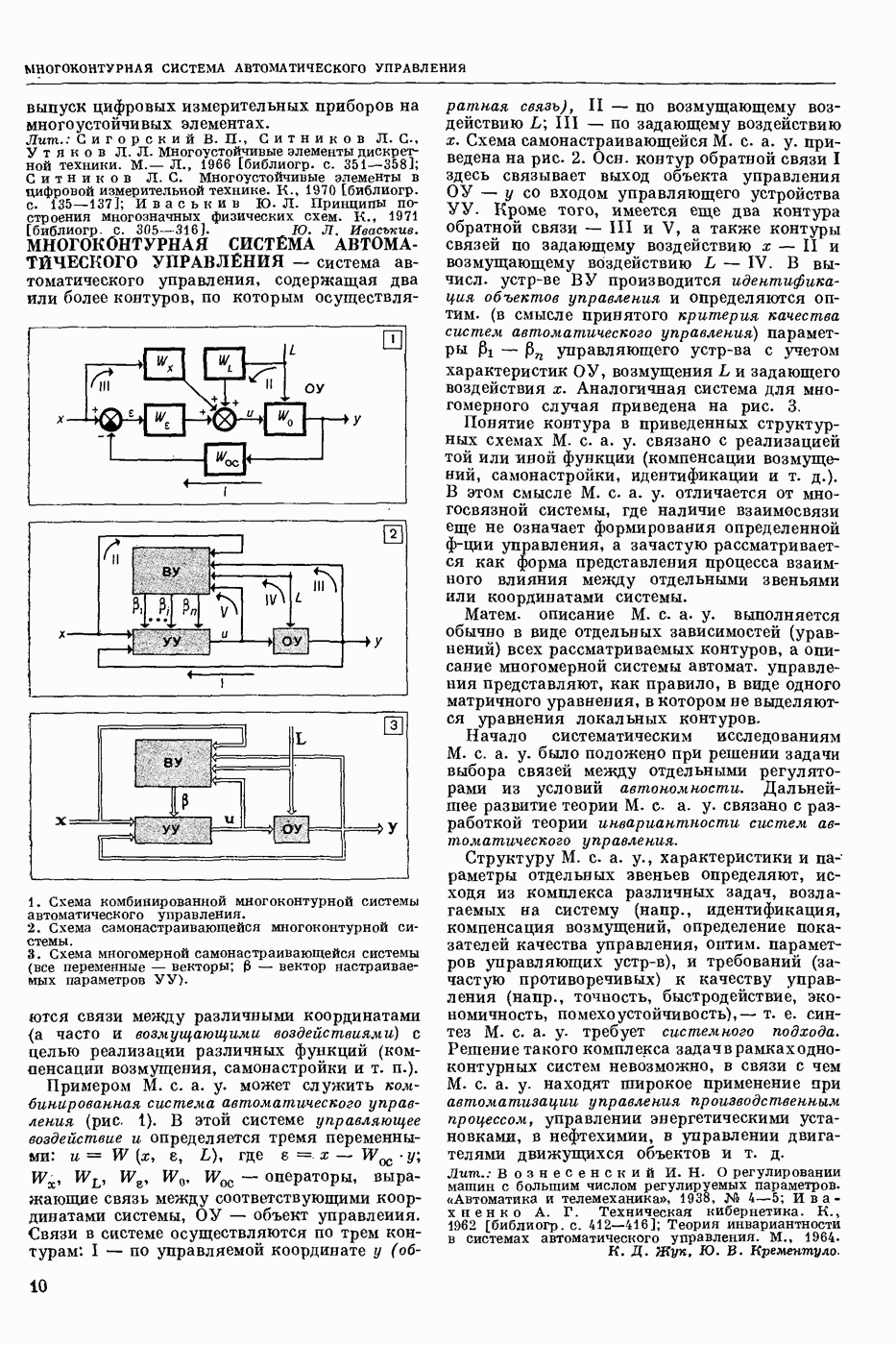
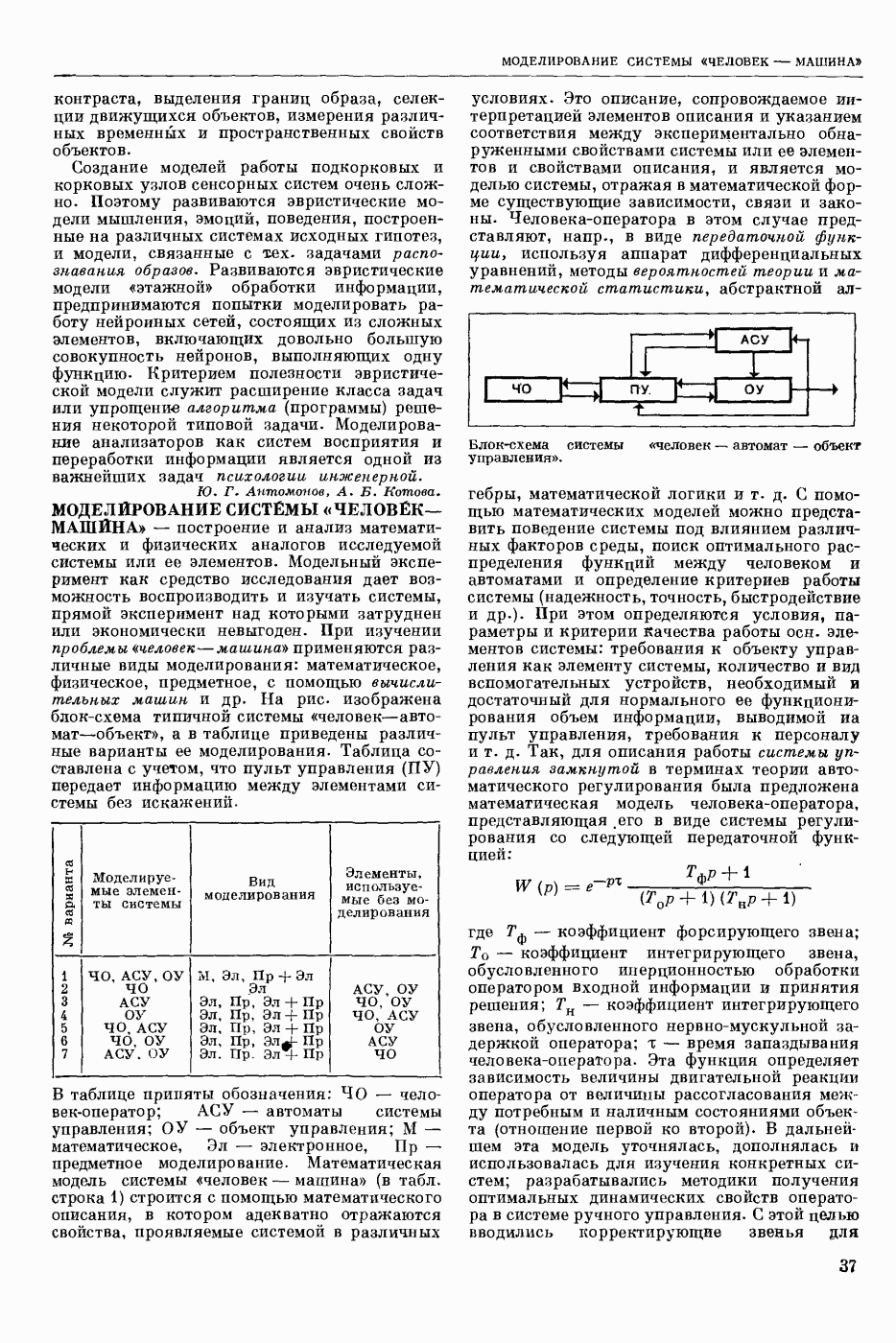
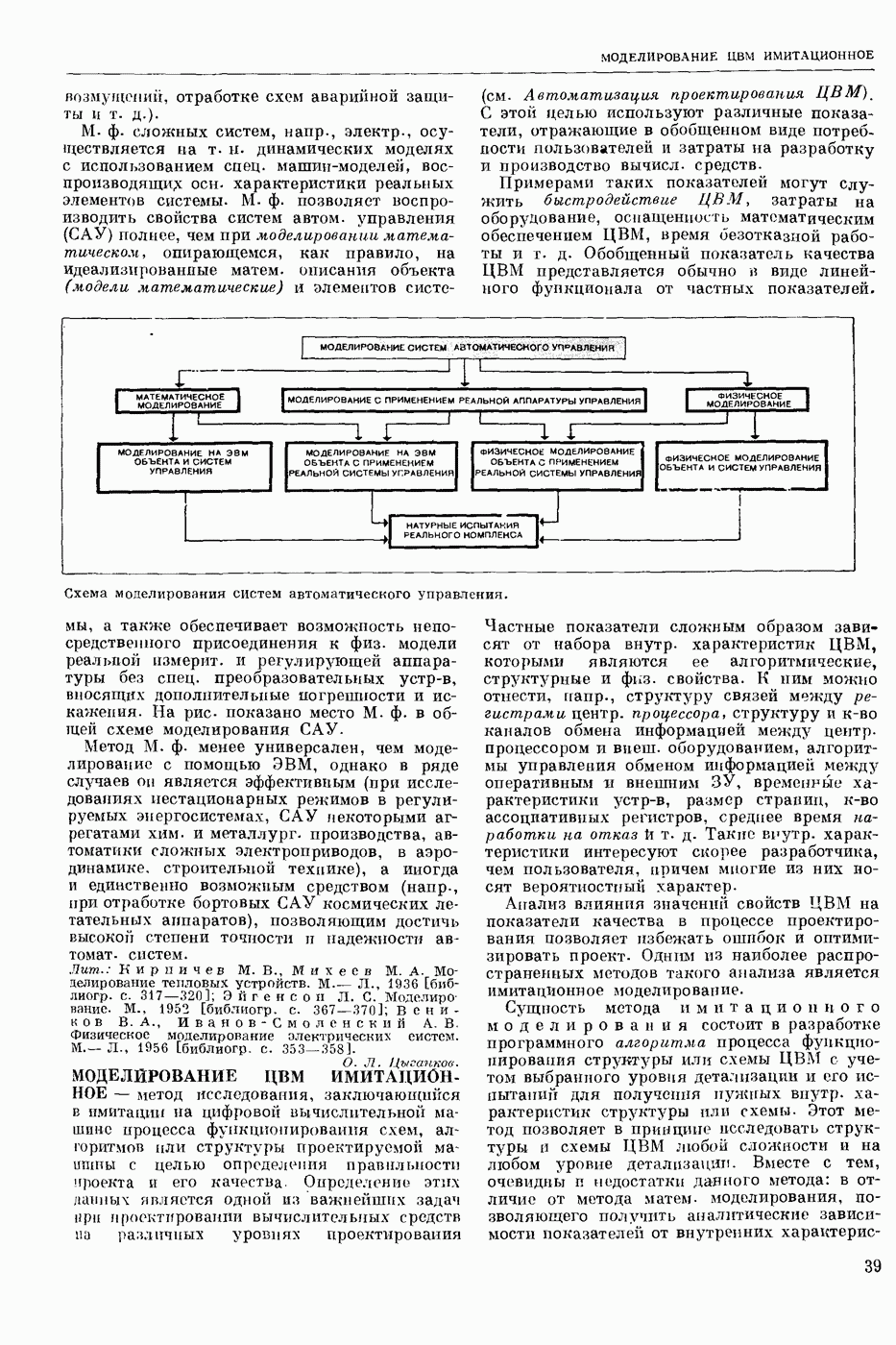
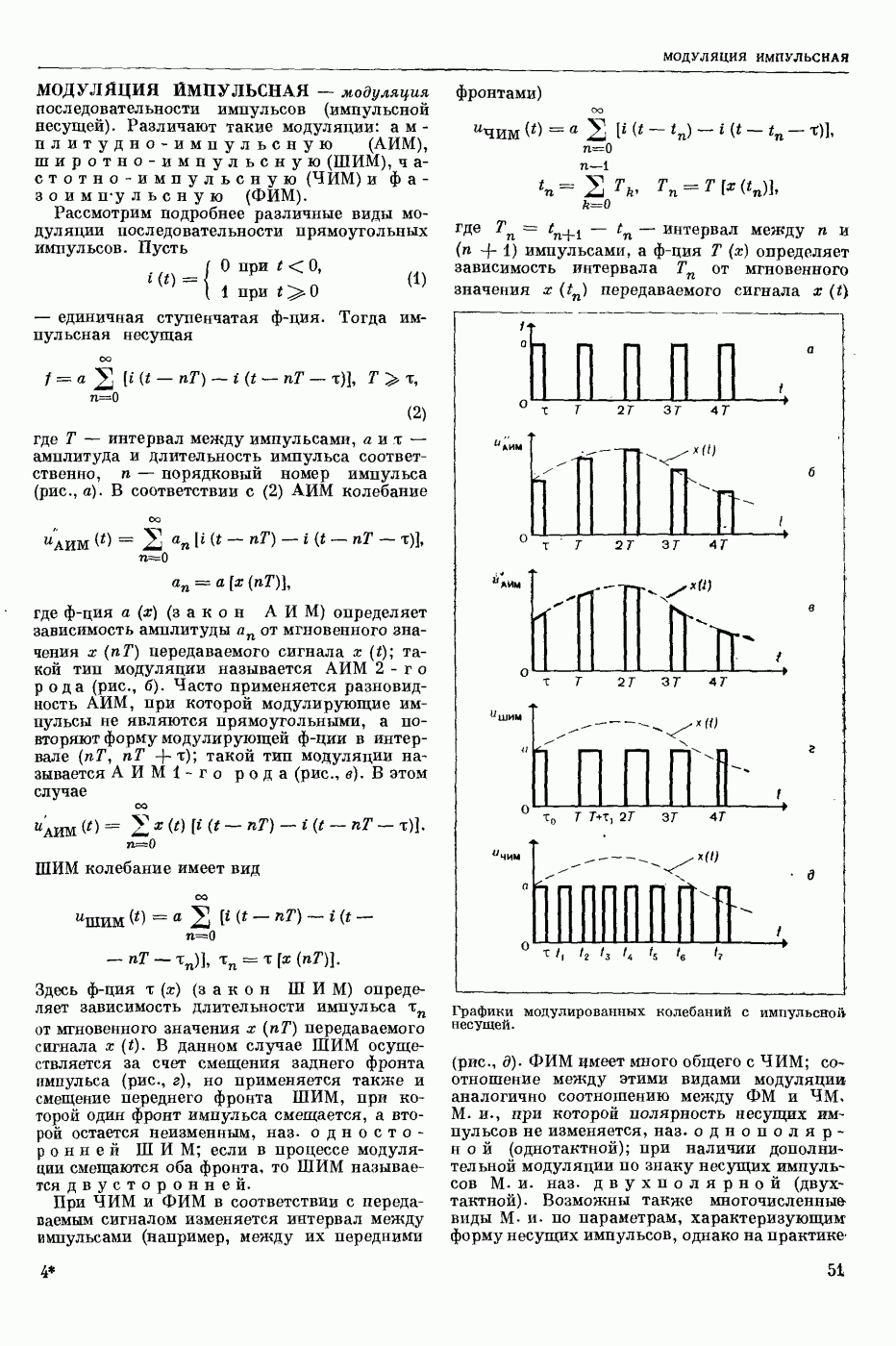
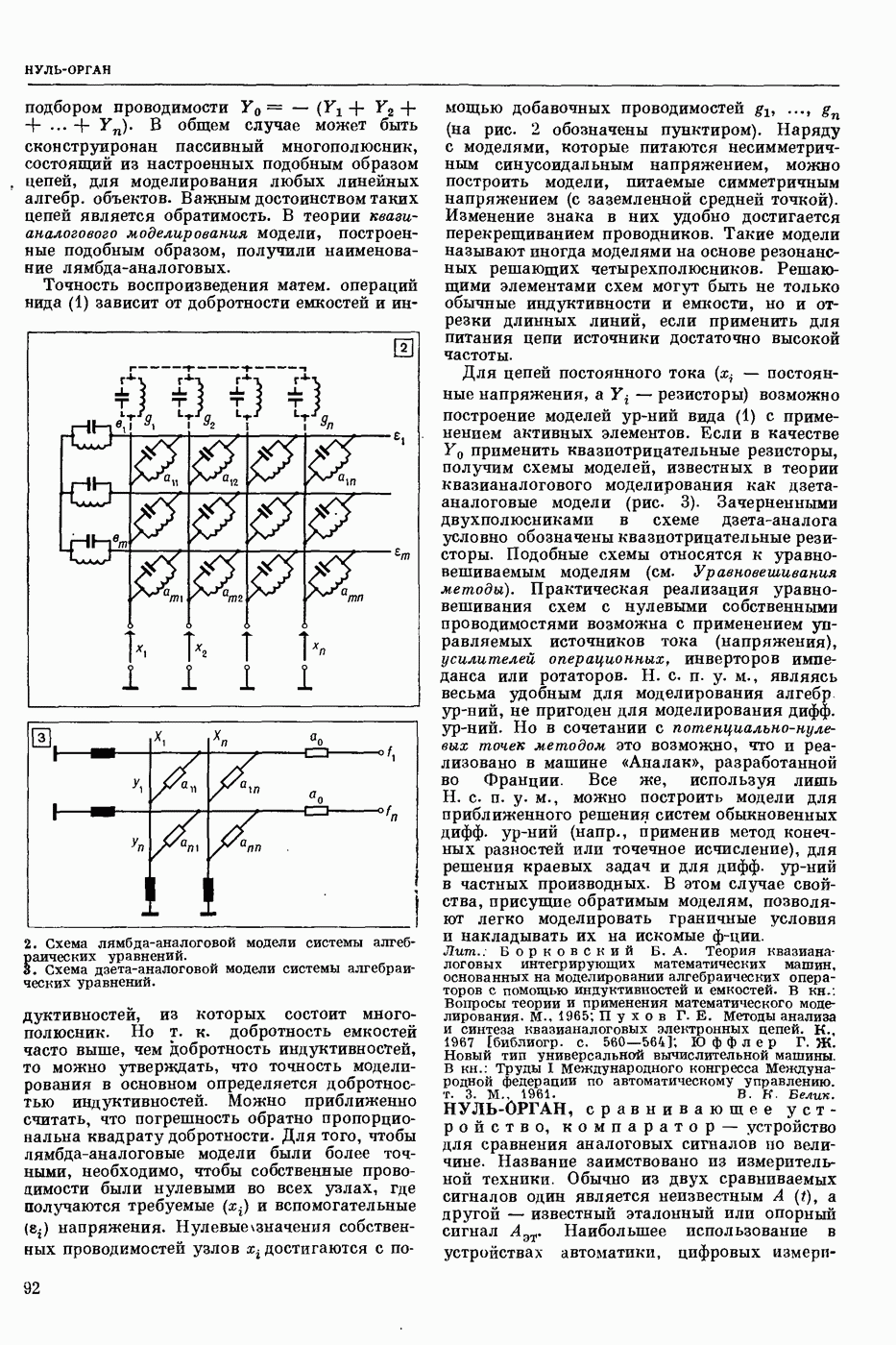
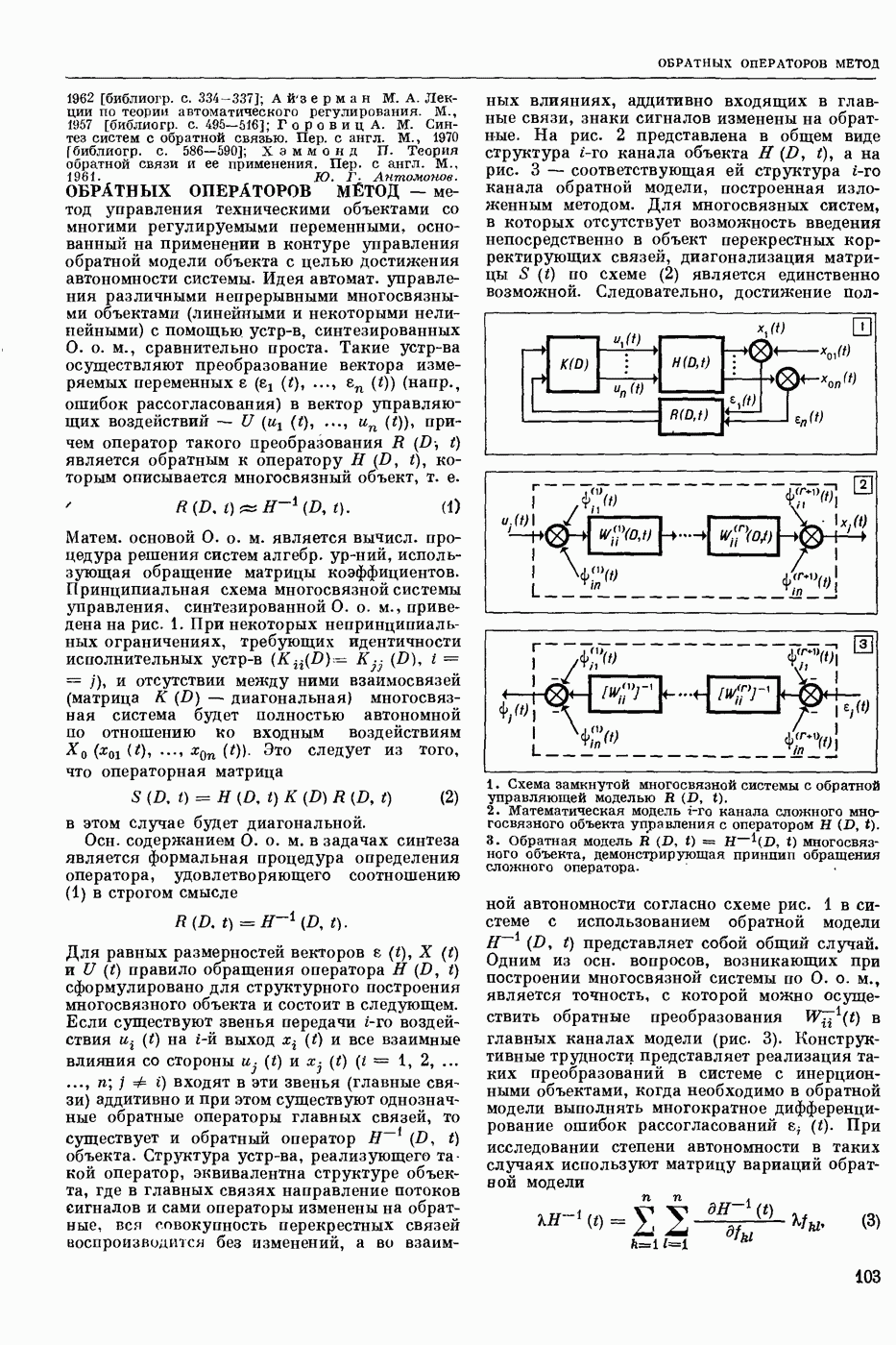
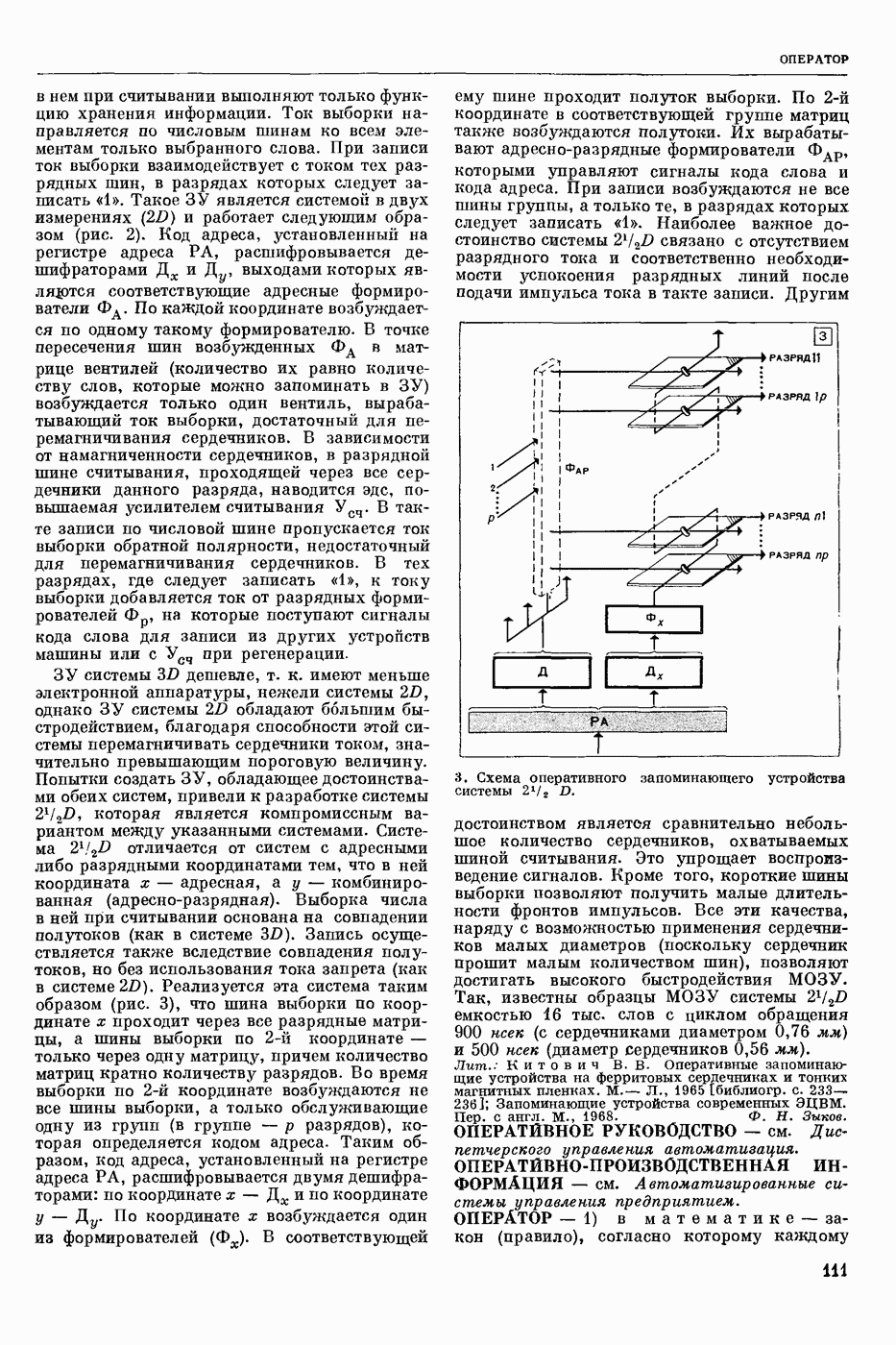
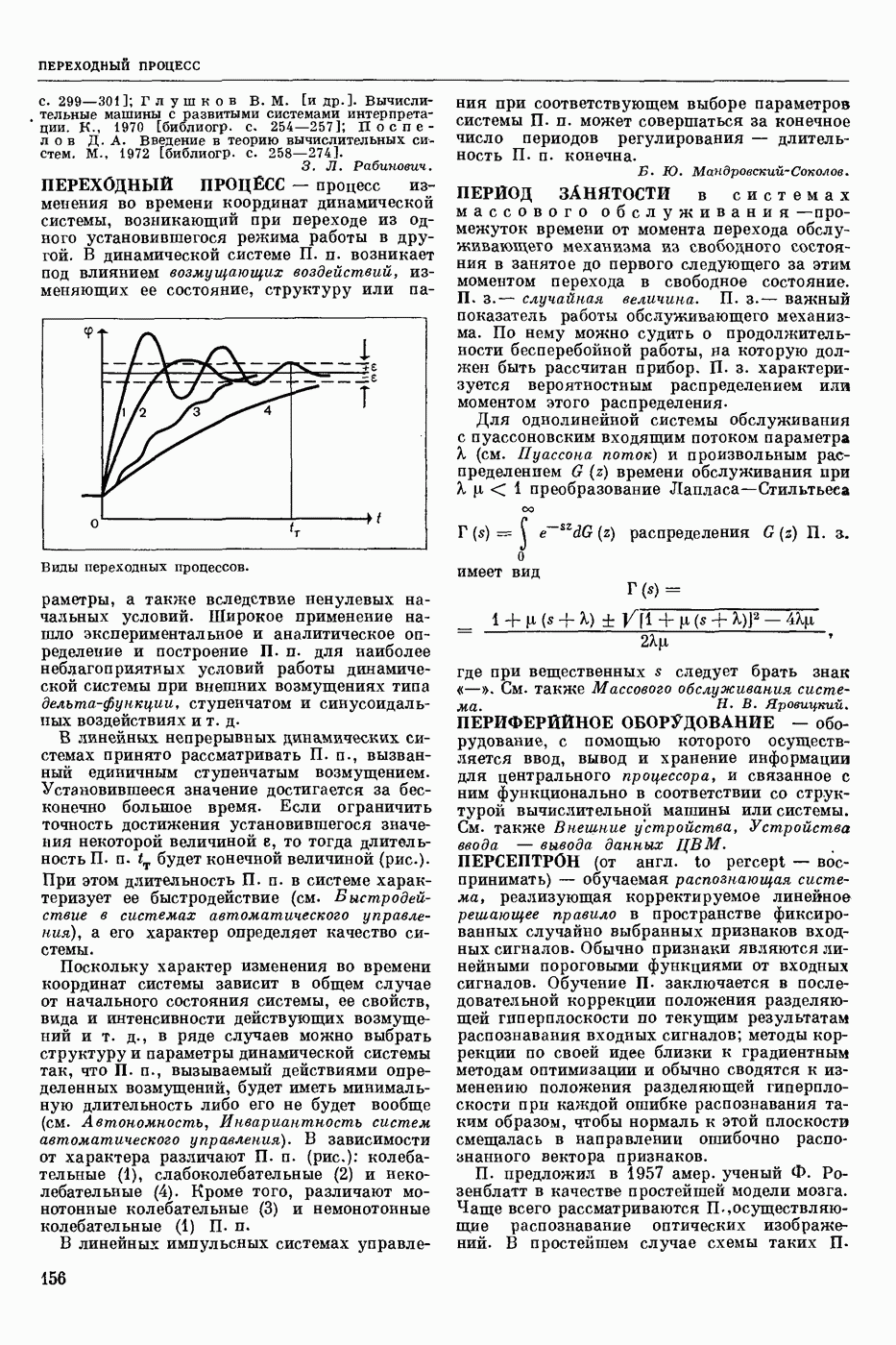
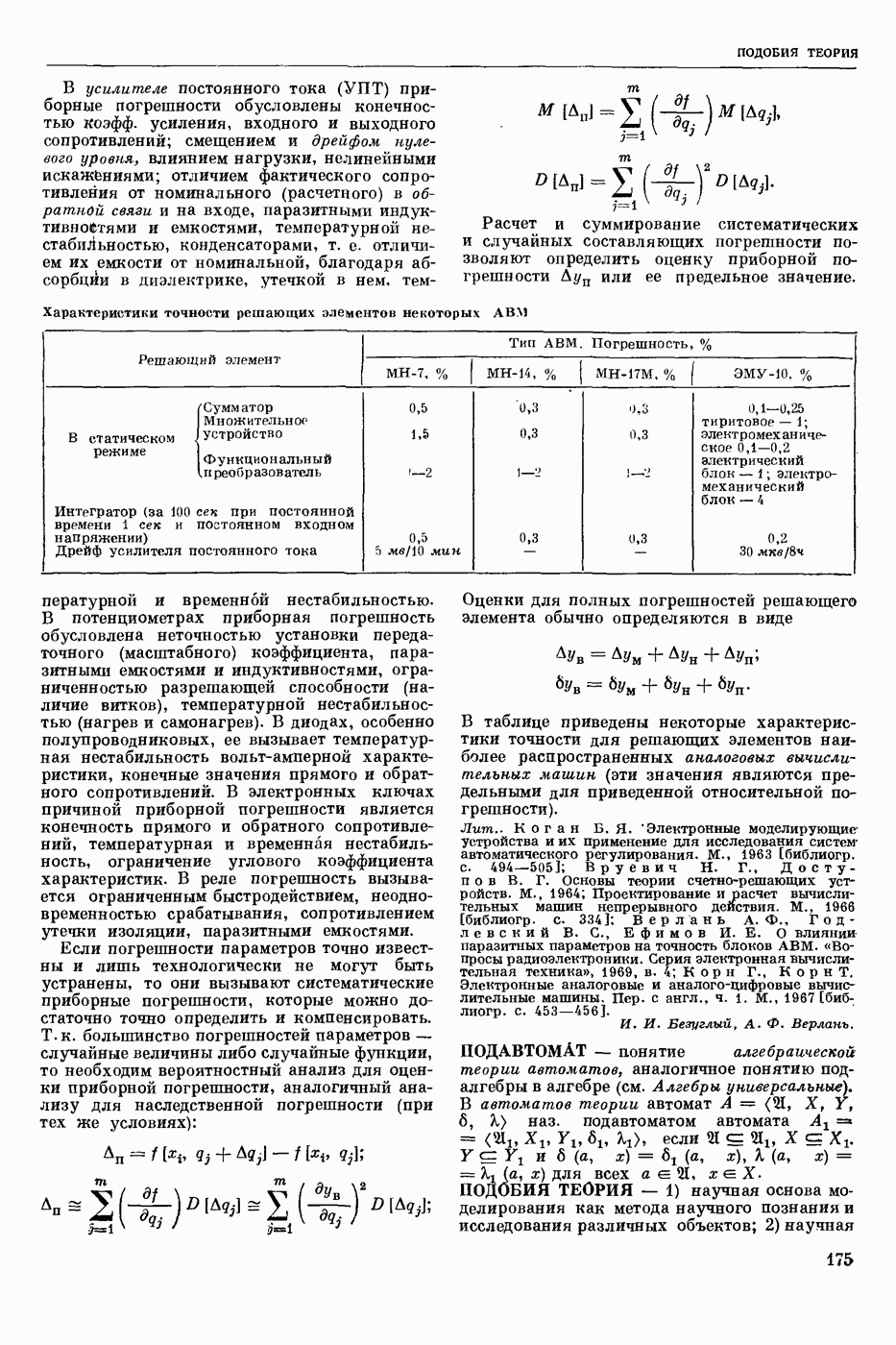
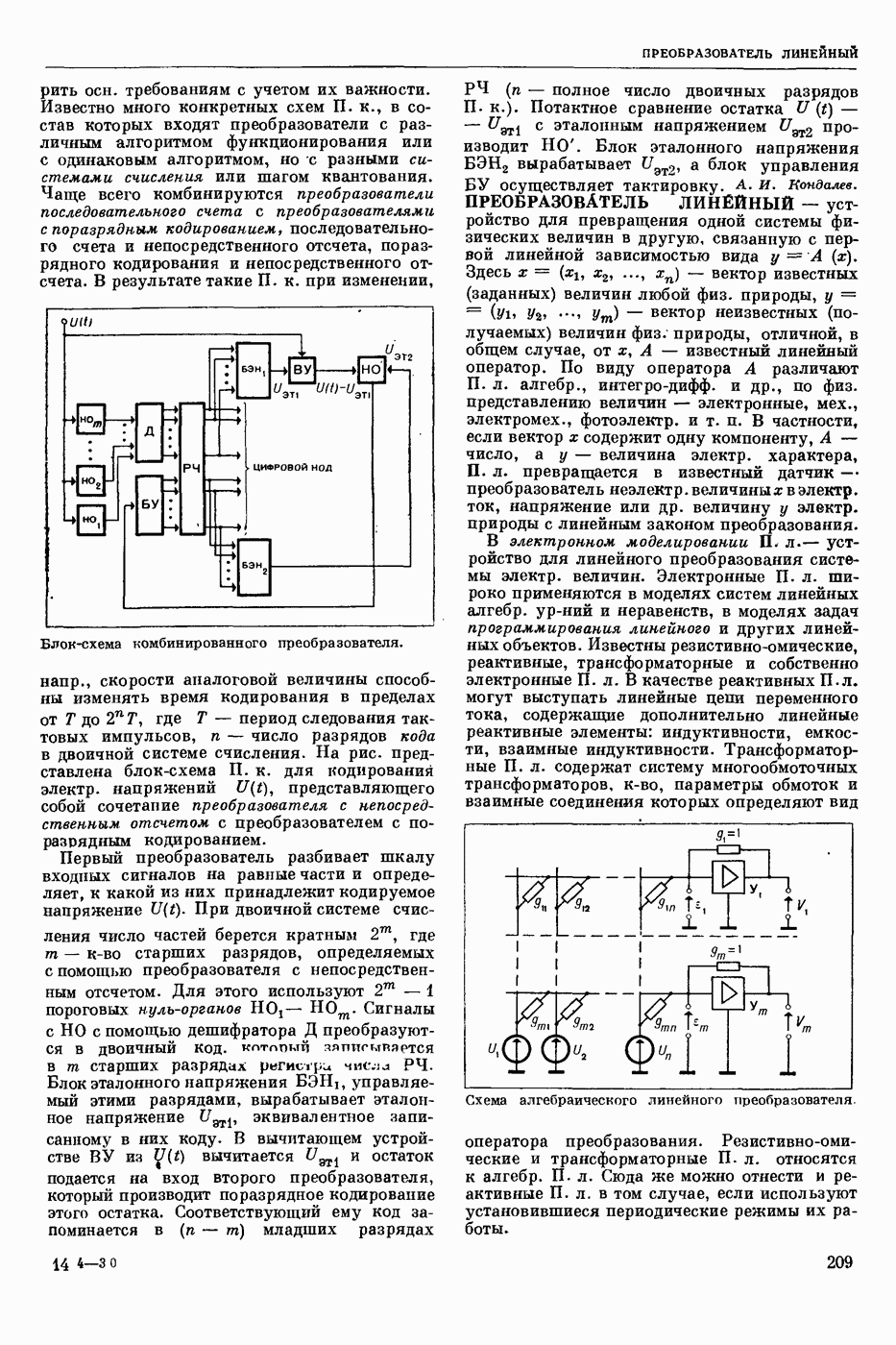
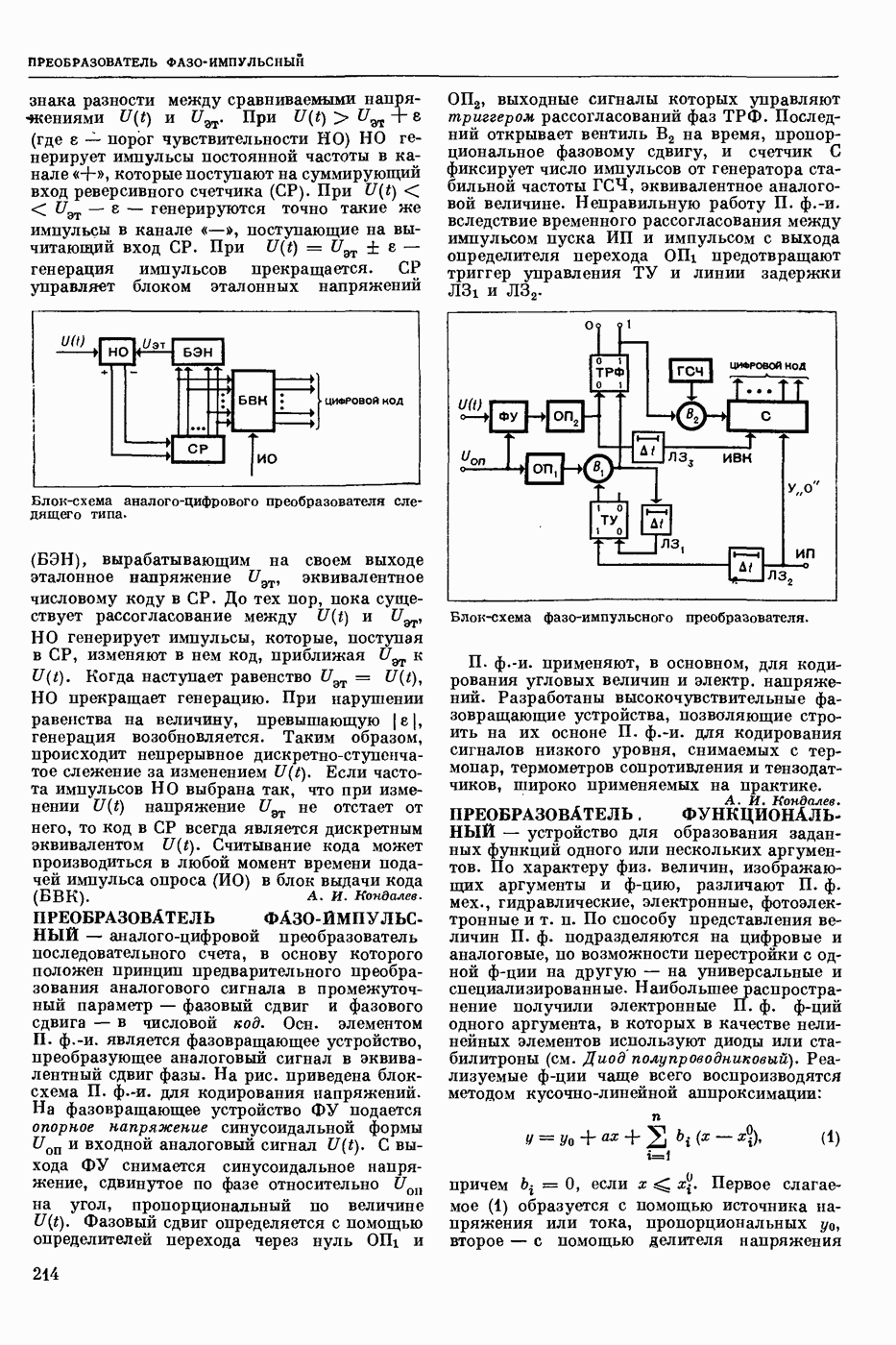
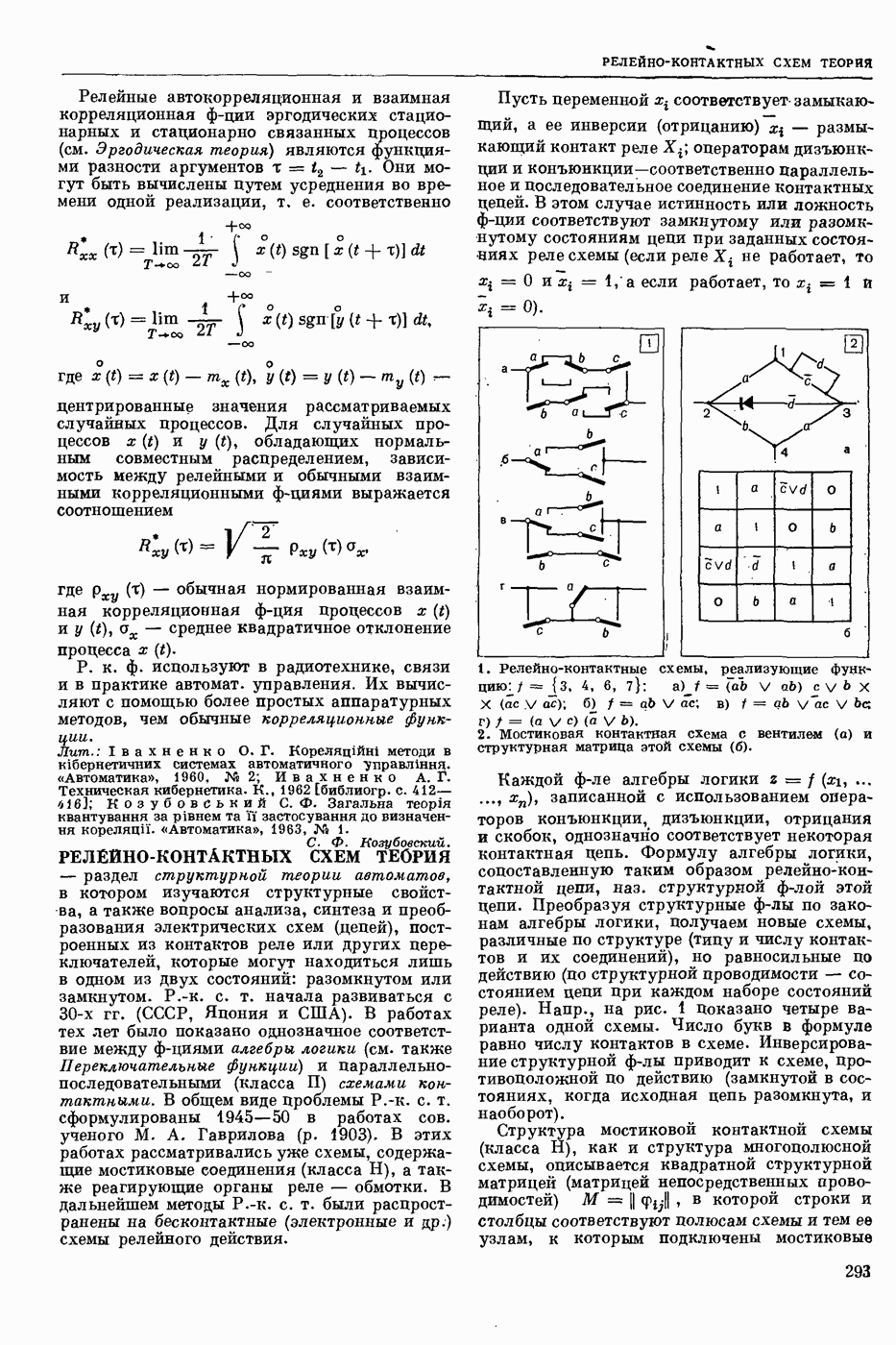
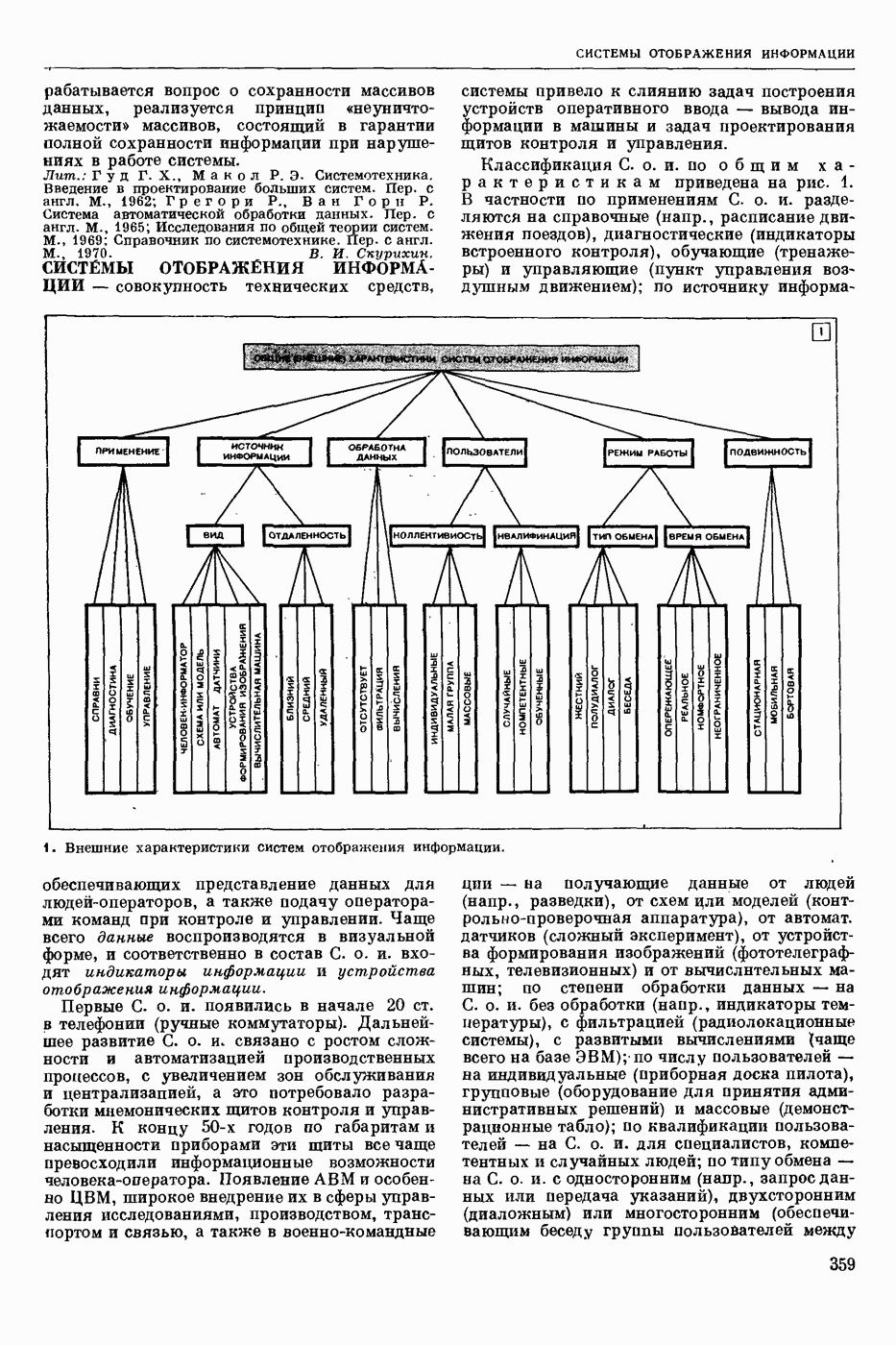
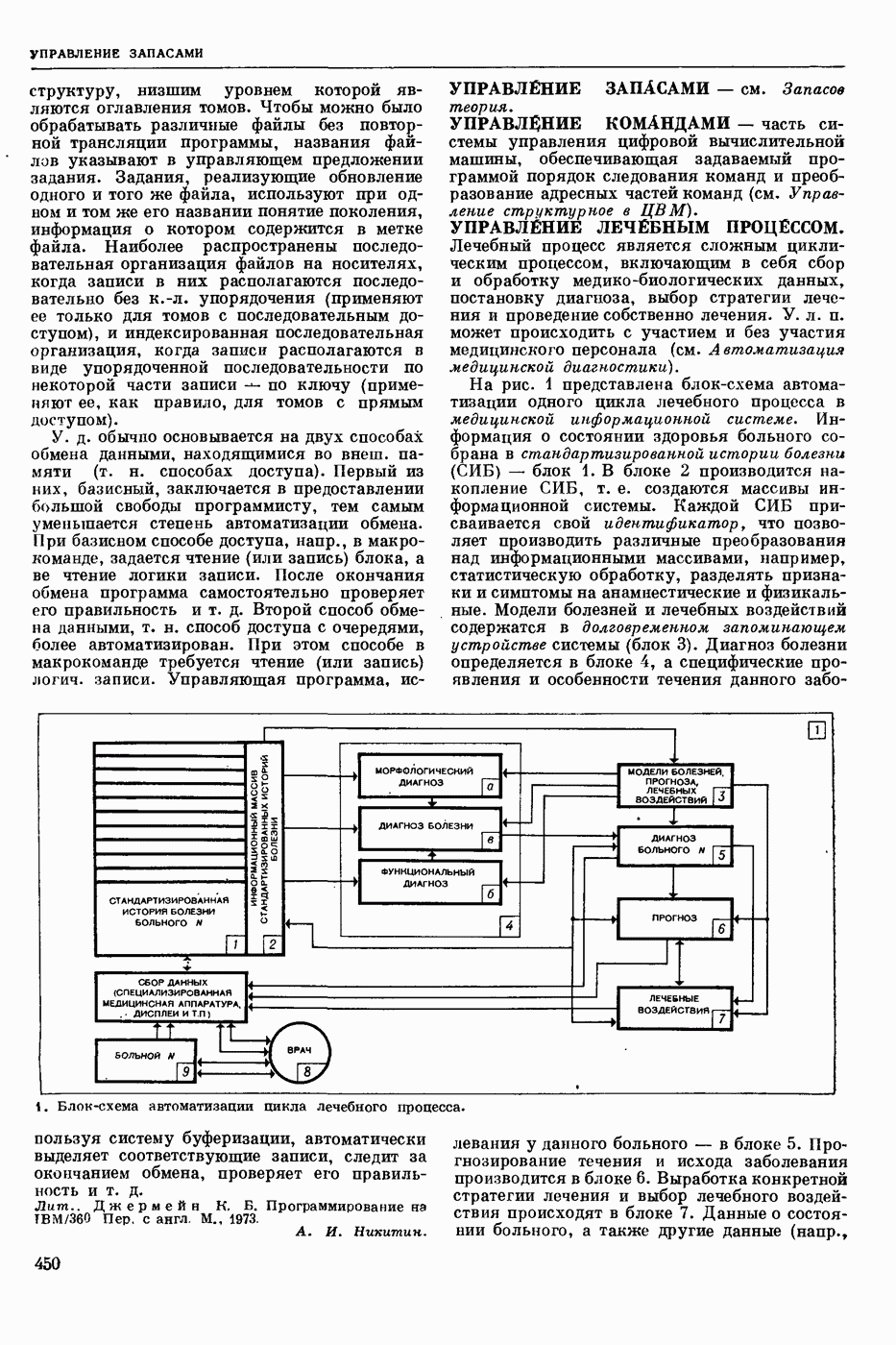
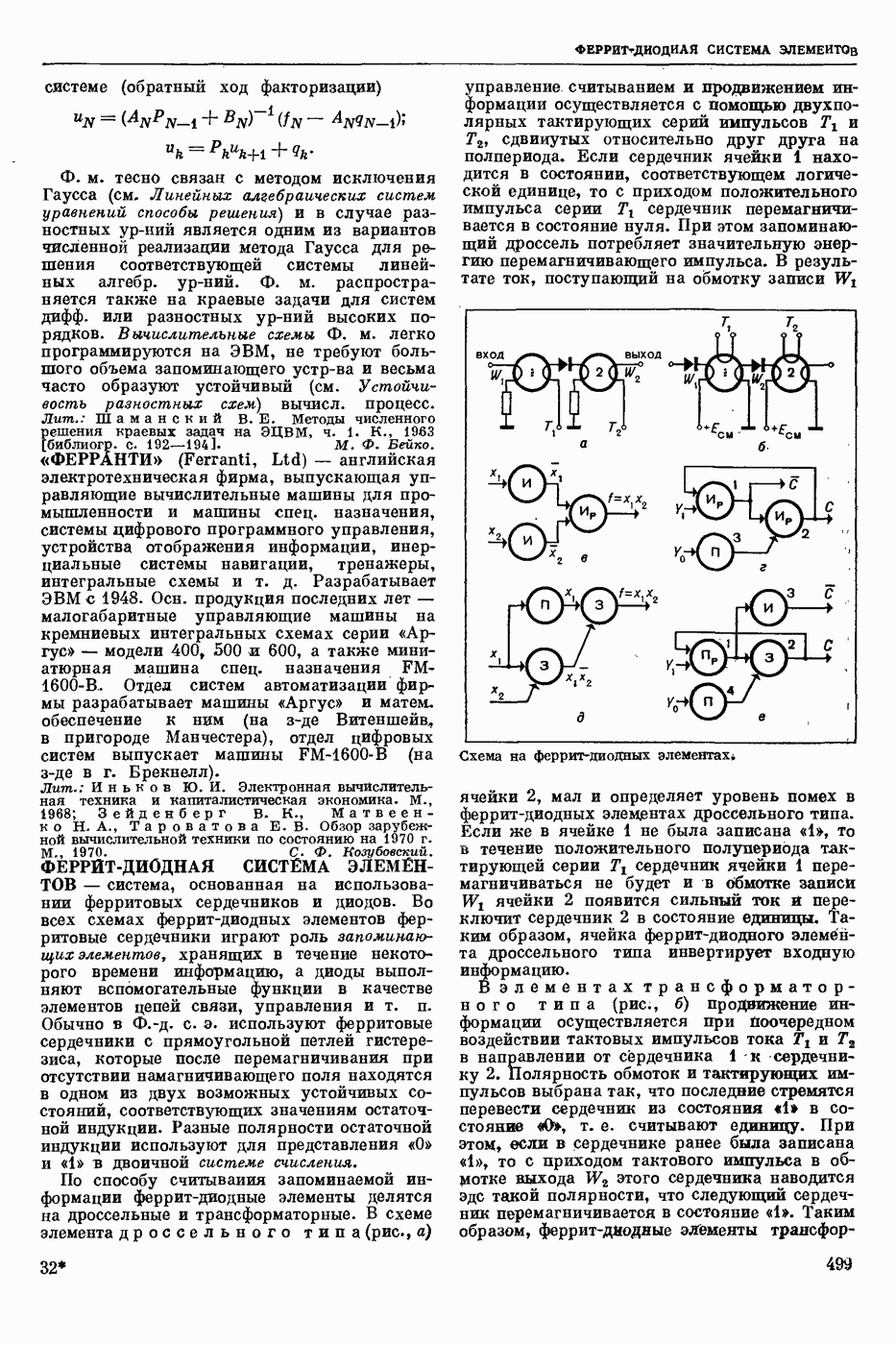
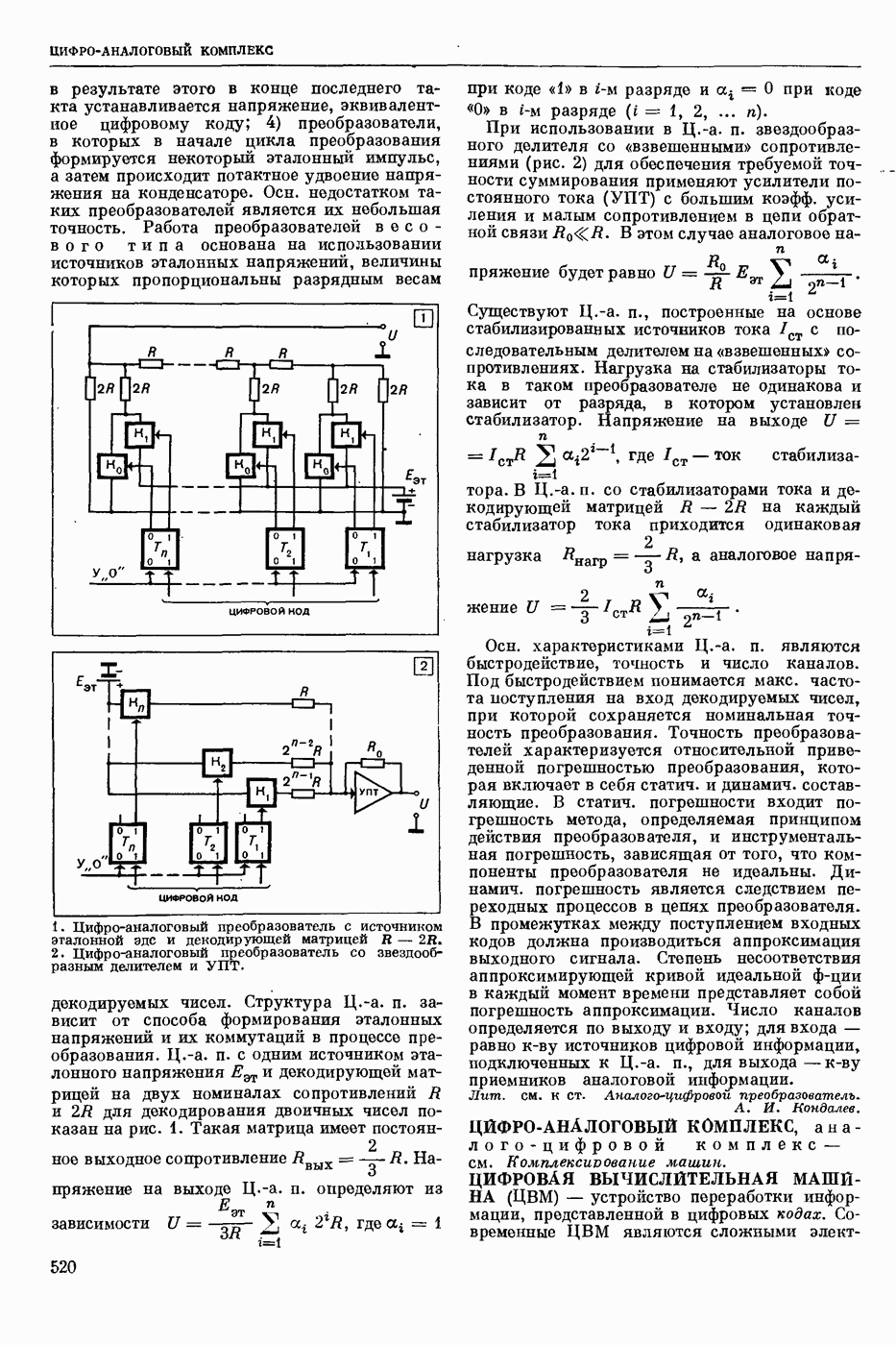
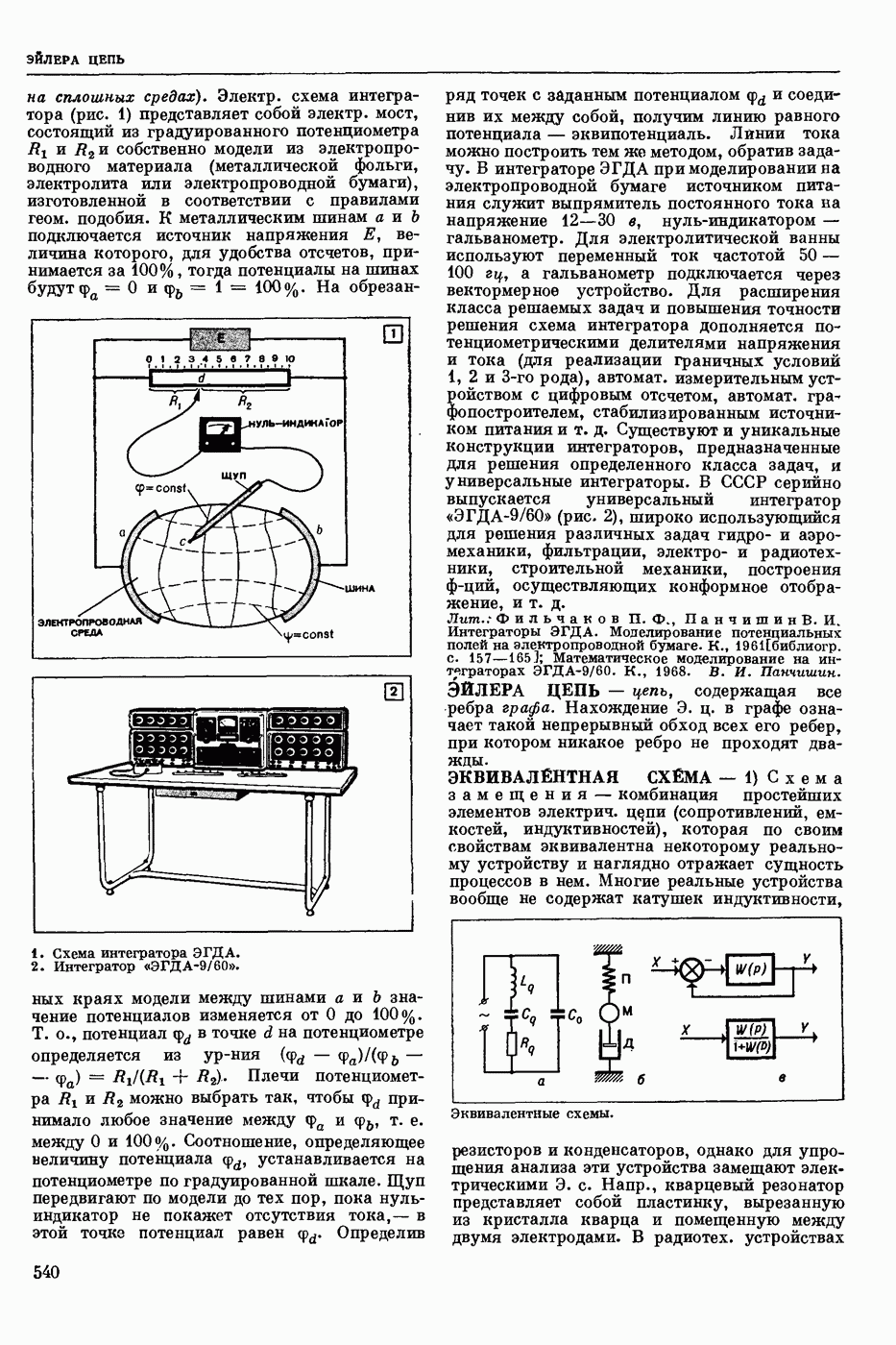
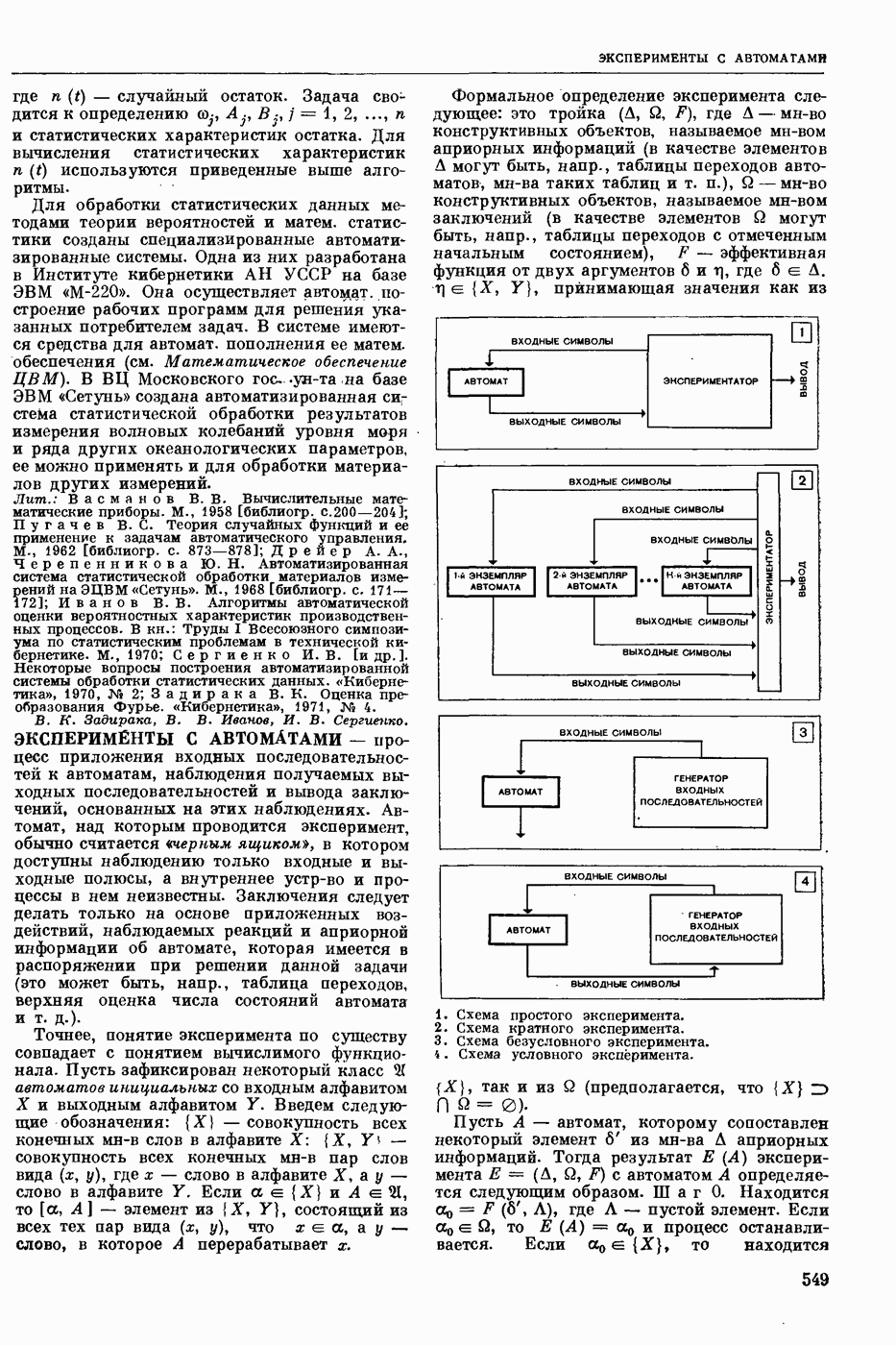
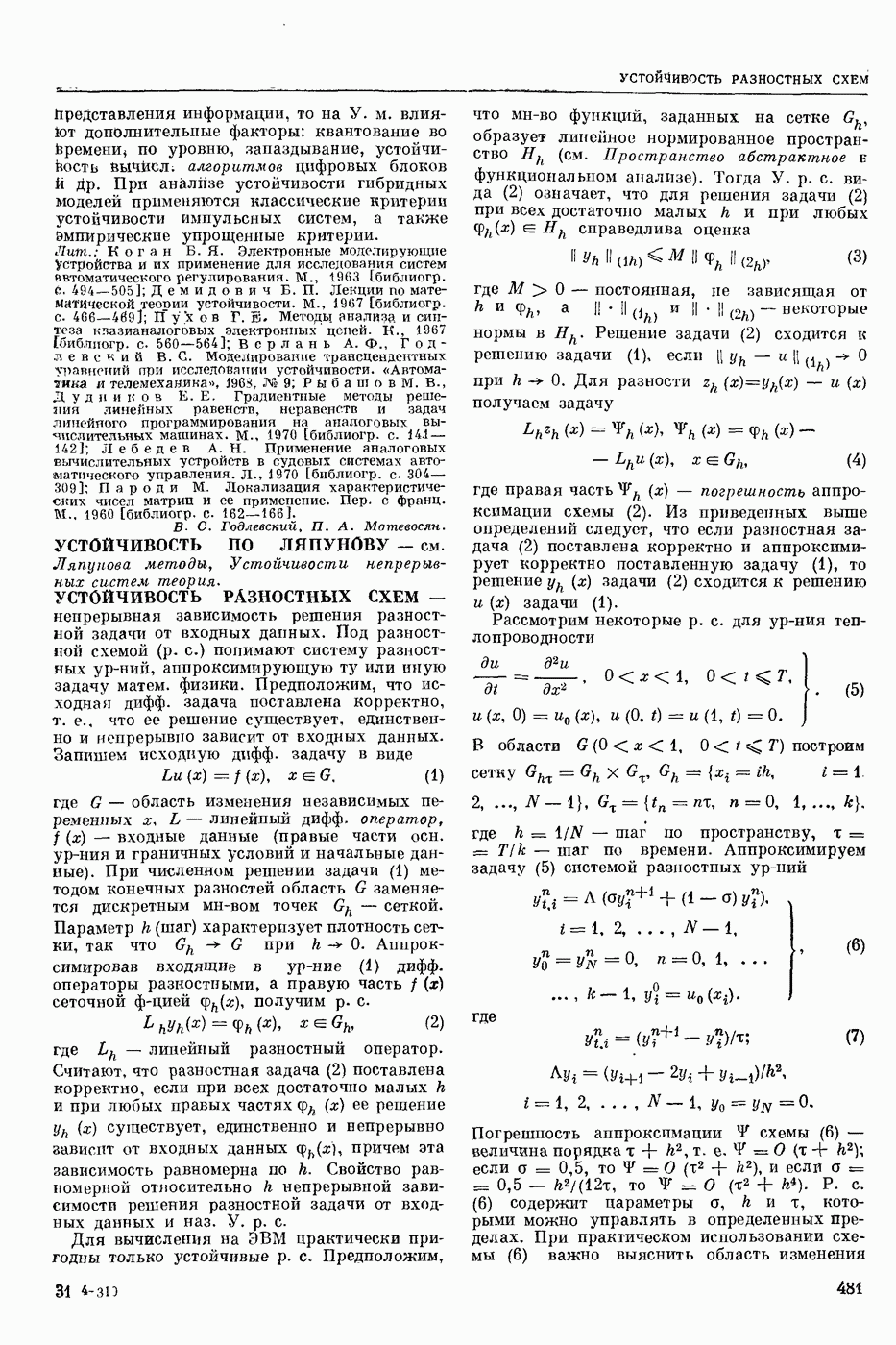ПРОГРАММИРОВАНИЕ ДИНАМИЧЕСКОЕ
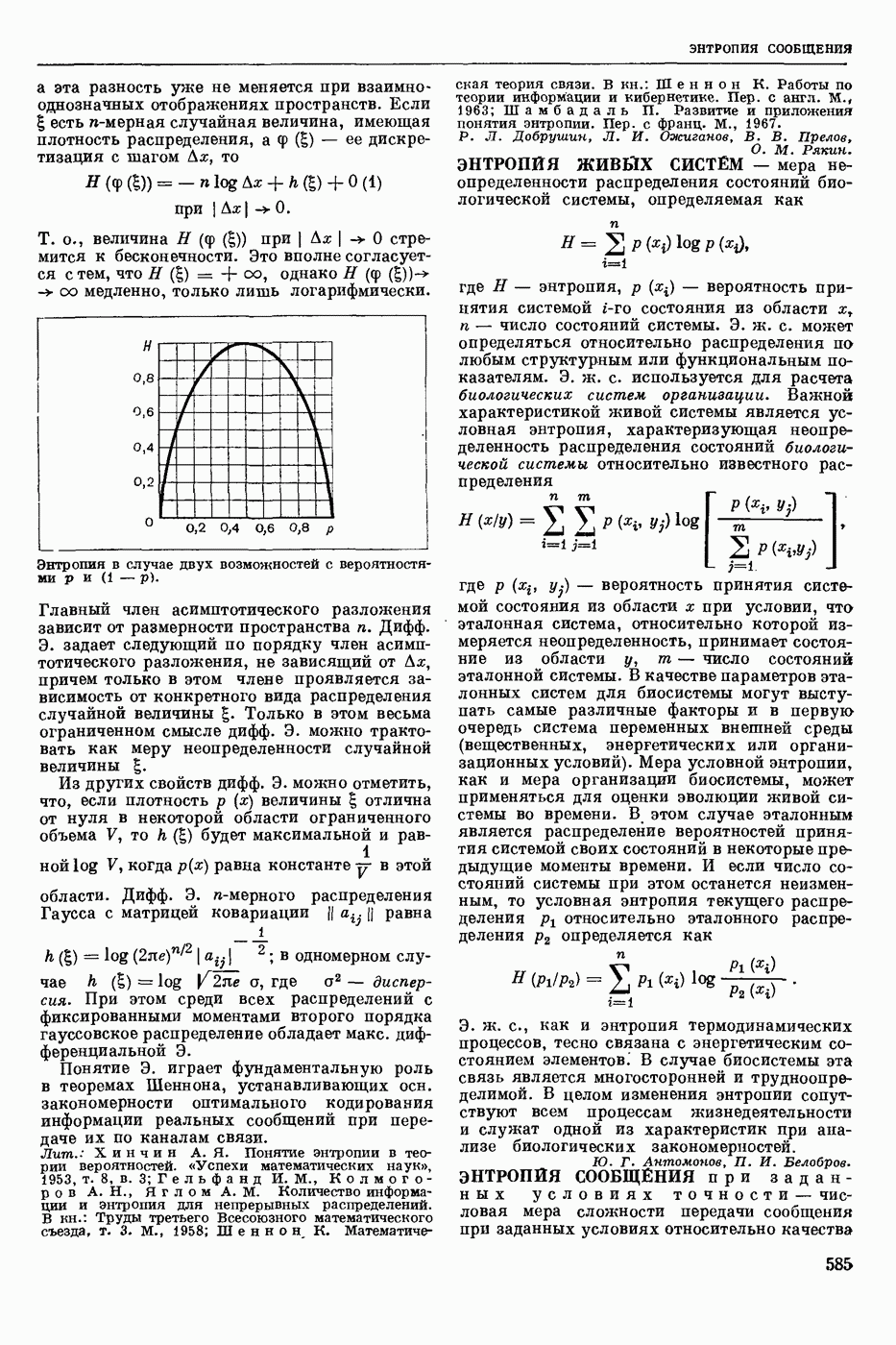
- раздел программирования математического, изучающий многошаговые процессы поиска решения. В различных областях теор. и практической деятельности целесообразно искать решение не сразу, а последовательно, шаг за шагом, т. е. поиск решения рассматривается не как единичный акт, а как процесс, состоящий из нескольких этапов. Различные задачи многошаговых процессов поиска решения могут быть описаны некоторым единообразным матем. аппаратом. Таким аппаратом является теория П. д., созданная в течение 50-х годов 20 ст. амер. математиком Р. Веллманом и его учениками. В задачах, решаемых методами П. д., имеется физ. система, характеризуемая на любом шаге параметрами состояния; на каждом шаге принимается одно из допустимого мн-ва решений, результатом чего является преобразование параметров состояния; предыстория системы не имеет никакого значения при определении будущих действий. Любое правило для поиска решения, которое дает допустимую последовательность решений, наз. поведением (политикой). Целью «процесса является опт-ция некоторой ф-ции параметров состояния и политики — ф-ции критерия (дохода). Поведение, оптимизирующее ф-цию критерия, наз. оптимальным поведением.
В основе теории П. д. лежит Веллмана принцип оптимальности. Матем. формулировка этого принципа приводит к ур-ниям, решение которых определяет оптим. поведение и оптим. доход. Пусть имеется детерминированный дискретный процесс поиска решения, характеризуемый вектором состояния  , которое определено для конечного числа шагов N и принадлежит мн-ву D. Далее,
, которое определено для конечного числа шагов N и принадлежит мн-ву D. Далее,  где q — элемент некоторого мн-ва
где q — элемент некоторого мн-ва  , представляет собой мн-во преобразований, обладающее тем свойством, что, если
, представляет собой мн-во преобразований, обладающее тем свойством, что, если  то
то  ей для всех
ей для всех  . Для конечного процесса каждое поведение состоит в выборе N преобразований
. Для конечного процесса каждое поведение состоит в выборе N преобразований  дающих одно за другим последовательность состояний
дающих одно за другим последовательность состояний

Эти преобразования должны быть выбраны так, чтобы максимизировать ф-цию  Обозначим через
Обозначим через  макс. значение ф-ции критерия, если начальное состояние процесса описывается вектором
макс. значение ф-ции критерия, если начальное состояние процесса описывается вектором  и до окончания процесса осталось i шагов, т. е.
и до окончания процесса осталось i шагов, т. е.

Для получения рекуррентного соотношения, связывающего члены последовательности  воспользуемся принципом оптимальности Веллмана. Пусть на
воспользуемся принципом оптимальности Веллмана. Пусть на  шаге в качестве решения выбирают некоторое преобразование
шаге в качестве решения выбирают некоторое преобразование  так что в результате получают новый вектор состояния
так что в результате получают новый вектор состояния  . Доход, получаемый после осуществления
. Доход, получаемый после осуществления  шага процесса, равен
шага процесса, равен  Макс. доход, получаемый после осуществления оставшихся
Макс. доход, получаемый после осуществления оставшихся  шагов процесса, равен по определению
шагов процесса, равен по определению  Поэтому для максимизации полного дохода от осуществления всех i шагов процесса q следует выбрать так, чтобы максимизировать сумму
Поэтому для максимизации полного дохода от осуществления всех i шагов процесса q следует выбрать так, чтобы максимизировать сумму 
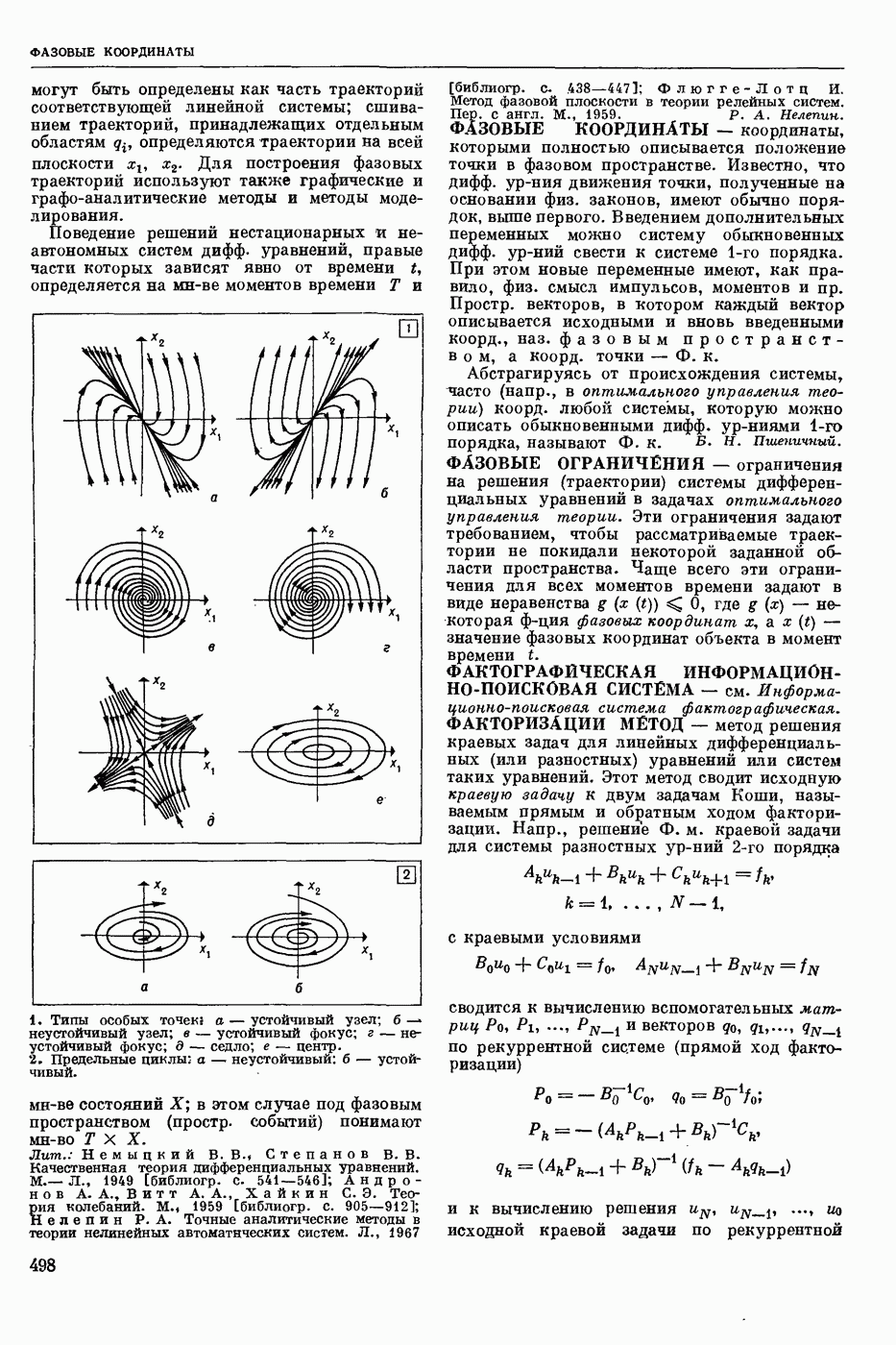
Т. о., получают рекуррентные соотношения: 

Имея конкретные значения  с помощью этих соотношений можно находить оптим. поведение и оптим. доход, а именно: из соотношения (2) находят политику
с помощью этих соотношений можно находить оптим. поведение и оптим. доход, а именно: из соотношения (2) находят политику  при которой достигается максимум правой части, и соответствующий доход
при которой достигается максимум правой части, и соответствующий доход  Далее, зная
Далее, зная  из соотношения
из соотношения

находят  и т. д. Наконец, зная
и т. д. Наконец, зная  из соотношения
из соотношения

находят  и оптим. доход
и оптим. доход  Тогда оптим. поведение на первом шаге -
Тогда оптим. поведение на первом шаге -  -шагового процесса будет
-шагового процесса будет  а оптим. состояние
а оптим. состояние  На втором шаге оптим. поведение и состояние будет соответственно
На втором шаге оптим. поведение и состояние будет соответственно  и т. д. На
и т. д. На 
шаге они будут соответственно  . В случае неограниченно продолжающегося процесса
. В случае неограниченно продолжающегося процесса  являющегося однородным
являющегося однородным  соотношения (1) — (2) заменяются функциональным уравнением
соотношения (1) — (2) заменяются функциональным уравнением

Для решения ур-ний такого рода применяют метод последовательных приближений в простр. доходов, состоящий в выборе начальной ф-ции  и последующем определении последовательности ф-ций
и последующем определении последовательности ф-ций

Другой метод — метод приближения в пространстве поведений, состоящий в том, что в качестве начального приближения выбирают некоторое  и из функционального ур-ния
и из функционального ур-ния  определяют доход, соответствующий этому поведению. Далее, как в обычном методе последовательных приближений, полагают
определяют доход, соответствующий этому поведению. Далее, как в обычном методе последовательных приближений, полагают

При этом последовательность  является неубывающей.
является неубывающей.
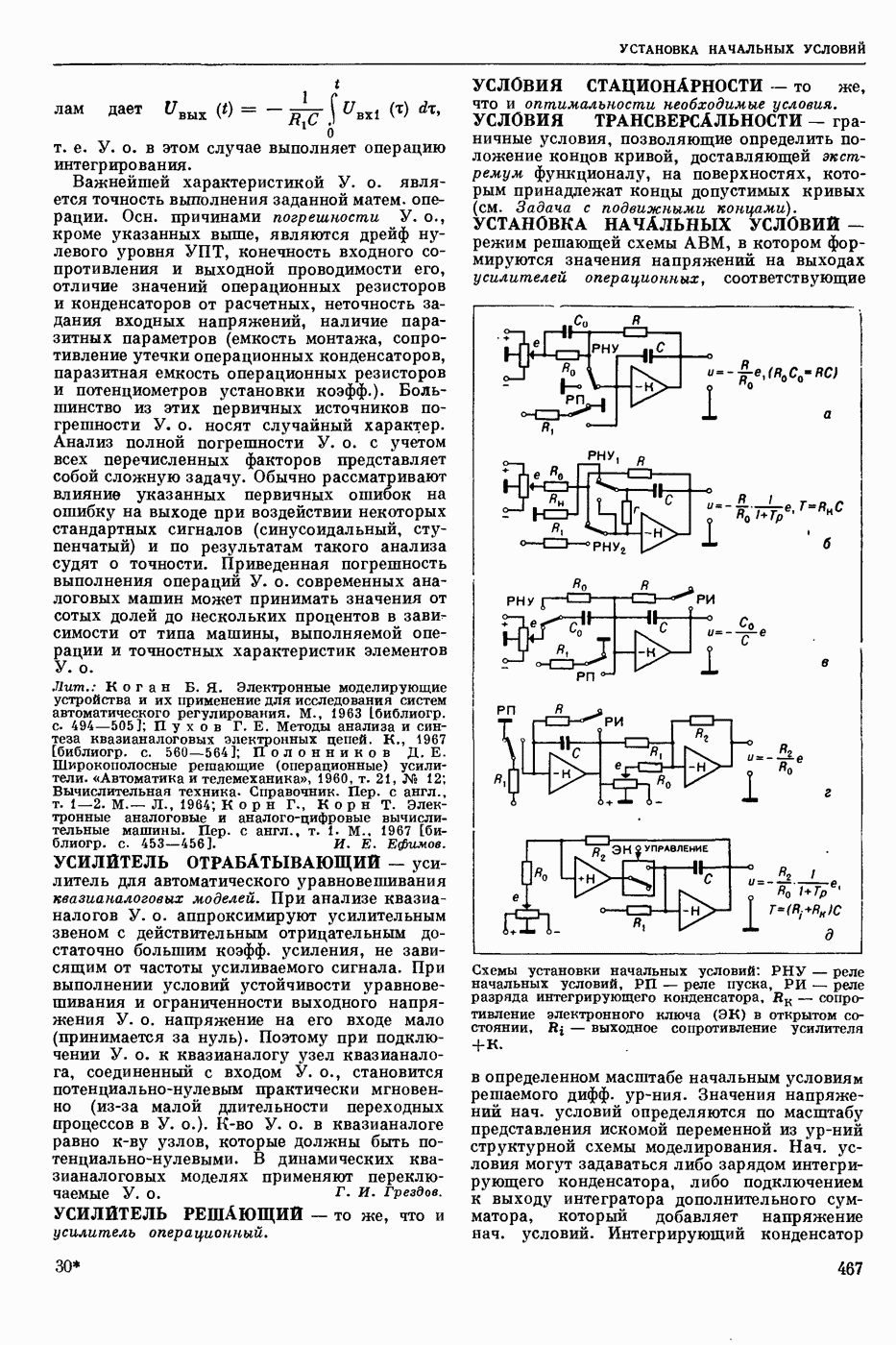
Метод П. д. применяют для решения задач оптим. управления. Пусть ур-ние движения управляемого объекта имеет вид

 вектор состояния, а
вектор состояния, а  вектор управления (поведение) в момент
вектор управления (поведение) в момент  . Здесь
. Здесь  замкнутая область
замкнутая область  -мерного евклидового простр. (см. Пространство абстрактное в функциональном анализе). Требуется минимизировать интеграл
-мерного евклидового простр. (см. Пространство абстрактное в функциональном анализе). Требуется минимизировать интеграл

Обозначим через  миним. значение интеграла (6) при условии, что объект стартует из точки
миним. значение интеграла (6) при условии, что объект стартует из точки  фазового простр., т. е.
фазового простр., т. е.

Тогда при условии существования частных производных  получается Веллмана уравнение для ф-ции
получается Веллмана уравнение для ф-ции 

Минимума правая часть ур-ния (8) достигает на некоторой ф-ции  так что, решив это ур-ние, получим оптим. управление как ф-цию фазовых координат
так что, решив это ур-ние, получим оптим. управление как ф-цию фазовых координат  . Однако решить ур-ние (8) для общего случая трудно. Кроме того, трудно обосновать справедливость этого ур-ния, поскольку ф-ция
. Однако решить ур-ние (8) для общего случая трудно. Кроме того, трудно обосновать справедливость этого ур-ния, поскольку ф-ция  , как правило, не является всюду дифференцируемой для большинства практических задач. Поэтому при реализации этого метода на ЭЦВМ дискретизируют исходную задачу (5—6) и решают получаемые при этом рекуррентные соотношения. Метод П. д. применяют также для решения задач стохастических управляемых процессов, многошаговых игр и др.
, как правило, не является всюду дифференцируемой для большинства практических задач. Поэтому при реализации этого метода на ЭЦВМ дискретизируют исходную задачу (5—6) и решают получаемые при этом рекуррентные соотношения. Метод П. д. применяют также для решения задач стохастических управляемых процессов, многошаговых игр и др.
В начале 60-х годов 20 ст. в Ин-те кибернетики АН УССР был разработан весьма эффективный численный метод решения задач П. д. — метод последовательного анализа вариантов, состоящий в последовательном поэтапном конструировании конкурентоспособных вариантов.
Лит.: Михалевич В. С. Последовательные алгоритмы оптимизации и их применение. «Кибернетика», 1965, № 1—2; Беллман Р. Динамическое программирование. Пер. с англ. М., 1960; Беллман Р., Дрейфус С. Прикладные задачи динамического программирования. Пер. с англ. М., 1965. В. П. Гуленко, В. С. Михалевич.