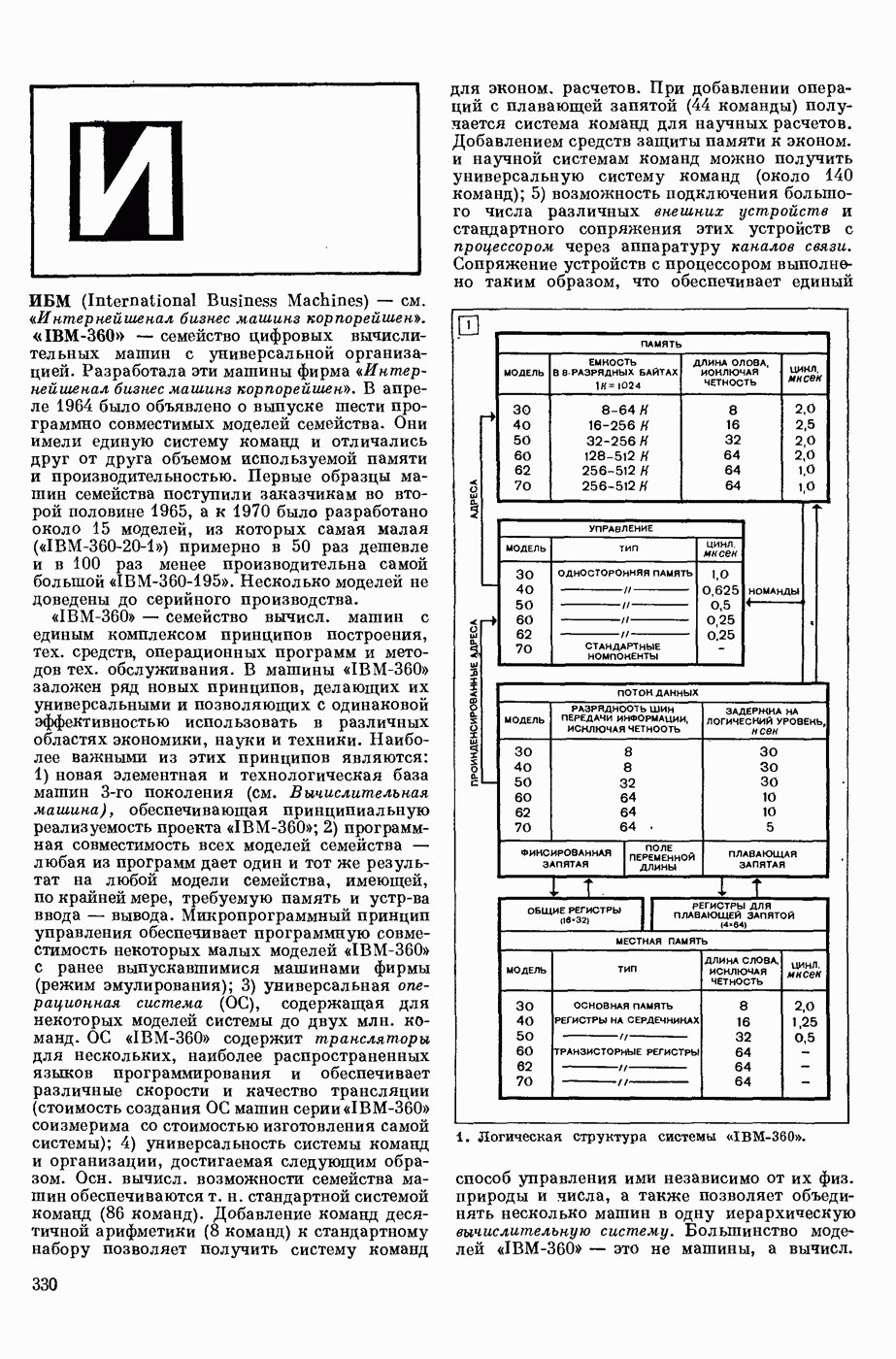
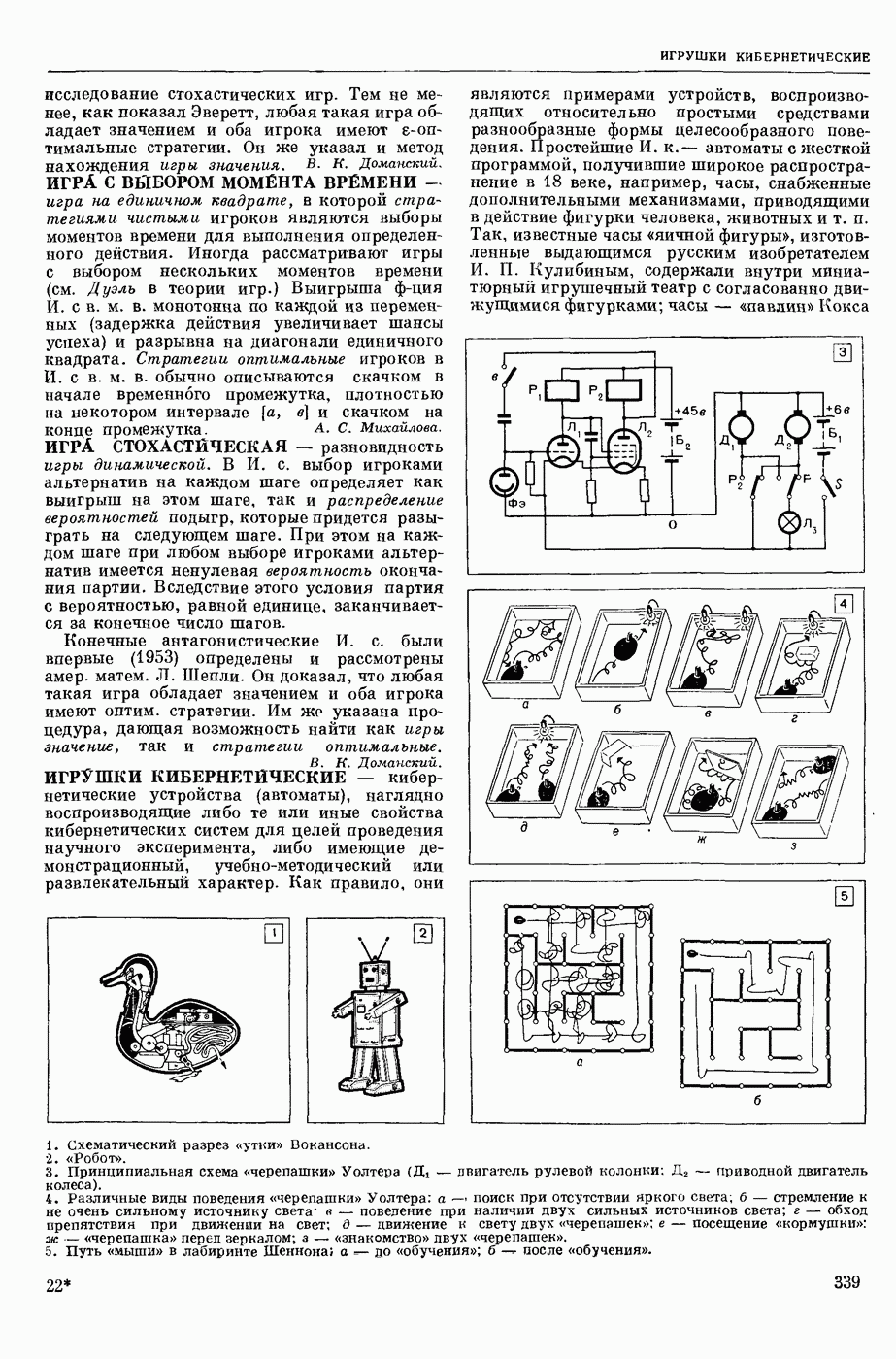
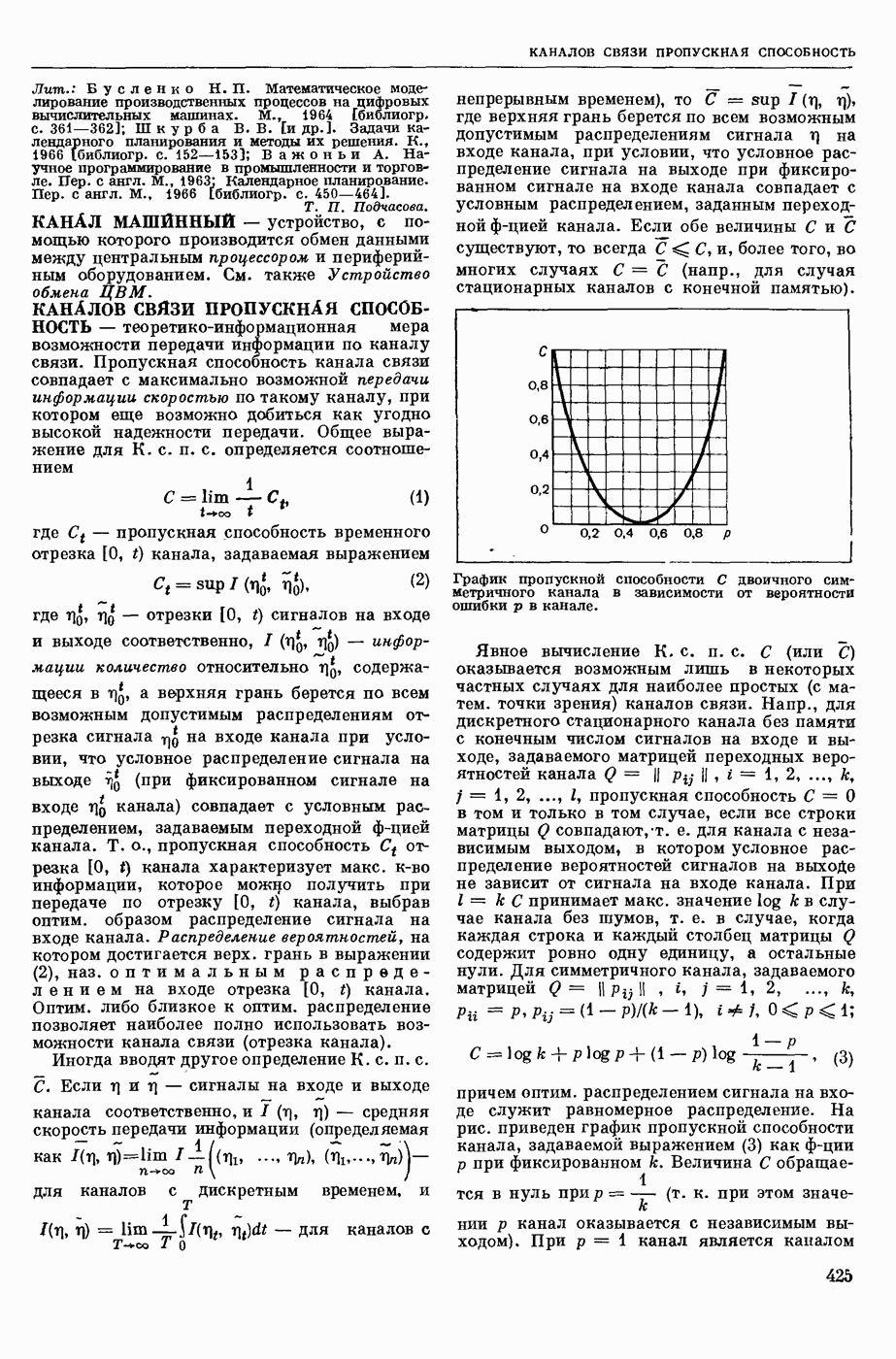
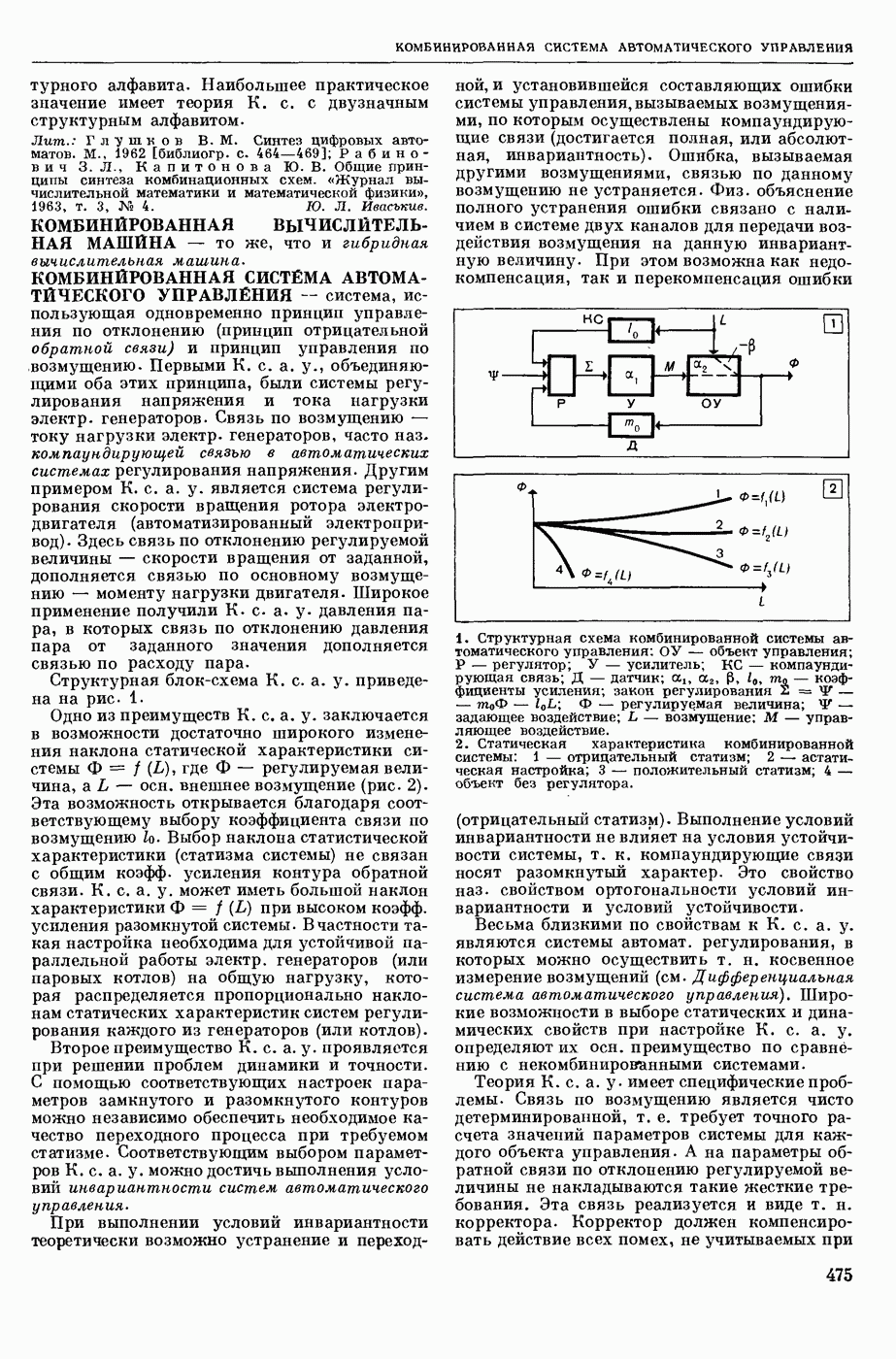
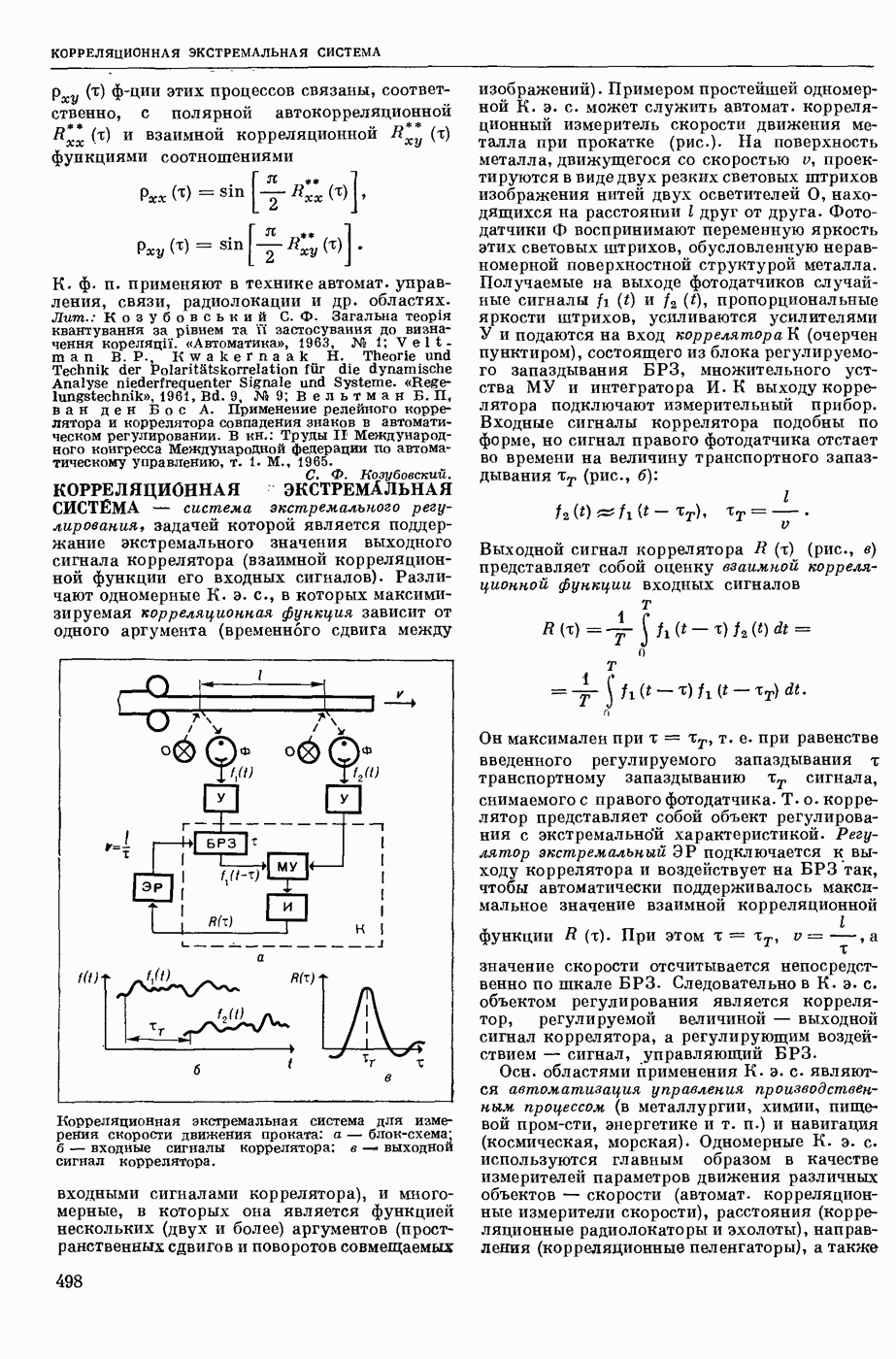
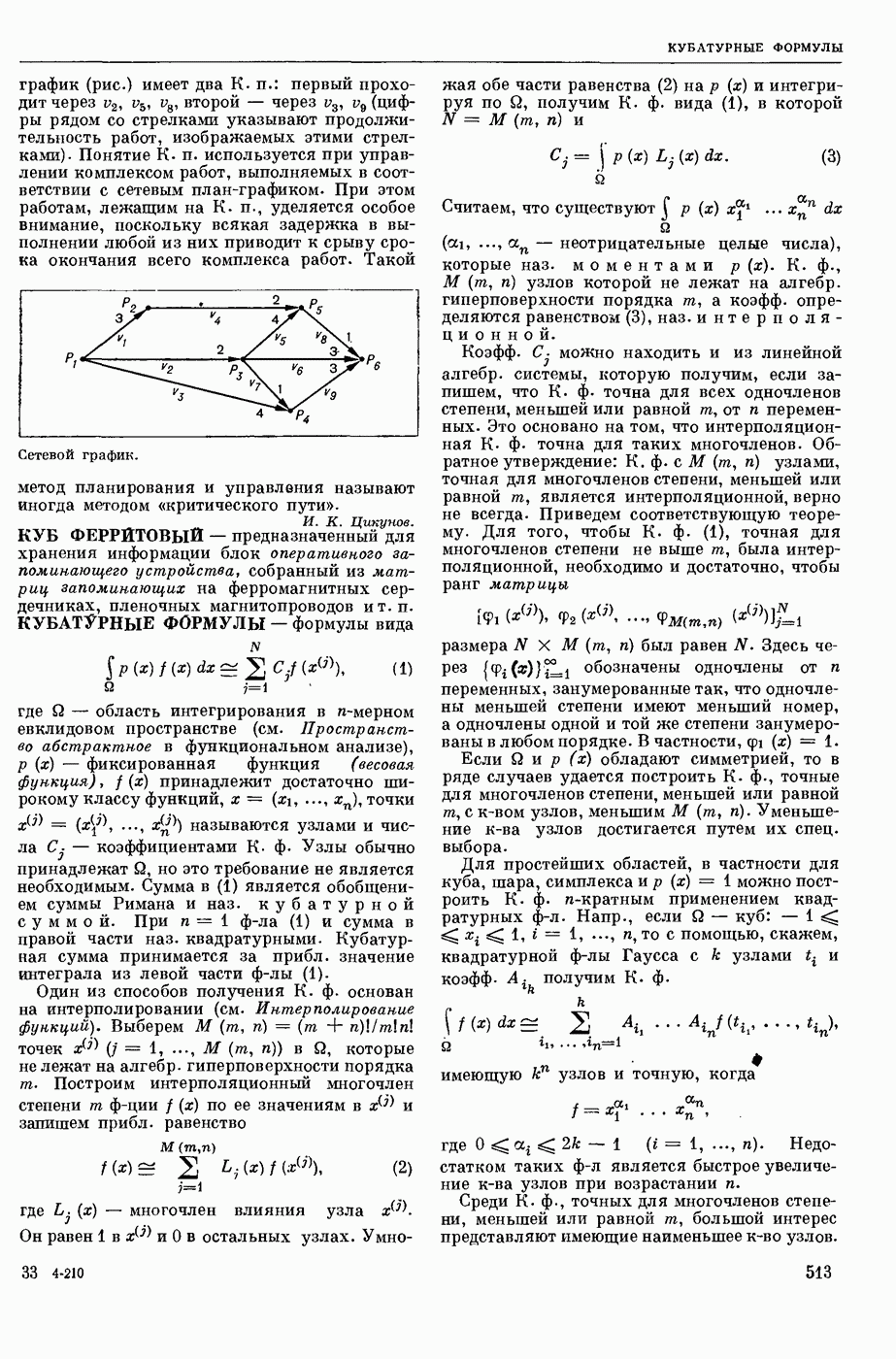
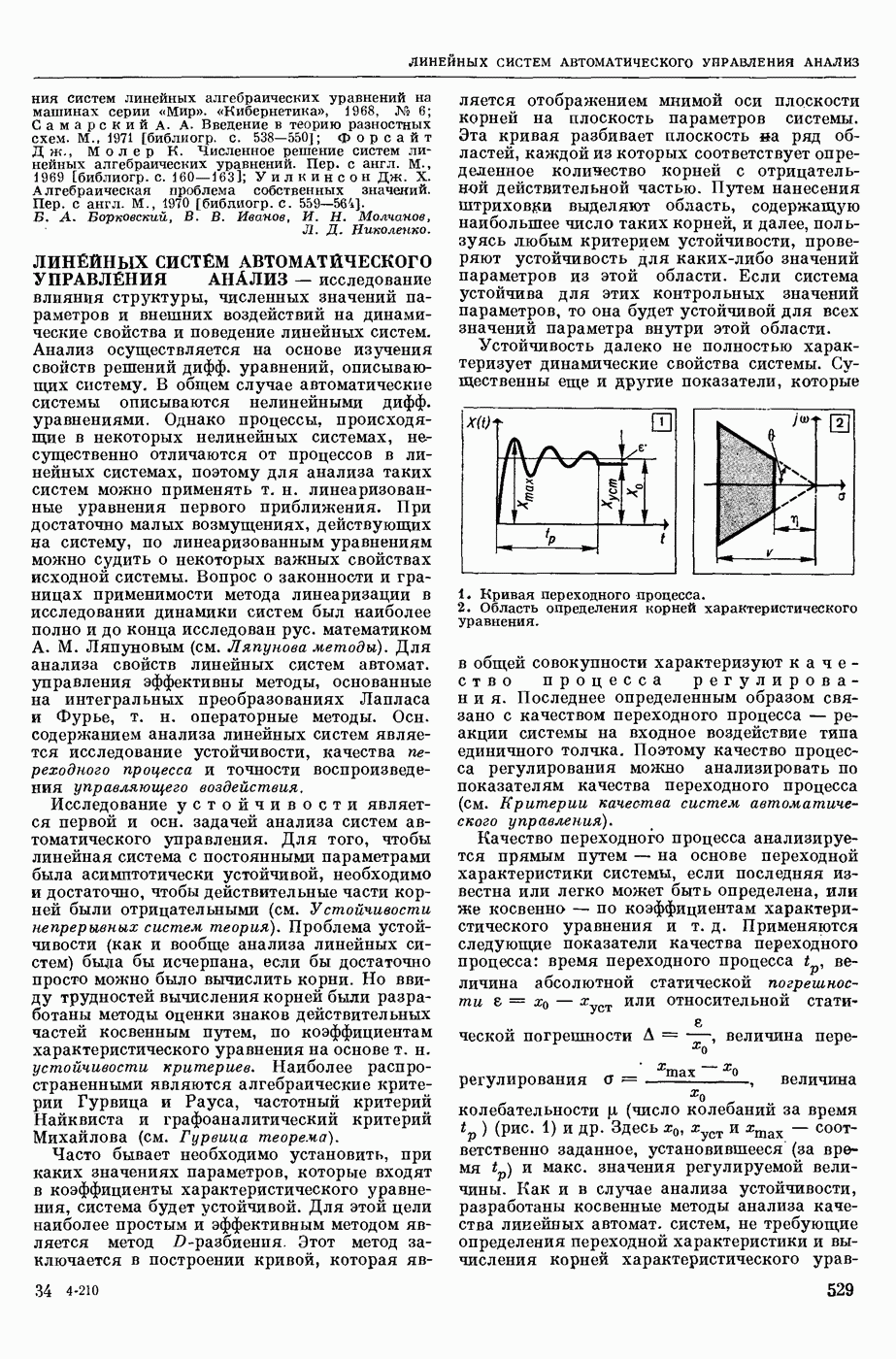
ИЗБЫТОЧНОСТЬ СООБЩЕНИЙ
— величина

, показывающая, насколько эффективно представление сообщений в алфавите А. В случае дискретных сообщений величина

, где Н — энтропия сообщений, М — число символов алфавита А, который используется для представления (кодирования) сообщений;

— средняя длина кодовых слов; основание логарифма совпадает с основанием логарифмов в выражении для Н. Примером неэффективного кодирования является представление сообщений, напр., на русском языке с помощью букв русского алфавита. Избыточность русского языка лежит в пределах от 0,5 до 0,8. Приблизительно в тех же пределах лежит избыточность и др. разговорных языков.
Методы оптимального статистического кодирования позволяют уменьшать И. с. Для кодирования статистически независимых сообщений с неравномерным распределением вероятностей могут использоваться метод Шеннона — Фано, метод Хаффмена и др. Осн. методом кодирования статистически зависимых сообщений является укрупнение сообщений, т. е. объединение сообщений в блоки и последующее кодирование блоков одним из известных методов кодирования независимых сообщений. В случае непрерывных сообщений длительности Г и конечного алфавита А под И. с., представленных в алфавите А с точностью  (о выборе меры точности см. Эпсилон-энтропия), понимается величина
(о выборе меры точности см. Эпсилон-энтропия), понимается величина  где
где  энтропия сообщений, т. е. минимальное к-во единиц информации в сек., позволяющее восстановить непрерывное сообщение с точностью, не ниже е. Уменьшение И. с., сохраняющее меру точности, наз. сжатием сообщений. Сжатие может быть выполнено с помощью двух операций: дискретизации (т. е. представления сообщений конечным к-вом действительных чисел) и квантования (т. е. представления каждого действительного числа с помощью символов некоторого конечного алфавита). Задача дискретизации сводится к выбору аппроксимации сообщений конечным рядом. Задача квантования аналогична задаче оптимального статистического кодирования. В. Д. Колесник.
энтропия сообщений, т. е. минимальное к-во единиц информации в сек., позволяющее восстановить непрерывное сообщение с точностью, не ниже е. Уменьшение И. с., сохраняющее меру точности, наз. сжатием сообщений. Сжатие может быть выполнено с помощью двух операций: дискретизации (т. е. представления сообщений конечным к-вом действительных чисел) и квантования (т. е. представления каждого действительного числа с помощью символов некоторого конечного алфавита). Задача дискретизации сводится к выбору аппроксимации сообщений конечным рядом. Задача квантования аналогична задаче оптимального статистического кодирования. В. Д. Колесник.