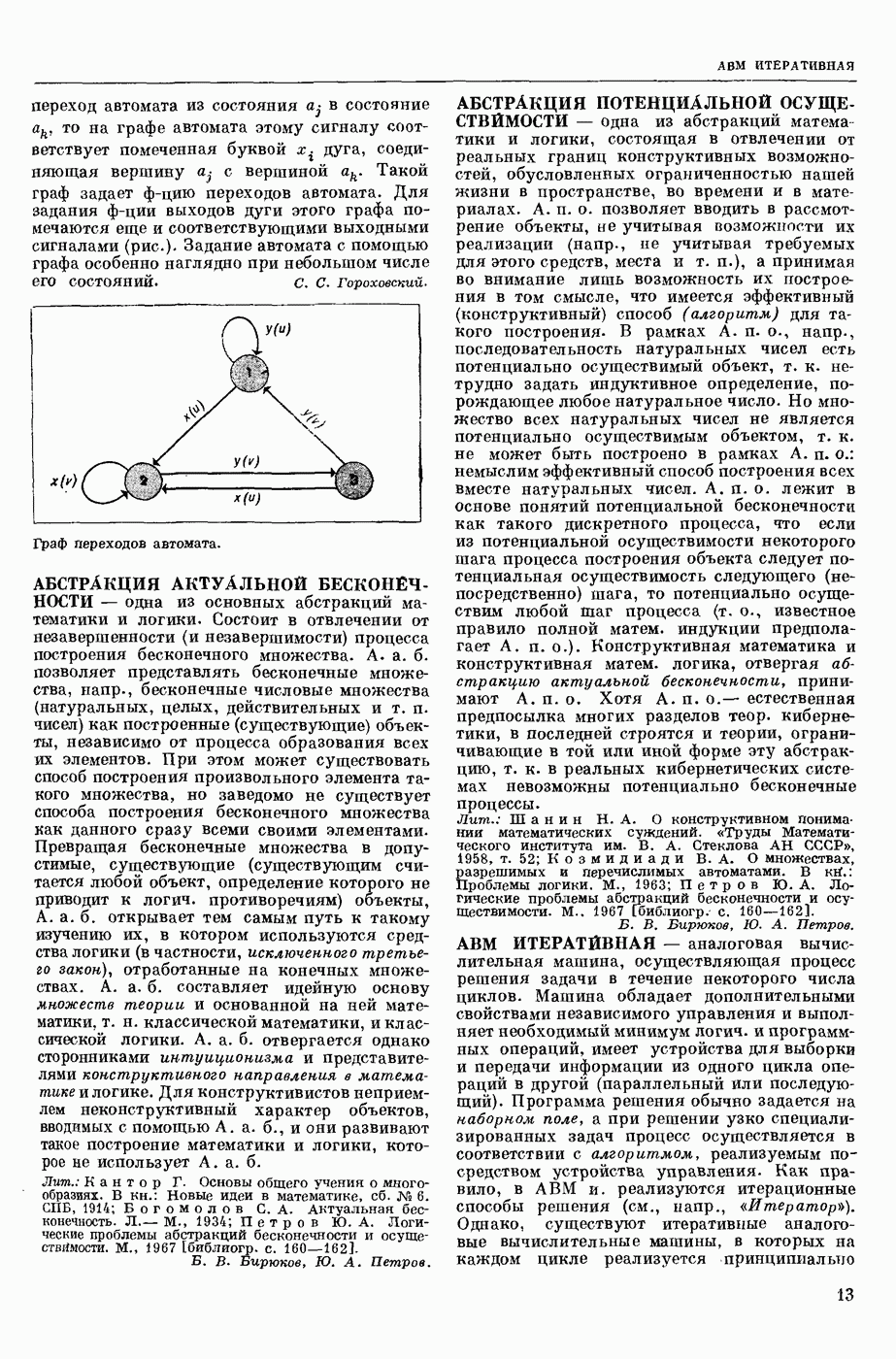
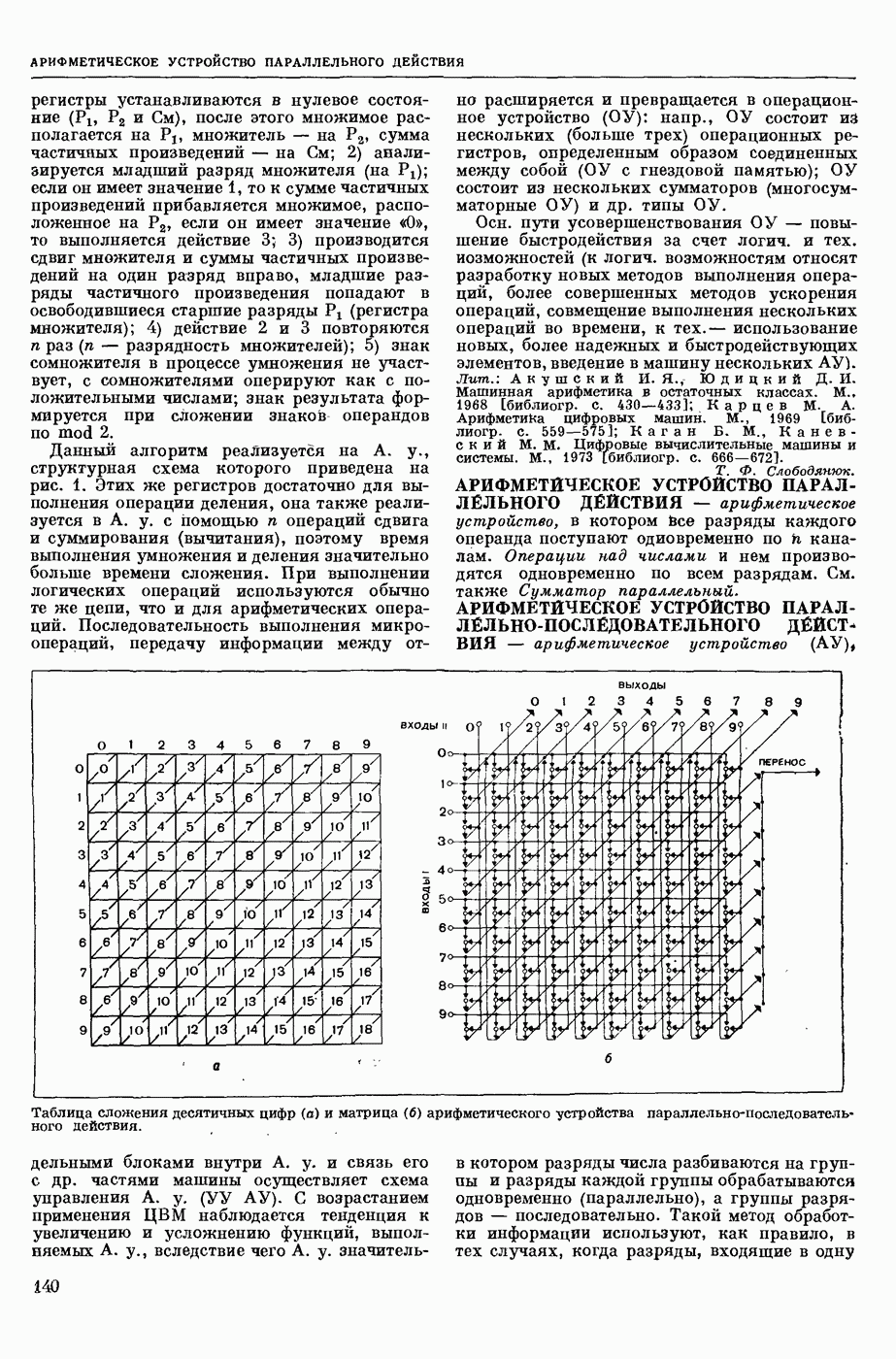
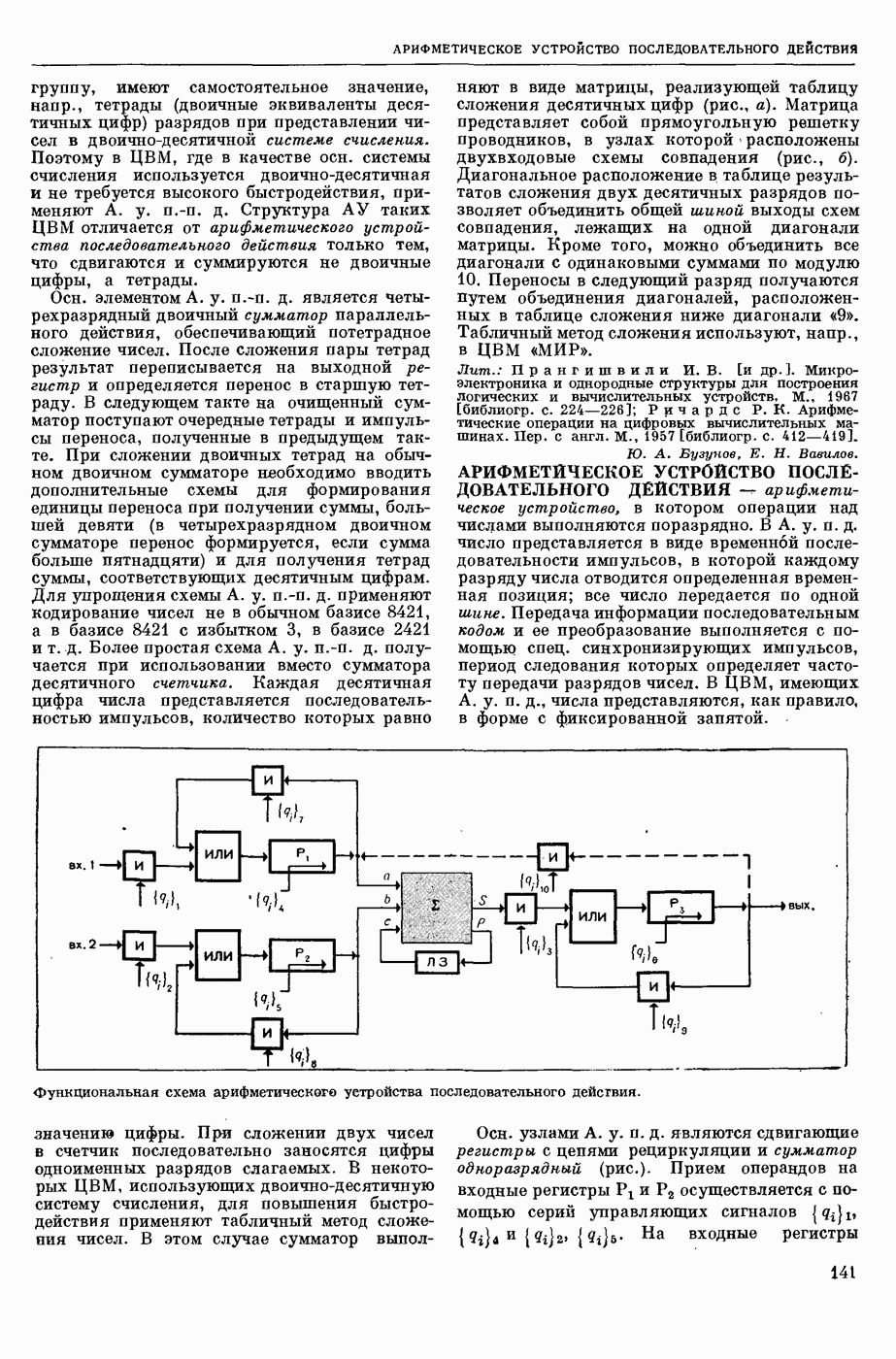
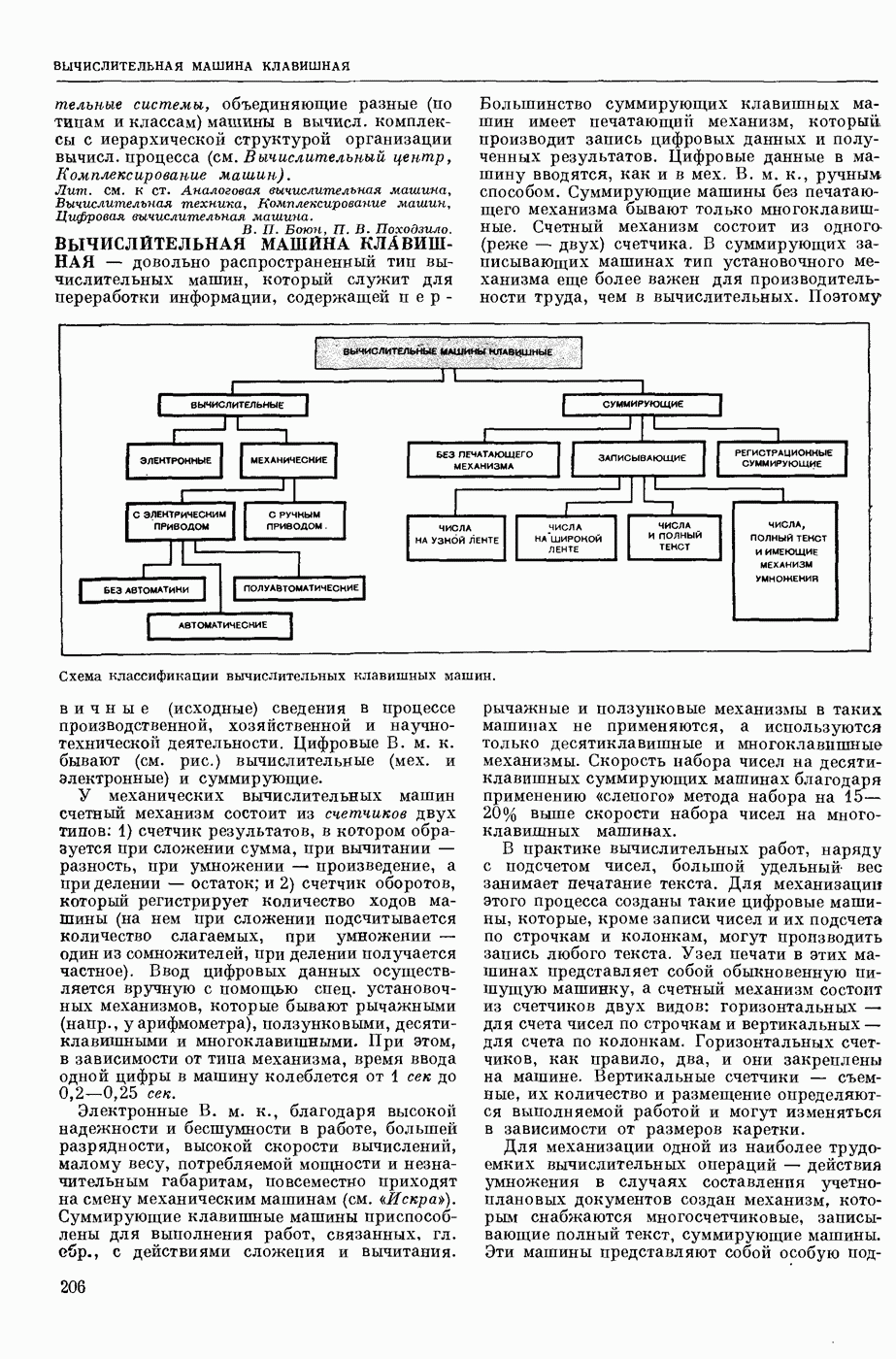
МАШИННЫЙ ПЕРЕВОД, автоматический перевод
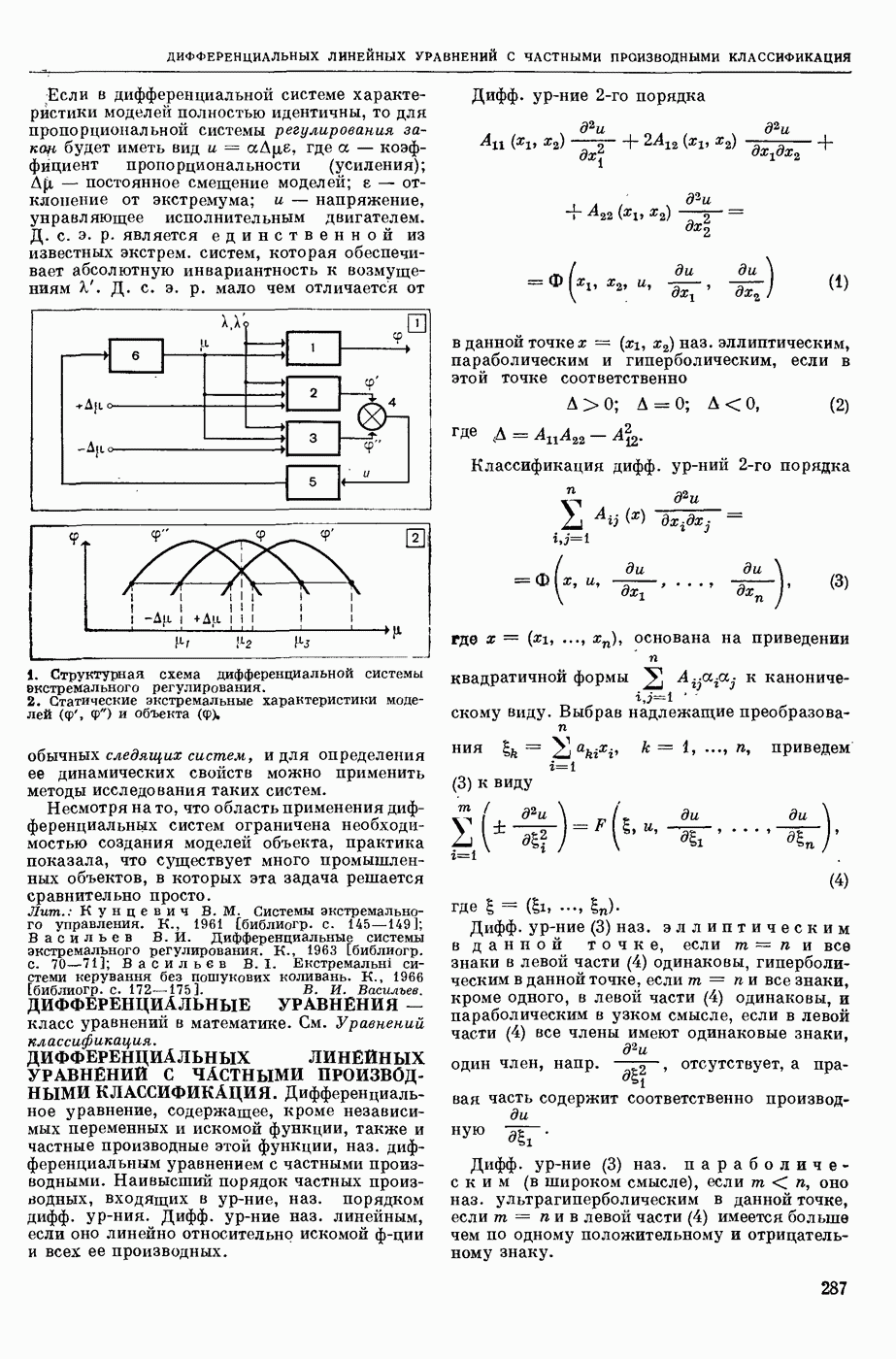
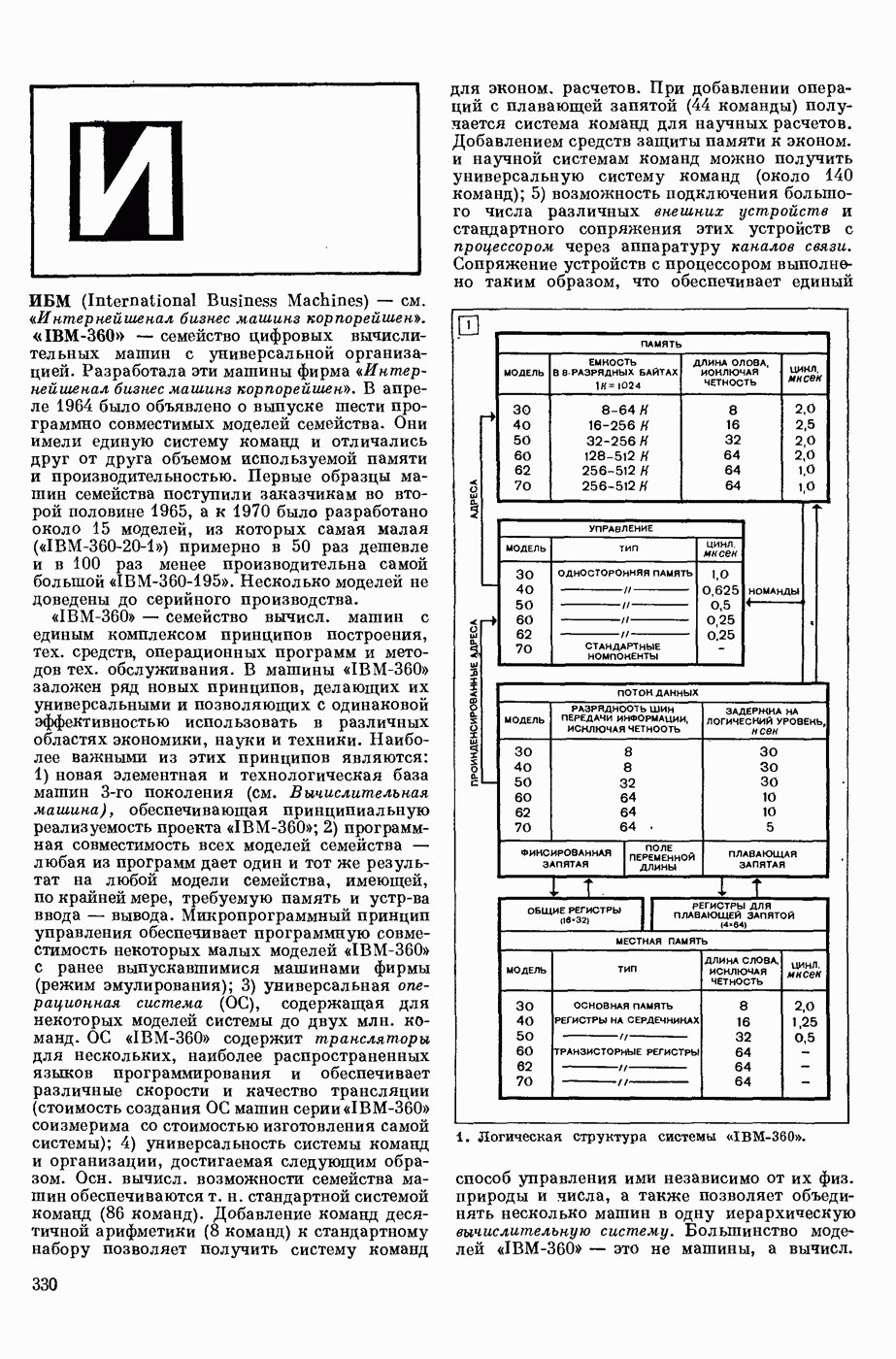
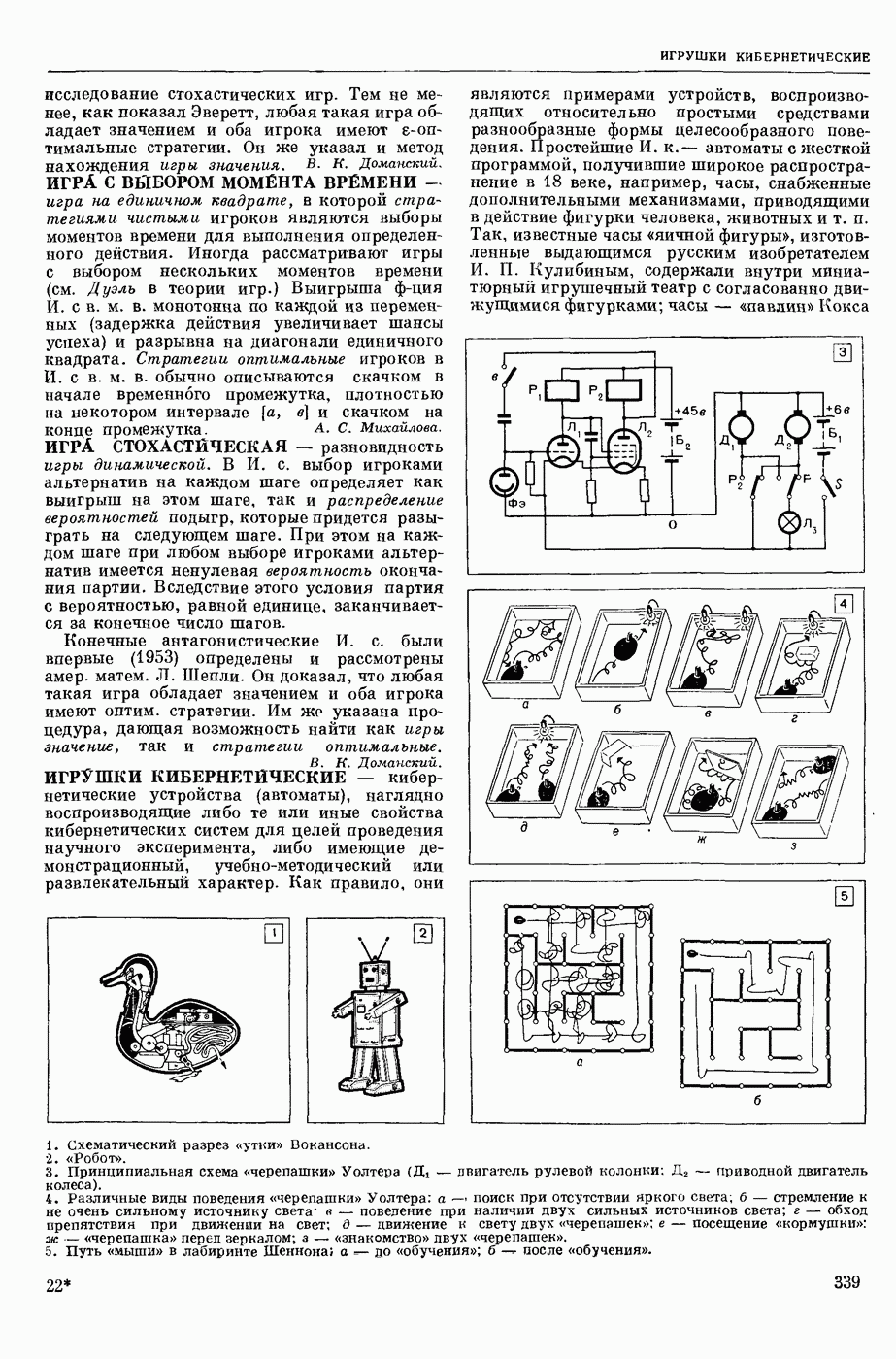
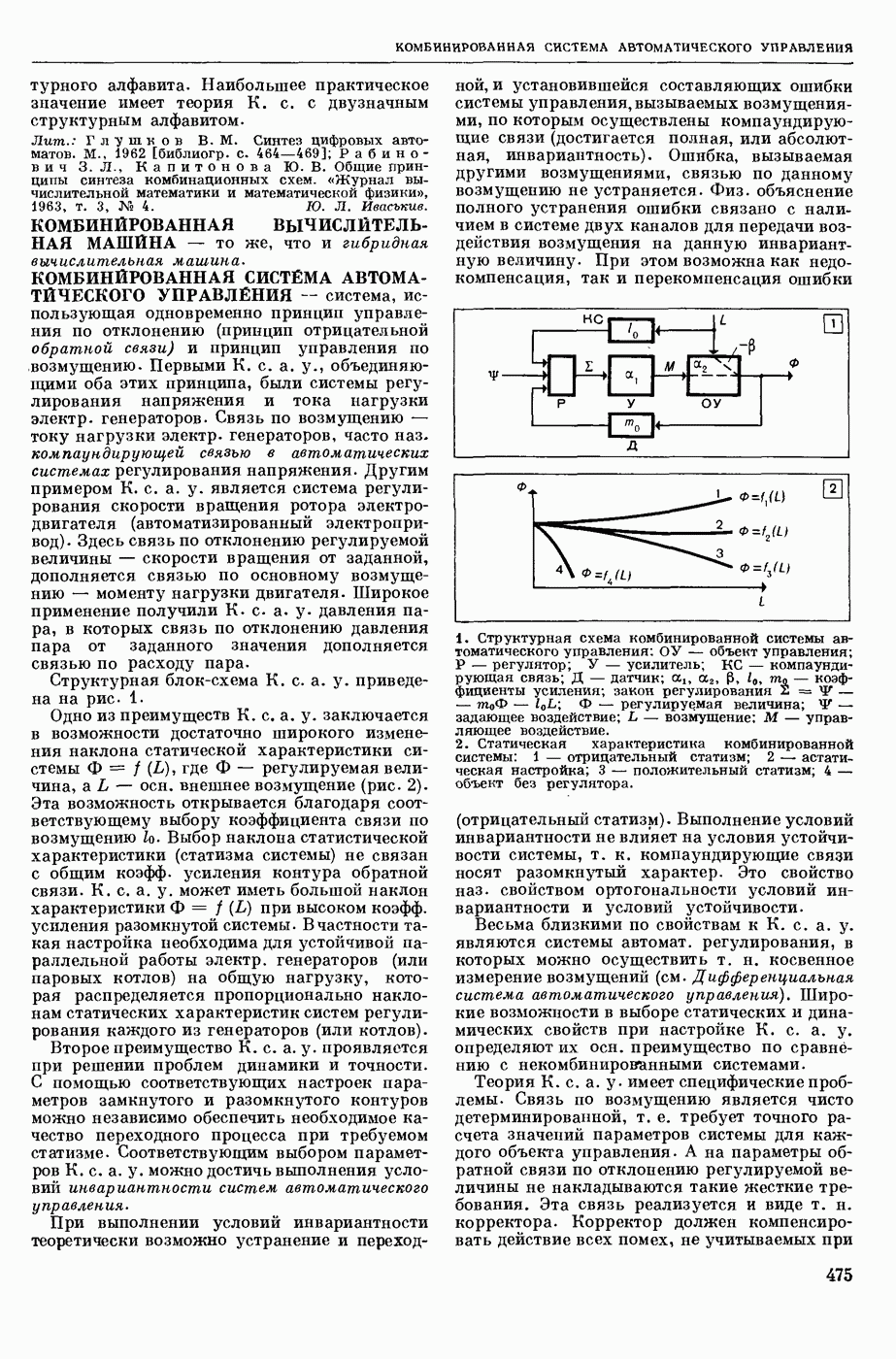
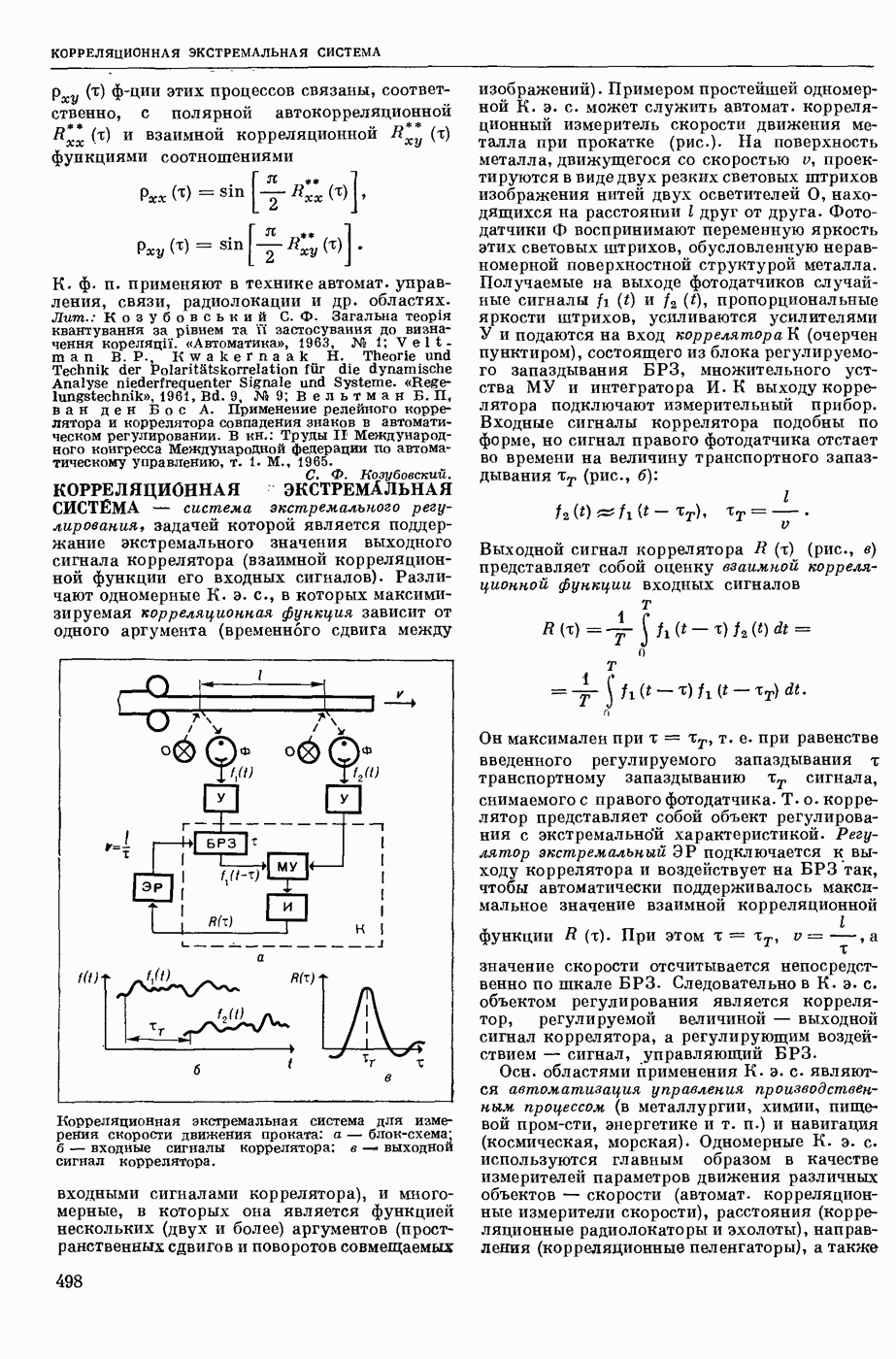
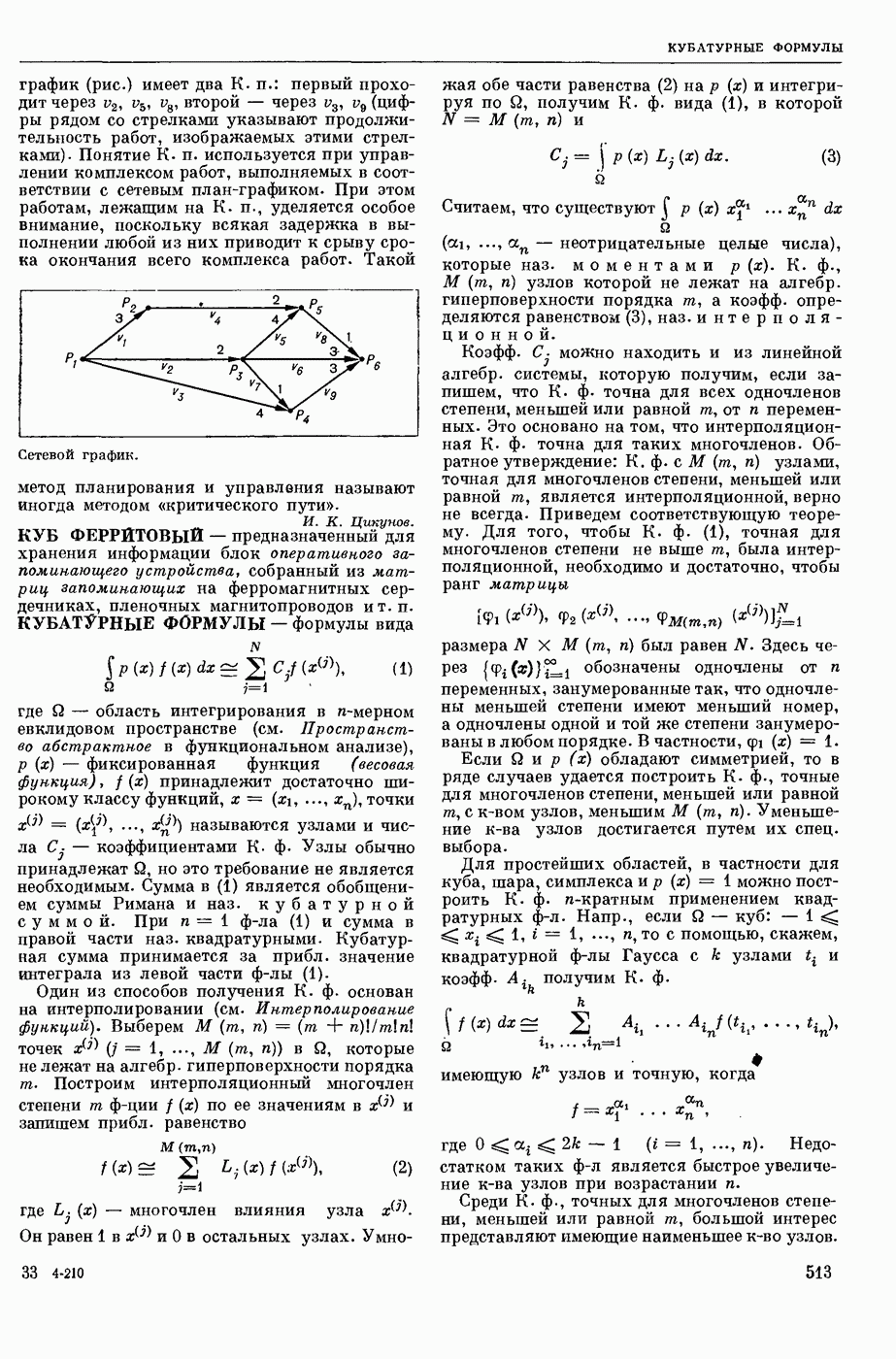
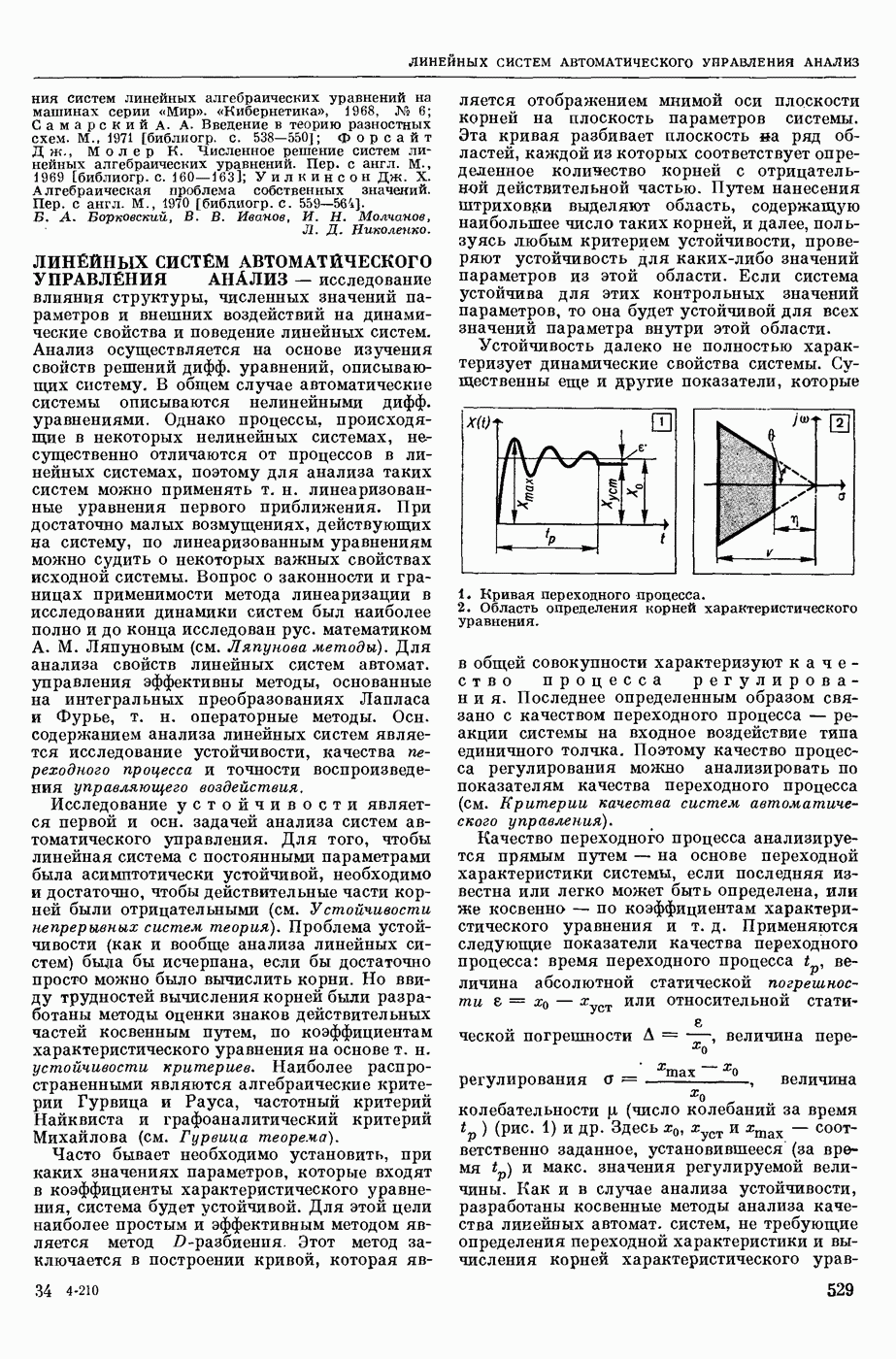
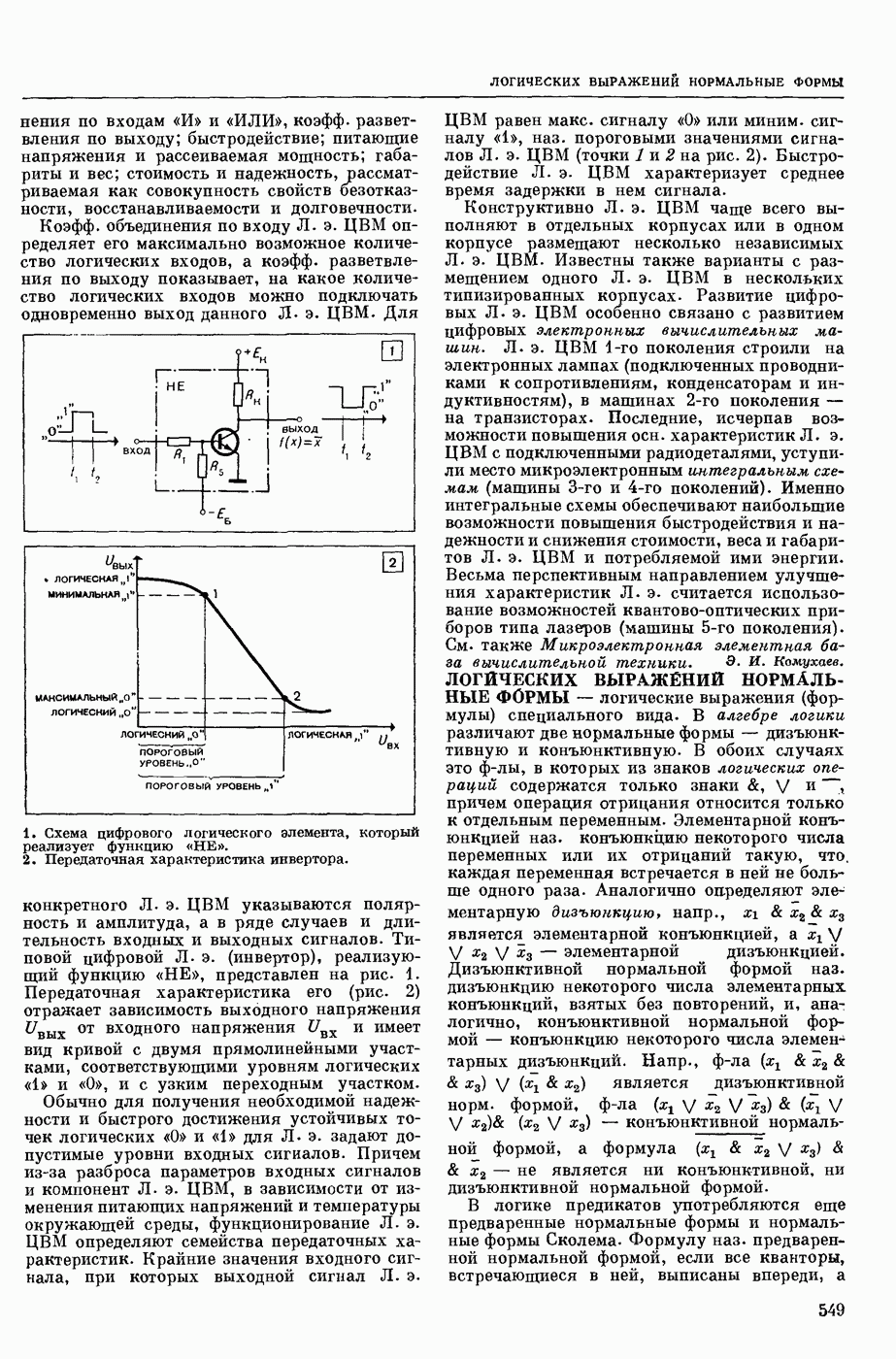
— в узком смысле — перевод текстов с одного естественного языка на другой при помощи электронных вычислительных (универсальных или специализированных) машин; в широком смысле — область научных исследований, связанных с созданием систем М. п. в указанном выше узком смысле. Вопрос о возможности использования ЦВМ для перевода с одного естественного языка на другой был впервые поставлен в США 1947. С 1954 начались исследования по М. п. в СССР. В настоящее время работы в этой области ведутся в СССР, США, Франции, Великобритании, ГДР, Чехословакии, Болгарии, Венгрии, Канаде, Японии, ФРГ, Италии и др. странах.
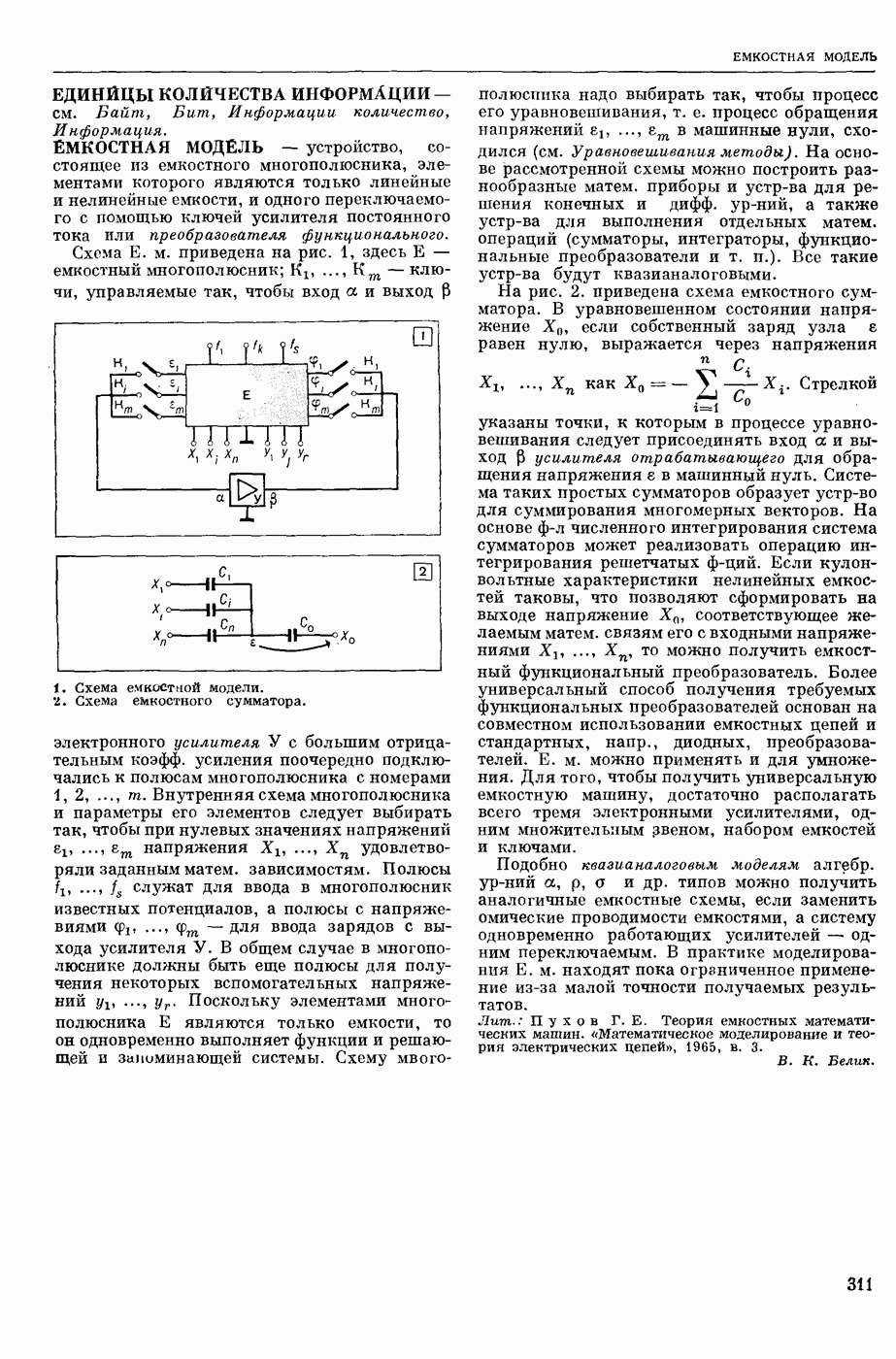
В системах М. п. (в узком понимании этого термина) обычно различают следующие составные части: слояарь (см. Словарь автоматический), алгоритм и его реализующую программу. Первоначально лингвистические сведения о двух языках, участвующих в переводе, не выделяли как нечто самостоятельное, т. е. они не составляли описания языка, отдельного от правил перевода. Данные о языках были разбросаны по тем или иным правилам алгоритма, причем в одном правиле могли использоваться сведения очень разнородного характера.
Со временем стало принятым различать: сведения о языке, форму записи этих сведений, т. е. используемый формализм, и собственно алгоритм, т. е. правила работы, сформулированные применительно к принятому формализму и не зависящие от конкретного запаса лингвистических сведений. Однако, несмотря на то, что такое деление общепринято, и теперь еще нередко термин «алгоритм М. п.» употребляют, подразумевая и собственно алгоритм и сведения о языке, записанные в принятой форме. При таком широком понимании слова «алгоритм» именно алгоритм и является осн. частью системы М. п., поскольку словарь и программа им определяются. Поэтому, говоря о разных подходах к построению систем М. п., в первую очередь имеют в виду разные подходы к построению алгоритмов М. п. В работах по созданию алгоритмов перевода можно выделить (несколько приближенно и условно) три этапа и говорить соответственно о системах М. п. 1-го, 2-го и 3-го поколений.
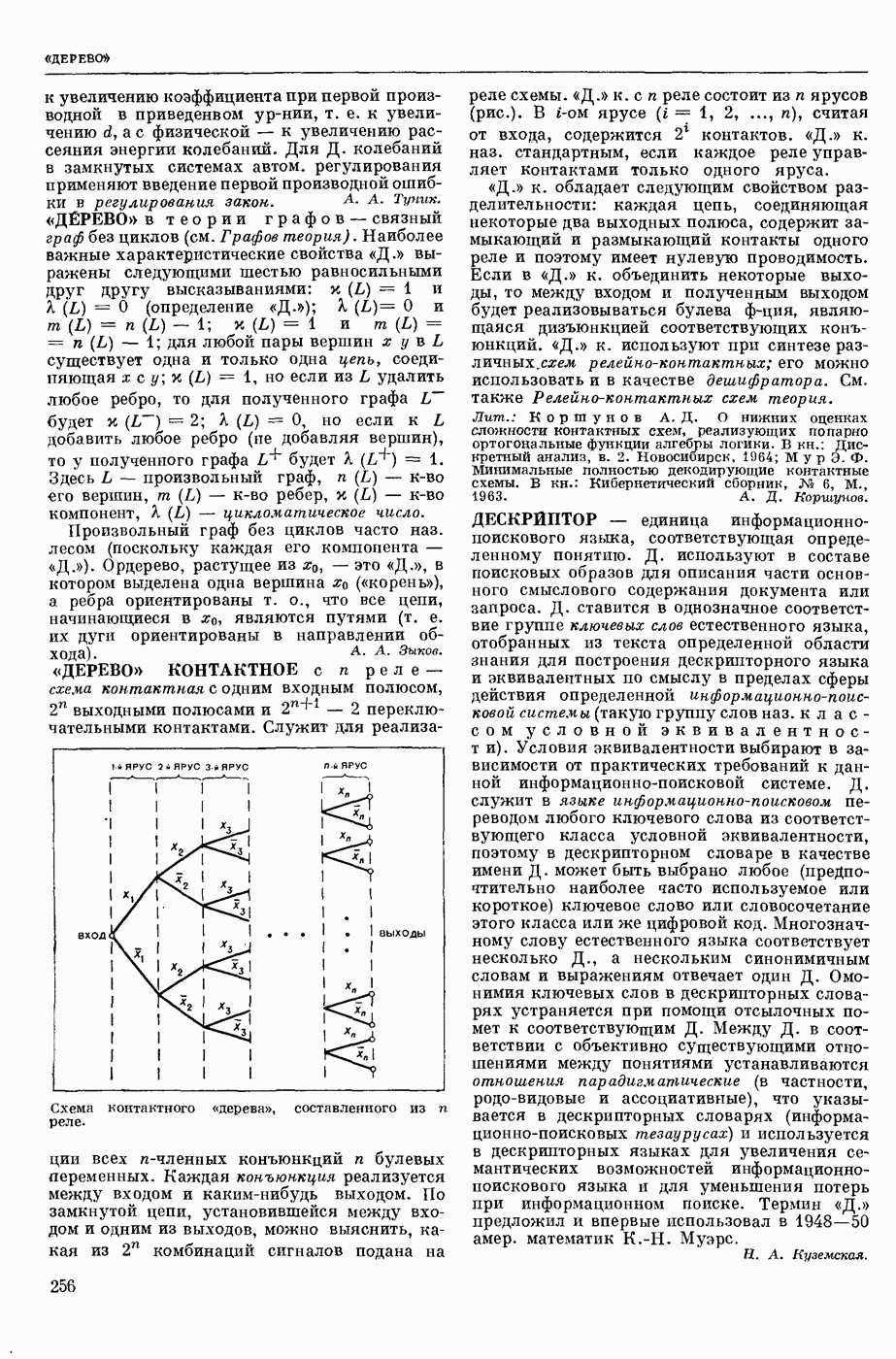
В системах 1-го поколения алгоритмы имели бинарный характер, т. е. были рассчитаны только на два языка, участвующие в переводе. При этом анализ переводимого текста был ориентирован на свойства выходного языка, т. е. при обработке текста на входном языке ставилась задача выяснения данных не только о переводимом тексте, но сразу и о переводящем; иначе говоря, анализ и синтез довольно тесно переплетались друг с другом. Как правило, такие алгоритмы были последовательно одновариантными, т. е. они имели конечной целью получение одного варианта перевода для каждой фразы и, кроме того, для всех тех случаев, когда возникала необходимость сделать выбор из некоторого круга возможностей, предлагался рецепт выбора одной из них. При этом в одних алгоритмах возвращение к месту, где однажды решение было принято, было уже невозможно, в других предусматривались способы отметки таких сомнительных мест с тем, чтобы к ним можно было вернуться, если по некоторым признакам удавалось установить неудовлетворительность результата. В системах 1-го поколения описание свойств языков не было выделено в самостоятельную часть.
В системах 2-го поколения произошло отделение анализа от синтеза в следующем смысле. Анализ стал независимым от языка, на который переводят, его целью стало выяснение строения переводимого текста и записи результата в виде некоторого представления этого текста в определенной форме (см. Синтаксический анализ автоматический естественных языков). Синтез стал независимым от языка, с которого переводят, его целью стало развертывание заданного ему представления в текст на выходном языке. Системы 2-го поколения уже не ориентированы на получение одного варианта и принятие одного решения в каждом сомнительном случае. На смену такому подходу пришел многовариантный анализ, т. е. подход, основанный на переборе возможностей и разветвлении процесса (см. о фильтрах в статье «Синтаксический анализ автоматический»), Анализ и синтез в этих системах Стали подразделяться на уровни, соответственно расчленению уровней в языке. Кроме того, в системах 2-го поколения произошло упомянутое выше деление алгоритма на собственно алгоритм и на данные о языке, записанные с использованием определенного формализма. В большинстве своем системы 2-го поколения. Это системы, в которых основное внимание уделено этапу синтаксического анализа, завершающему анализ входного текста. Синтез в них играет в некотором смысле вспомогательную роль, он обычно намного беднее и проще анализа.
К системам 3-го поколения можно отнести системы, в которых, во-первых, появляются Этапы семантического анализа и синтеза; во-вторых, меняется соотношение между анализом и синтезом: анализ перестает быть центром системы, степень сложности и «нагрузка» анализа и синтеза выравниваются, синтез также становится многовариантным. Последнее означает, что на смену нацеленности синтеза на один вариант приходит нацеленность на построение многих вариантов текста по заданной структуре с использованием перефразирования (см. Модель «смысл <-> текст»), В остальном системы 3-го поколения сохраняют многие черты систем 2-го поколения: независимость анализа и синтеза, их расчлененность на уровни, ориентация на переборный (фильтровый) подход в
анализе, выделение собственно алгоритма и наличие сформулированных формализмов для записи сведений о языне (в частности, использование грамматик формальных).
Процесс перевода текста машиной подразделяется на ряд этапов. В разных системах М. п. они несколько различны, однако можно представить некоторую общую схему, которая достаточно характерна для систем 2-го и 3-го поколений (системы 1-го поколения в настоящее время не строят).
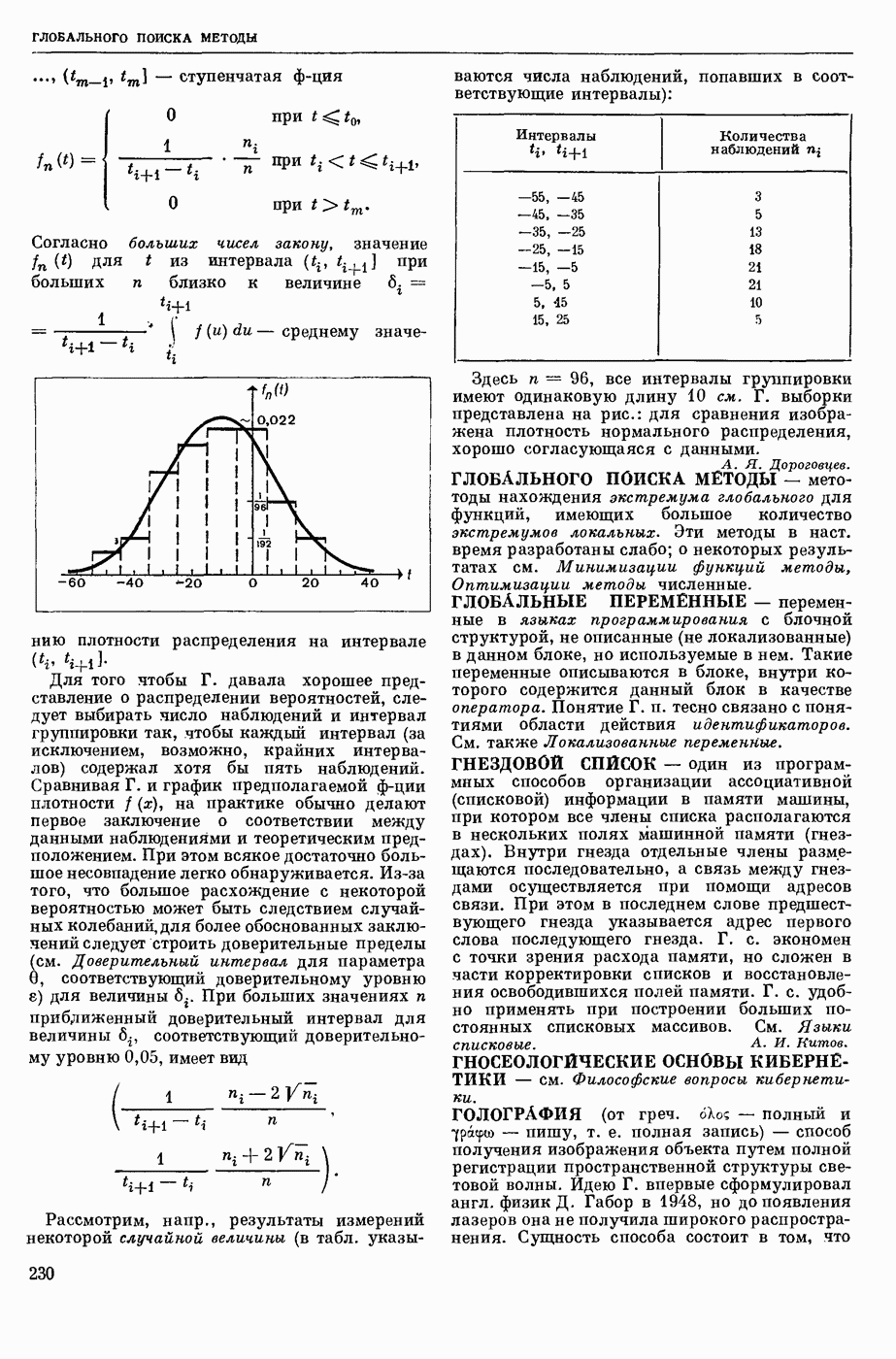
Общую схему и встречающиеся отклонения можно описать так. В некоторых случаях началу машинной переработки текста предшествует подготовительный этап. Он может включать в себя либо достаточно сложное предредактирование текста, либо только некоторую несложную разметку (напр., введение спец. знаков для формул и т. п.). Текст поступает в машину в закодированном виде. При полной автоматизации перевода ввод будет осуществляться при помощи читающих автоматов. В настоящее время ввод осуществляется путем перекодирования текста на перфокарты или записи его на ленту магнитную и т. п.
Первым этапом машинной переработки текста обычно является этап поиска слов в автоматическом словаре, хранящемся в запоминающем устройстве машины. Затем следует этап обработки словосочетаний, непереводимых пословно. В случае, если используется словарь основ, после этих двух этапов начинается морфологический анализ. Затем следует этап синтаксического анализа, а после него — этап семантического анализа, которым и завершается анализ. В результате анализа получается некоторое представление переводимого текста, записанного на языке - посреднике. Синтез переводящего текста содержит этапы, соответствующие перечисленным этапам анализа, но они следуют в обратном порядке. Так, синтез начинается с семантического синтеза, затем следует этап синтаксического синтеза, потом этап морфологического синтеза, который и завершает машинную обработку текста и после которого машина печатает полученный перевод (после окончания машинной обработки текста может еще следовать этап постредактирования полученного перевода человеком).
Возможны следующие отклонения от общей схемы, приведенной выше. В том случае, когда в словаре содержатся не основы слов, а словоформы целиком, этап морфологического анализа отсутствует. В некоторых системах перевода, где используется словарь основ, этап морфологическего анализа осуществляется первым, он приводит к отсечению от слов окончаний и получению основ, которые после этого отыскиваются в словаре основ. Этапов семантического анализа и синтеза в системах 1-го и 2-го поколений нет, в полном объеме их пока нет ни в одной системе, хотя необходимость их осознают в настоящее время все исследователи. В некоторых системах имеются те или иные разделы, которые представляют собой попытки семантической переработки текста (такова, напр., система русско-французского М. п., созданная в Гренобльском ун-те во Франции).
Наряду с этим есть работы, в которых предлагается начинать семантический анализ без предварительного синтаксического. В алгоритмах между анализом и синтезом есть и промежуточный этап — преобразование, целью которого является переделка результата анализа, т. е. представления переводимого текста, полученного при анализе, в представление, которое может быть исходным материалом для синтеза, т. е. в такое представление, в котором учтены особенности выходного языка (такова, напр., система англо-русского перевода, разработанная в Ленинградском ун-те). В большинстве существующих систем объектом работы является одна фраза текста, причем даже для одной фразы каждый из названных выше этапов может повторяться несколько раз (столько, сколько вариантов фразы приходит к этому этапу).
Работы в области М. п. в широком смысле можно разделить на работы, направленные непосредственно на создание систем перевода (создание словарей, грамматик, собственво алгоритмов) и их реализацию на ЦВМ, и работы, имеющие целью глубокую теор. разработку тех или иных проблем матем. или лингвистического характера, решить которые нужно для создания эффективных систем перевода.
Непосредственная разработка систем М. п. требует от лингвистов решить следующие задачи: 1) определить запас лингвистических сведений, который будет использоваться в системе (напр., установить критерии, по которым будет происходить классификация слов, и получить классы слов в соответствии с этими критериями); 2) создать словарь, т. е. отобрать словник и приписать словарным единицам наборы признаков; и 3) создать подробные грамматики для всех уровней языка, в частности, сформулировать лингвистические требования (фильтры, правила предпочтения) к каждому уровню представления текста. Проблему выделения разных уровней представления текста в процессе преобразования должны решать математики и лингвисты совместно.
Математики решают следующие задачи: 1) создают формализмы для описания каждого уровня представления текста, или иначе говоря, для описания входных и выходных данных каждого этапа; 2) изучают строение собственно алгоритмов в системах перевода и разрабатывают эффективные алгоритмы для всех этапов процесса перевода, т. е. для перехода от уровня к уровню; и 3) разрабатывают спец. языки для описания этих алгоритмов.
Главными проблемами реализации систем М. п. на ЦВМ являются следующие.
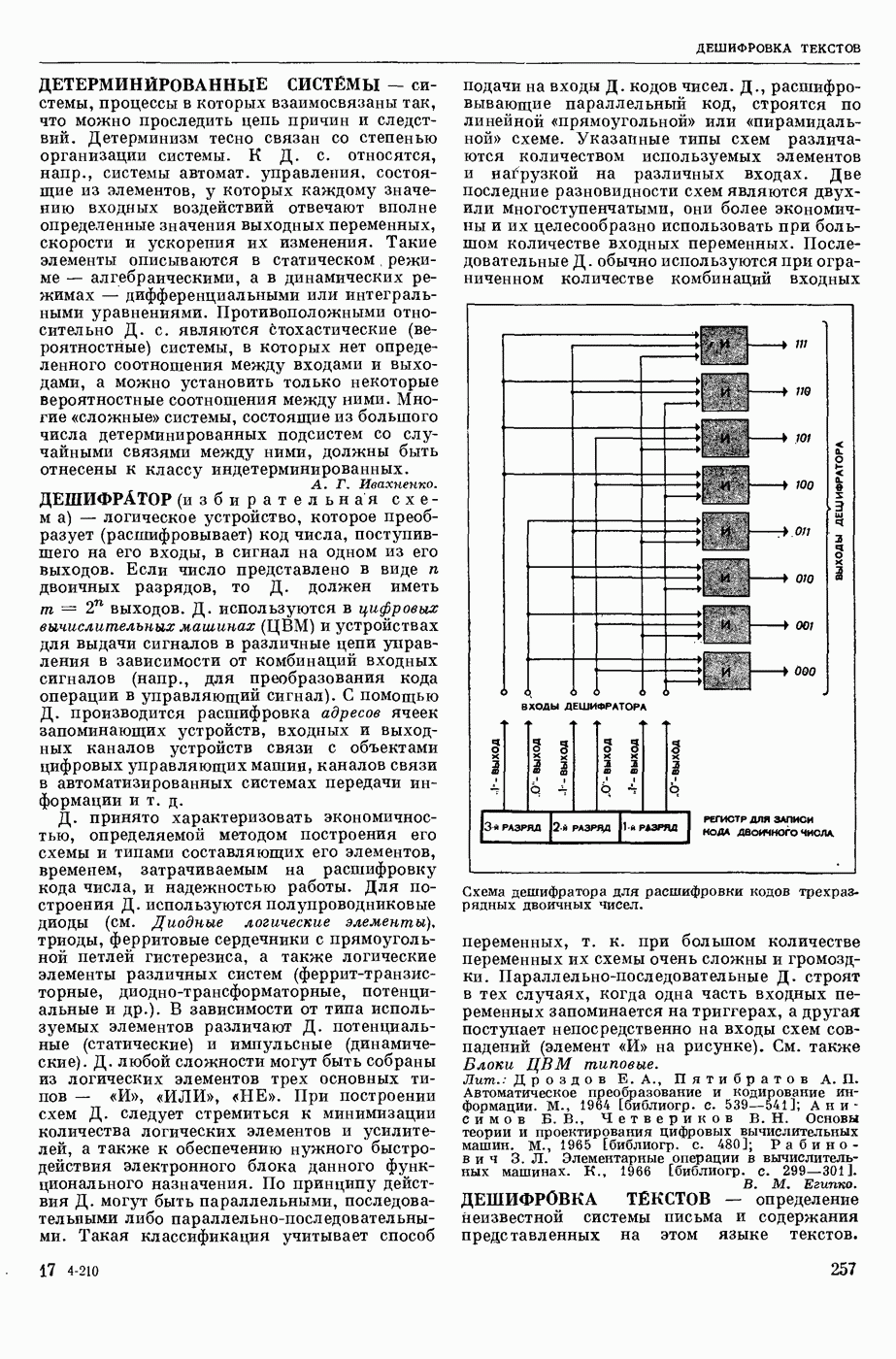
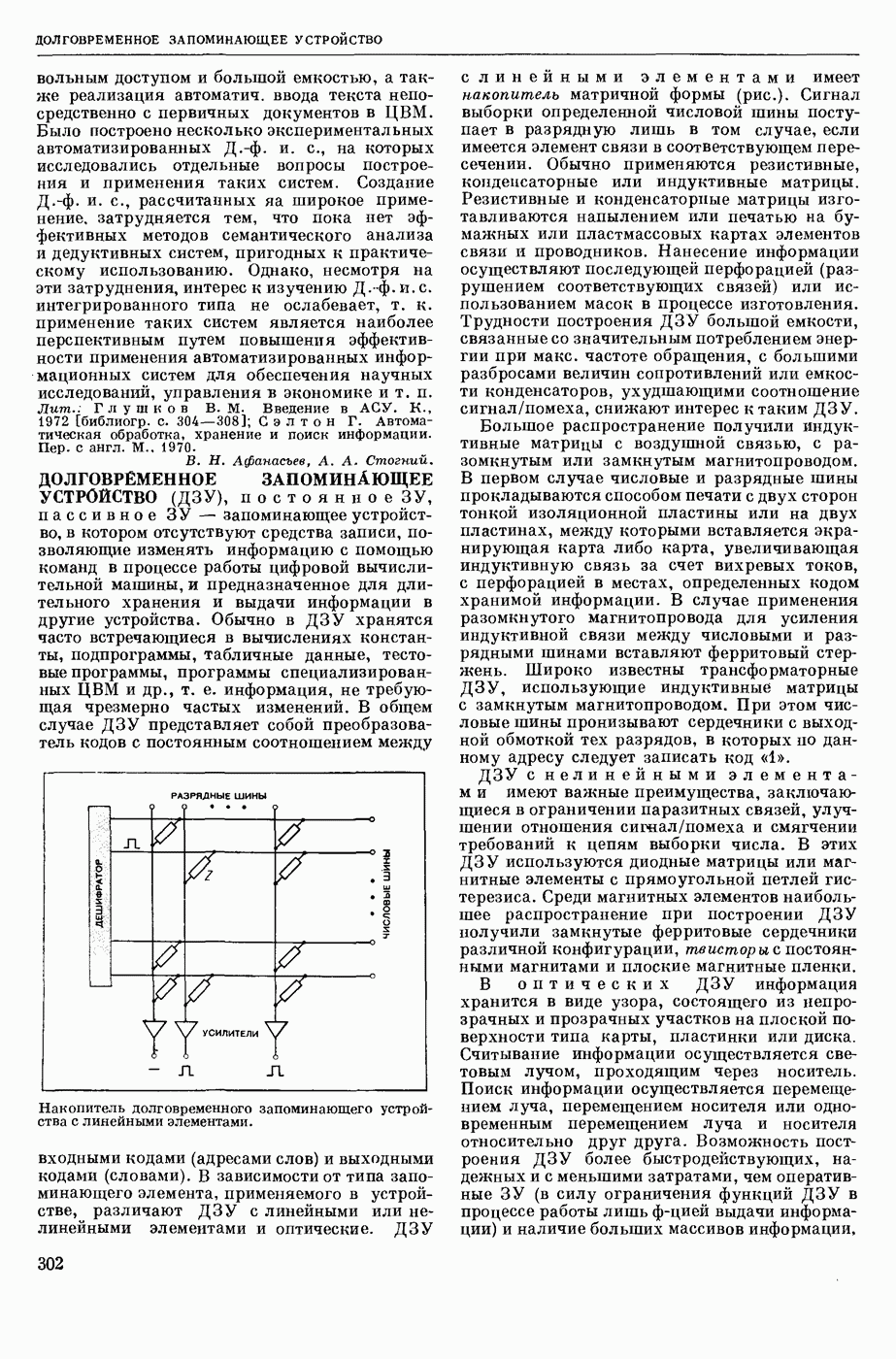
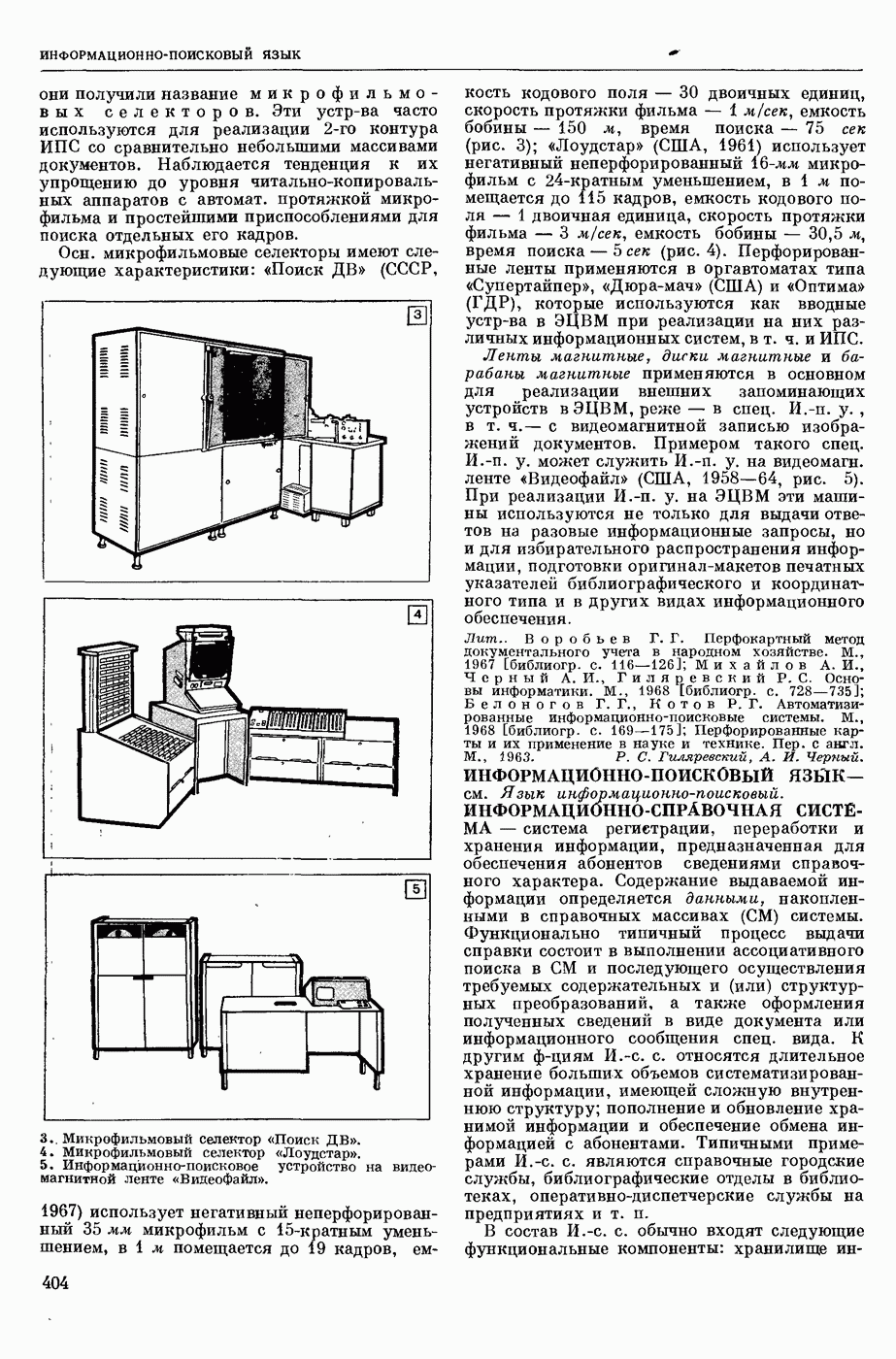
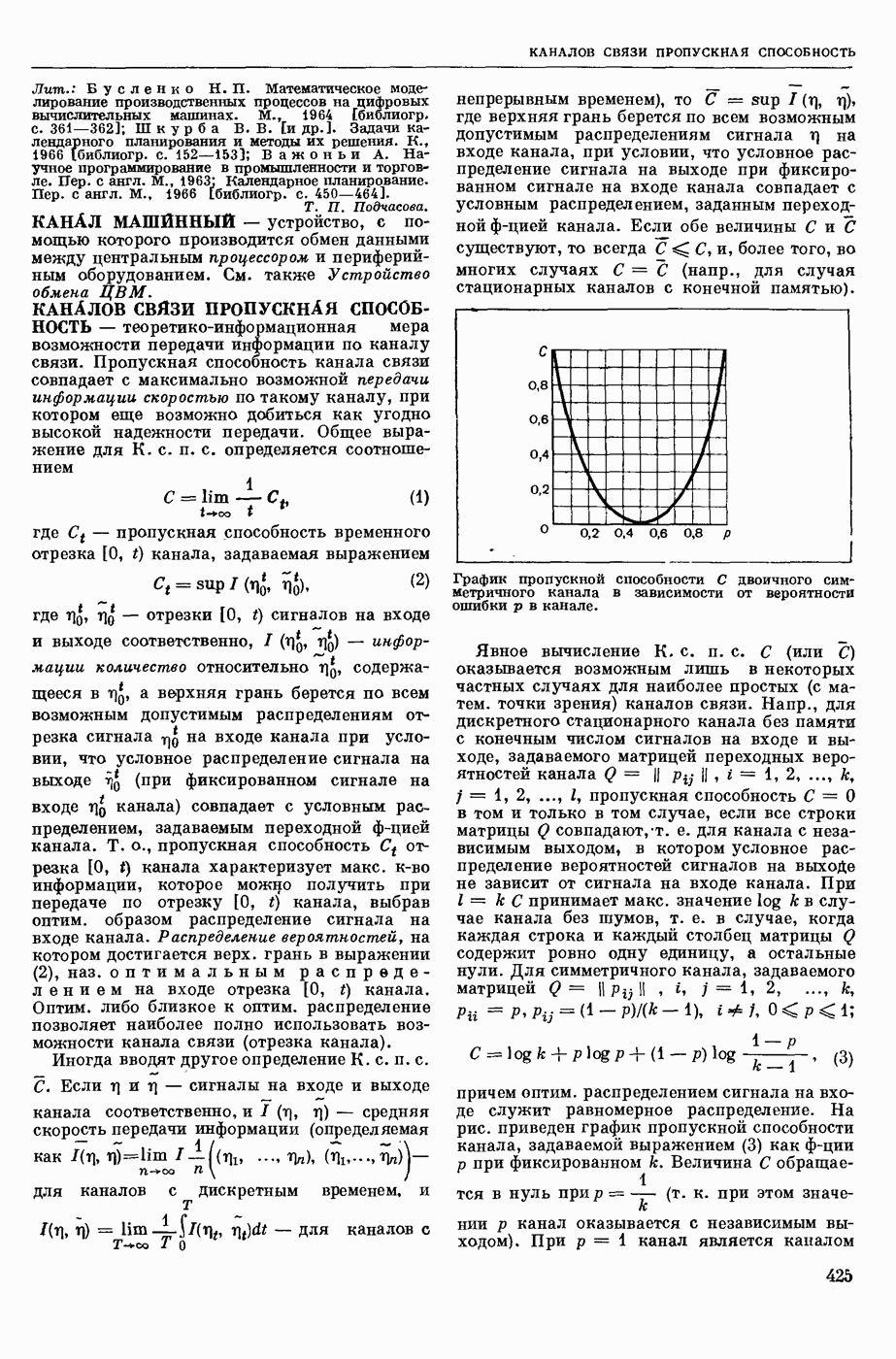
Вопросы кодирования информации. Сюда относится, во-первых, кодирование информации в словарях. Ввиду того, что большие автомат, словари содержат тысячи слов с подробной информацией о них, эти словари обычно хранятся во внешних, медленно
действующих запоминающих устройствах (напр., на магнитных лентах или барабанах). Поэтому приходится думать о таких методах кодирования, которые были бы удобны для работы системы перевода и вместе с тем не приводили бы к большим затратам машинного времени на обращение к этим медленно действующим запоминающим устройствам. Во-вторых, на разных этапах работы систем М. п. удобно иметь разные формы записи и кодирования перерабатываемого материала, причем тут важно найти такие способы кодирования, чтобы одновременно было удобно работать на каждом этапе, и вместе с тем, чтобы переход от одного способа кодирования к другому не требовал большой работы машины.
Вопросы программирования. Реализация систем М. п. требует разработки специальных методов программирования. Это связано, во-первых, с тем, что алгоритмы перевода имеют весьма специфическую и очень сложную логическую структуру. Этим они существенно отличаются от вычисл. алгоритмов, на которые ориентировано как обычное программирование (включая создание языков программирования типа АЛГОЛ, ФОРТРАН и др.), так и само конструирование ЦВМ. Во-вторых, общим свойством всех систем М. п., осуществляемых до сих пор на ЦВМ, является то, что все они открыты, т. е., что системы М. п., даже реализованные на машине, подвергаются доработке, исправлению и расширению. Больше того, часто значительная доля самой разработки алгоритма осуществляется в процессе экспериментов, проводимых на машине. Это объясняется тем, что переводческие системы очень сложны, число учитываемых в них факторов очень велико и создать «на бумаге» полностью готовый алгоритм, в котором все согласовано и проверено, очень трудно; проверить алгоритм и его отдельные части на больших массивах текста можно только в процессе машинного эксперимента. При этом обычно выясняется, что же именно в алгоритме надо изменить или дополнить. Поэтому надо уметь быстро и легко менять программы, реализующие алгоритм М. п. Указанные две особенности ведут к необходимости разрабатывать для систем М. п. специальные языки различного назначения: для описания алгоритмов, для описания программ и др.
Исследования, направленные на построение систем перевода и на разработку различных лингвистических проблем в связи с построением таких систем, вызвали к жизни совершенно новые подходы в лингвистике (см. Лингвистика прикладная). Построение систем М. п. дало возможность практически опробовать лингвистические теории, поскольку оно потребовало такого описания языковых фактов, которое дало возможность создать алгоритмическую имитацию владения языком хотя бы в процессе перевода с одного языка на другой; эта алгоритмическая имитация проверяется машинным экспериментом. Начавшиеся на базе М. п. пересмотр и упорядочение системы лингвистияеских понятий и теорий в сочетании с требованием высокой логико-матем. отчетливости привели к созданию нового научного направления — построения моделей языка (см. Языка модели аналитические, Языка модели математические).
Связь исследований в области М. п. с общекибернетической и, в частности, математико-киберн. проблематикой определяется следующими факторами. Кибернетика изучает процессы управления и строение управляющих систем с помощью методов точных наук. При этом кибернетика изучает и управляющие системы, возникшие в природе (напр., нервную систему), и управляющие системы, созданные в процессе существования человечества (напр., экономику), и искусственно созданные модельные управляющие системы. Проблематика кибернетики в значительной степени формируется вокруг единой задачи — выяснения соотношений между возможностями человеческого мышления и машин в процессах переработки информации. Дело в том, что всякий процесс управления представляет собой процесс переработки информации, записанной на некотором языке (естественном или искусственном). Решение указанной выше задачи предполагает передачу машинам возможности пользоваться человеческой речью, т. е. перерабатывать тексты на естественных языках.
Задача автомат, перевода текстов с одного естественного языка на другой является частным случаем подобной переработки, причем в некотором смысле наиболее простым случаем. Кроме того, многие реальные управляющие системы, изучаемые кибернетикой, имеют дело с информацией, записанной на естественных языках, и при переработке этой информации возникают те же проблемы анализа и синтеза текстов, что и при переводе. Такое наличие аналогий и родство информационных задач разной природы ведет к тому, что продвижение вперед в любой области машинной переработки текстов облегчает формулировку задач в М. п. и нахождение подходов к их решению, а продвижение в области М. п. означает продвижение к решению указанной выше общей задачи кибернетики. Этим определяется ценность М. п. как научного направления, в отвлечении от того, что автоматизация перевода будет практически полезна, т. к. она поможет человечеству справиться с чрезмерно возрастающим потоком информации в науке и различных областях хозяйственной и культурной деятельности людей.
Связь матем. проблематики М. п. с другими областями кибернетики определяется тем, что в М. п., пусть часто и не в точной постановке, возникают такие же проблемы, которые в том или ином виде возникают при всякой попытке построения алгоритмической имитации сложной природной системы переработки информации, а в точной постановке изучаются в дискретном анализе на модельных объектах (напр., функциях алгебры логики). Сюда относятся такие проблемы, как установление неразрешимости некоторых задач без переборов; проблема локализации переборов, выяснение
соотношений между переборными и одновариантными этапами в процессе переработки информации; выяснение соотношения трудоемкости и эффективности универсальных алгоритмов и ограниченных алгоритмов разной степени мощности, использующих определенную часть информационных связей между объектами изучаемой и моделируемой управляющей системы; установление априорных критериев для выяснения того, какой степени мощности алгоритм следует применить в том или ином конкретном случае; выяснение структуры всей массы задач относительно наиболее трудоемкой и т. д. Многие из этих задач для модельных объектов имеют точное решение. Хотя непосредственный перенос результатов решения этих задач в область М. п. невозможен, однако использование идей, на которых базируется решение, может быть полезно в машинном переводе.
Лит.: Лейкина Б. М. [и др.]. Система автоматического перевода, разрабатываемая в группе математической лингвистики ВЦ ЛГУ. «Научно-техническая информация», 1966, № 1; Машинный перевод. Пер. с. англ. М., 1957 [библиогр. с. 305-314]; OettingerA. G. Automatic language translation. Cambridge, 1960 [библиогр. с. 367—375]; Machine translation. Amsterdam, 1967; Мельчук И. А., Равич P. Д. Автоматический перевод. 1949—1963. Критико-библиографический справочник. М., 1967. О. С. Кулагина.