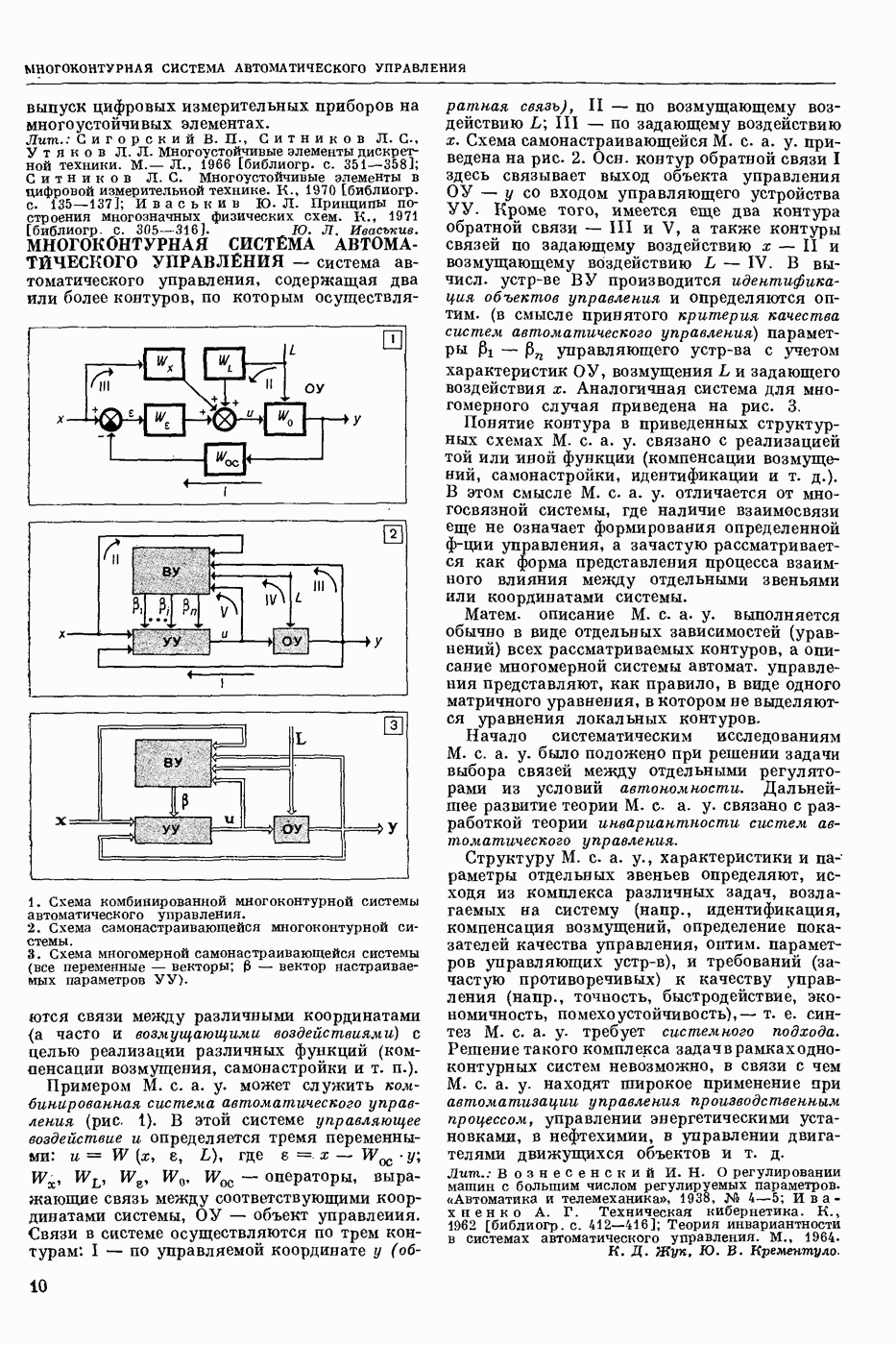
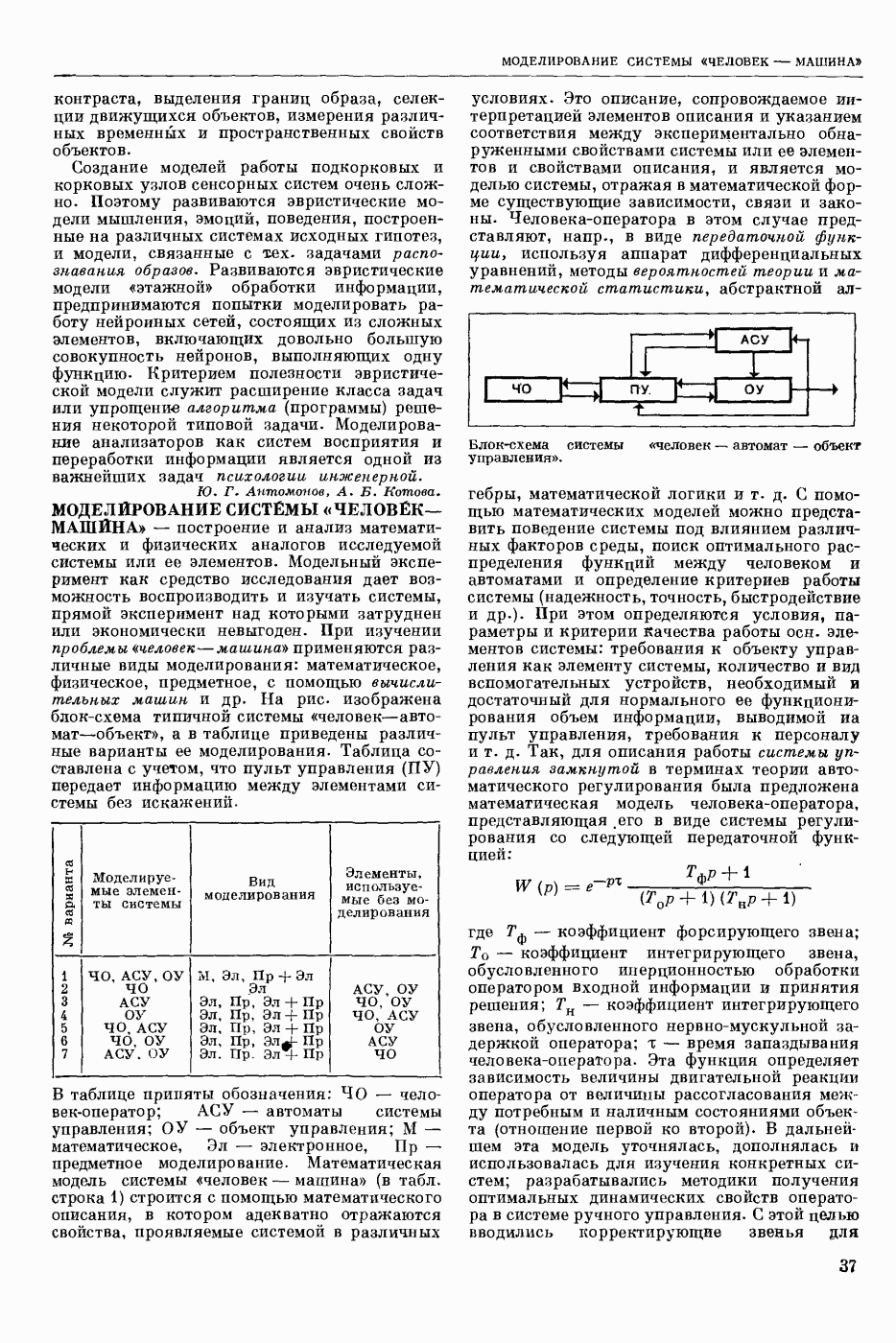
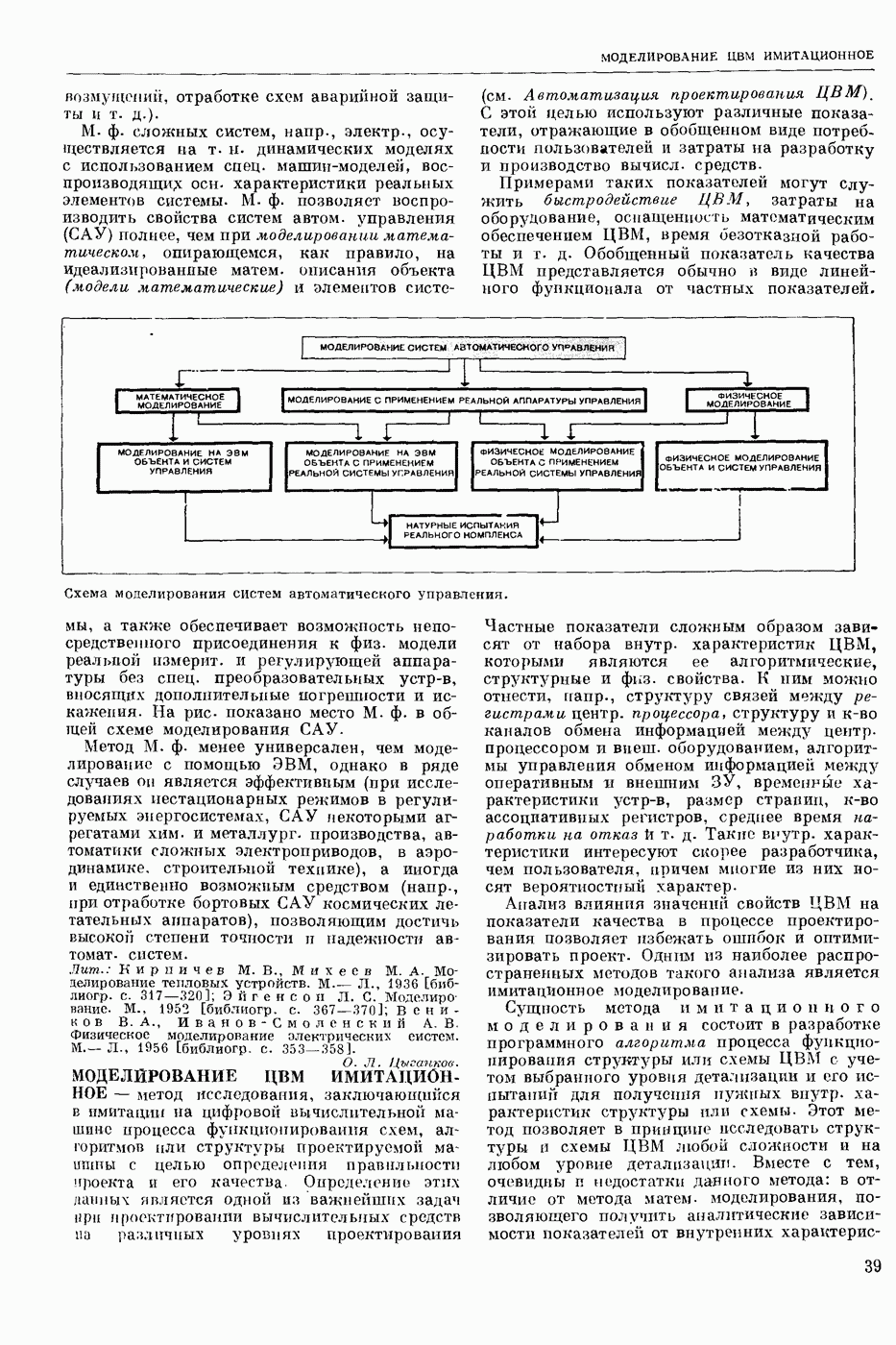
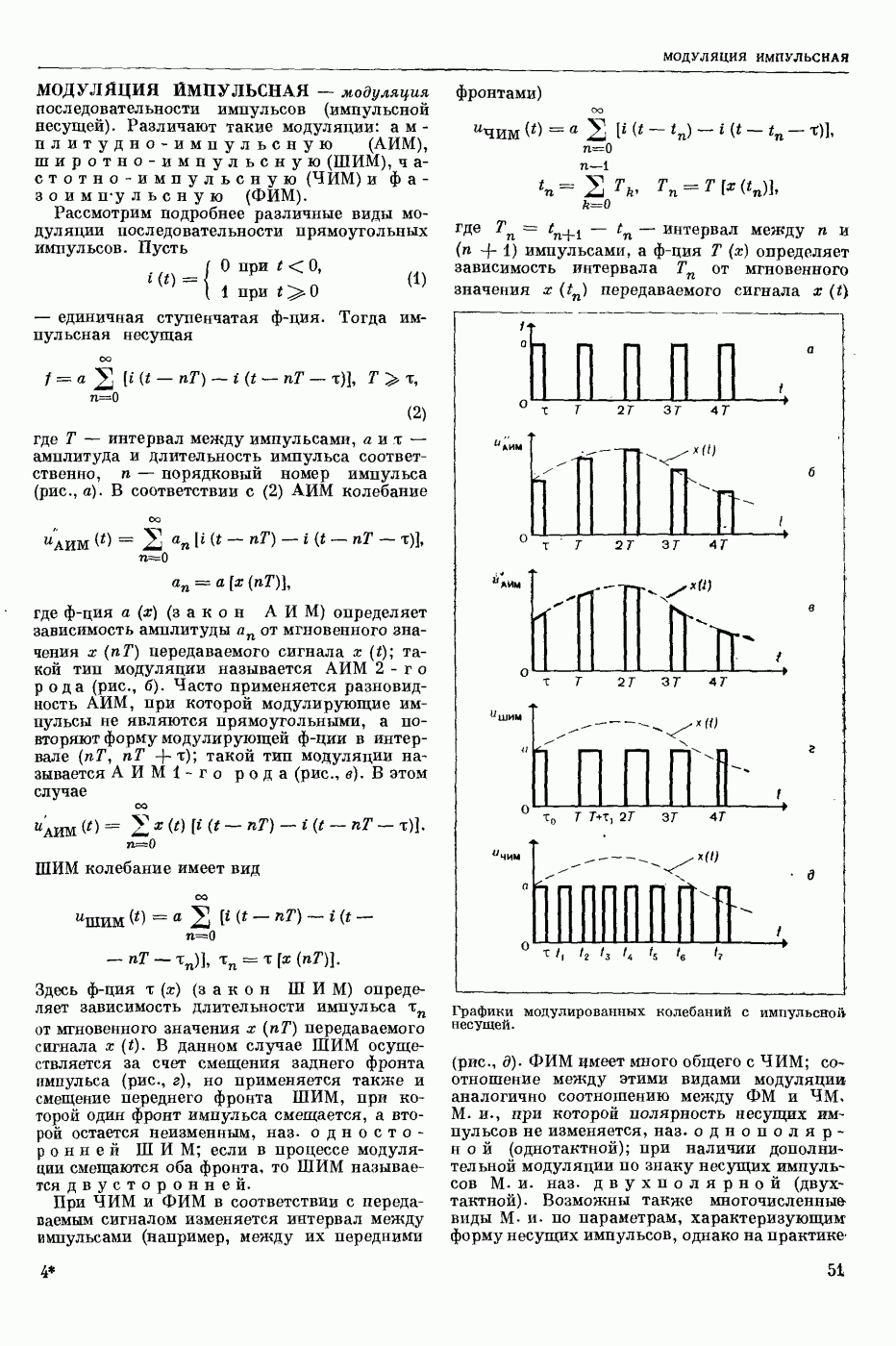
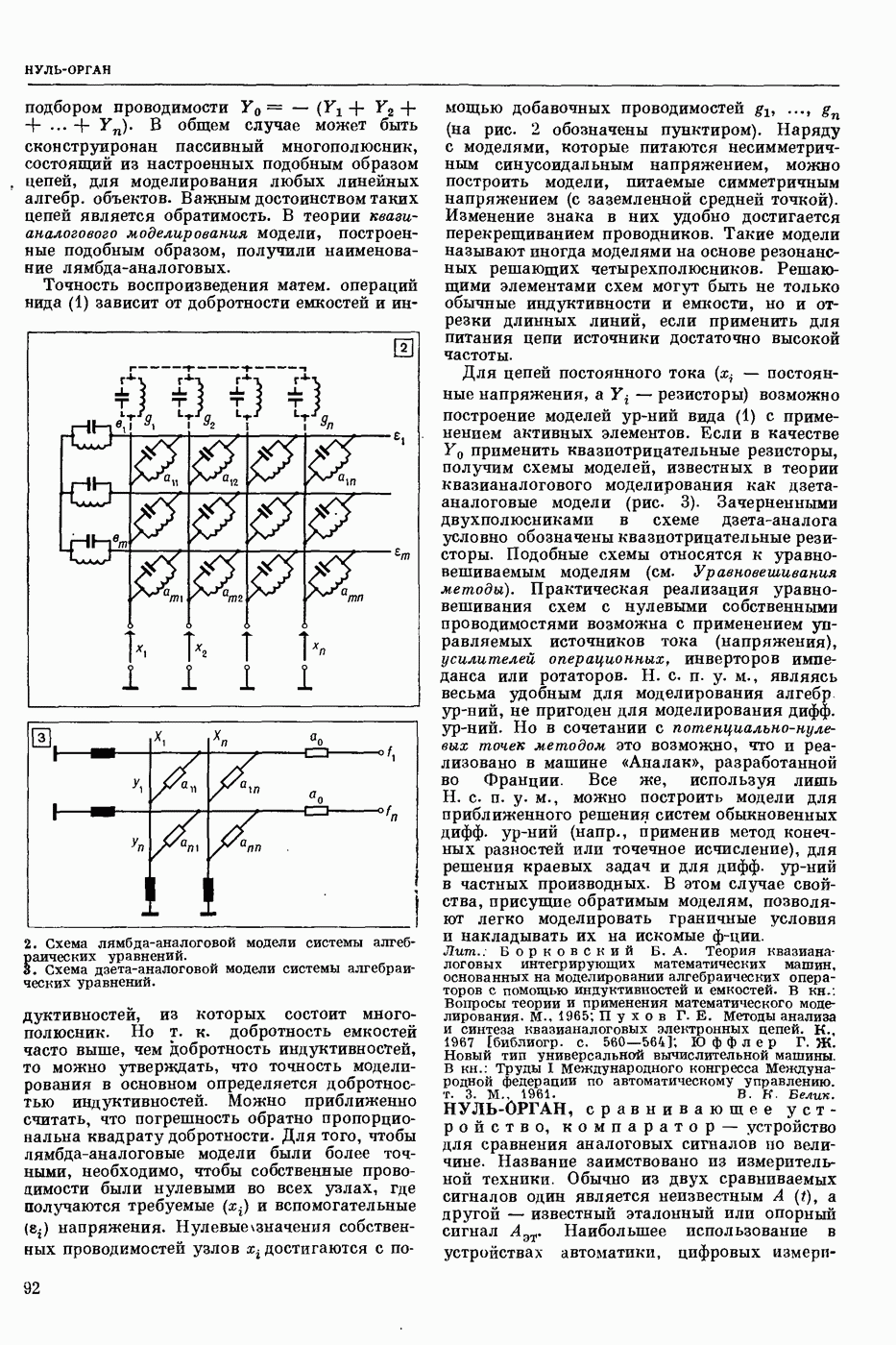
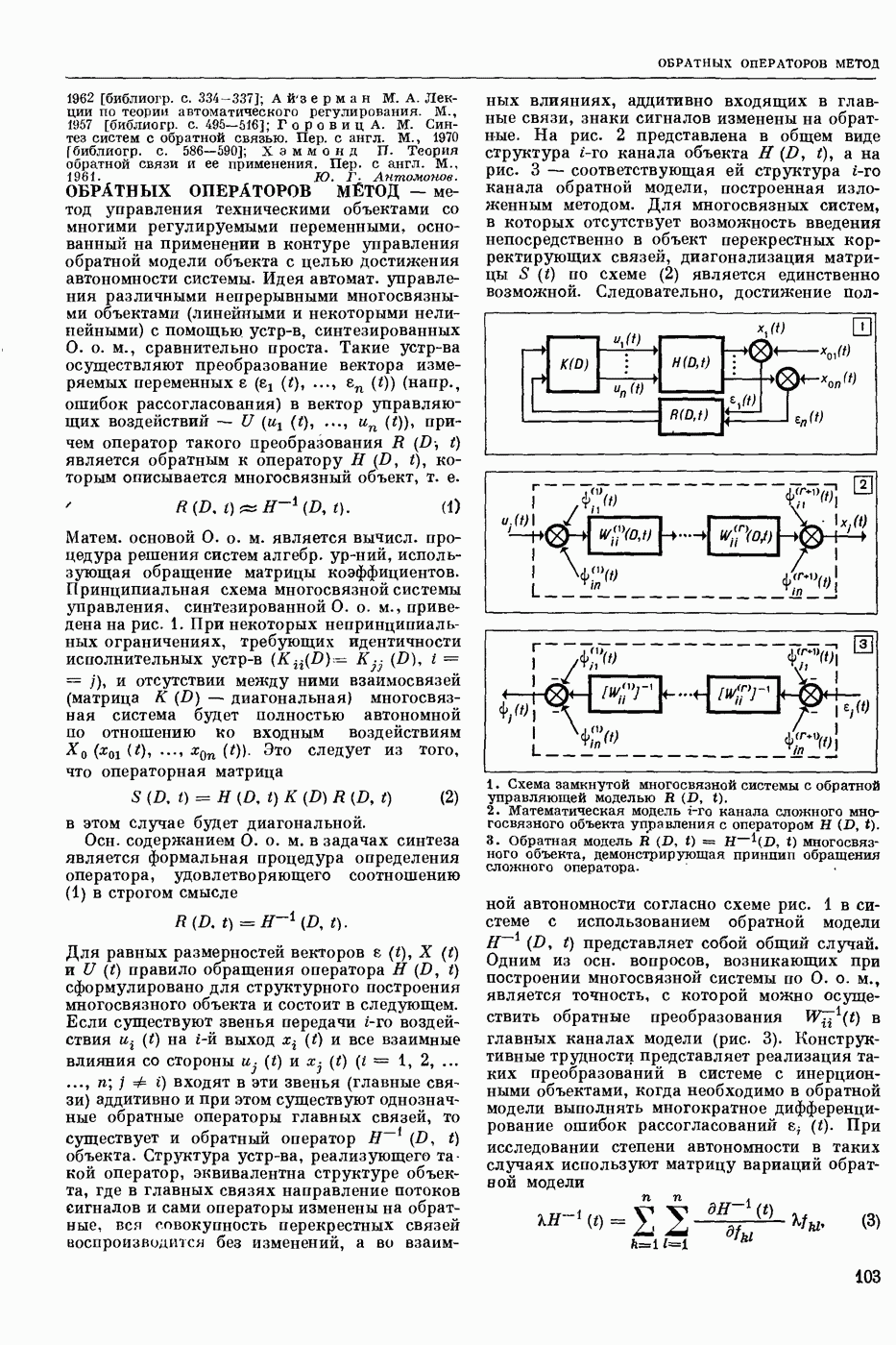
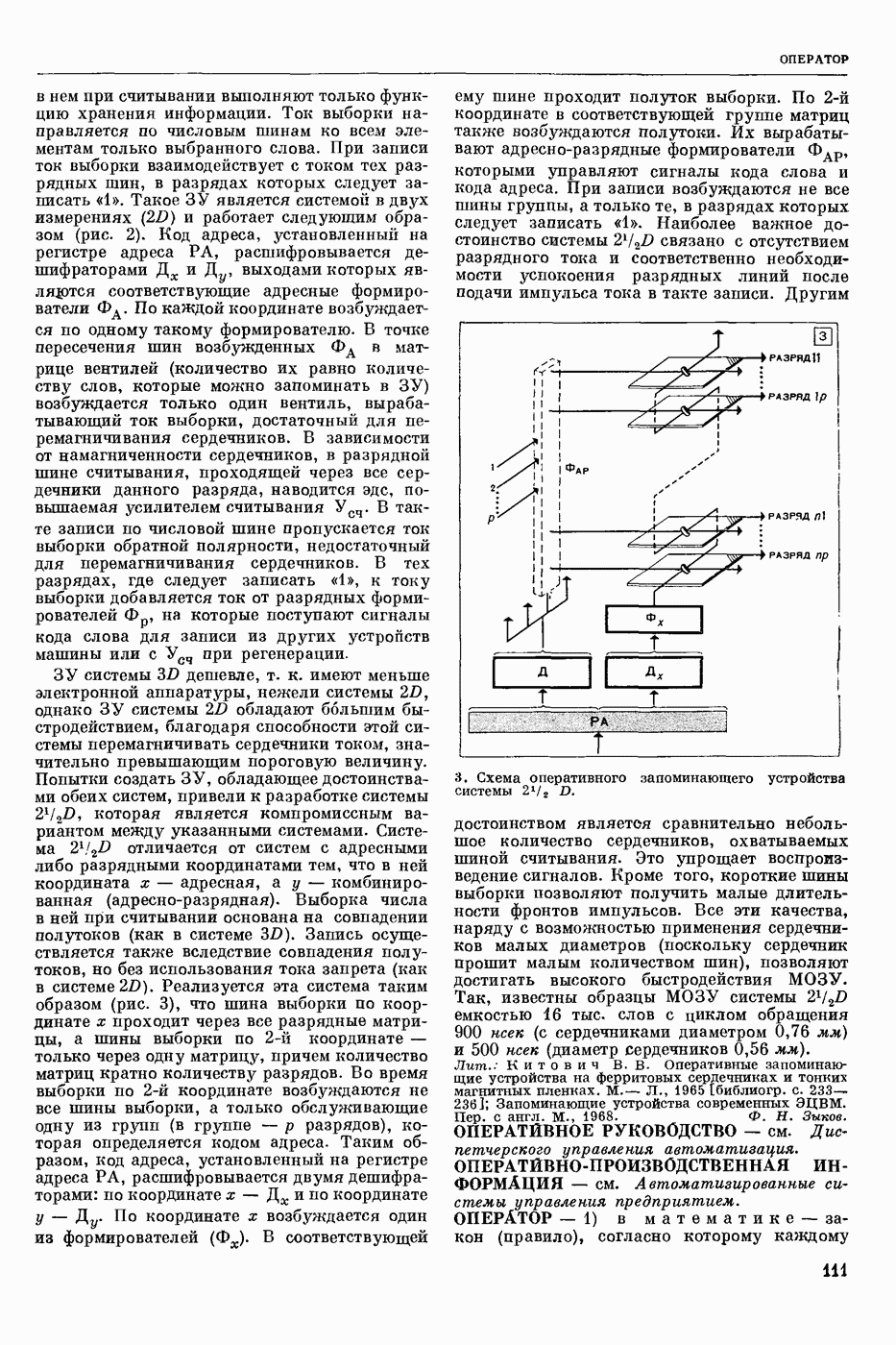
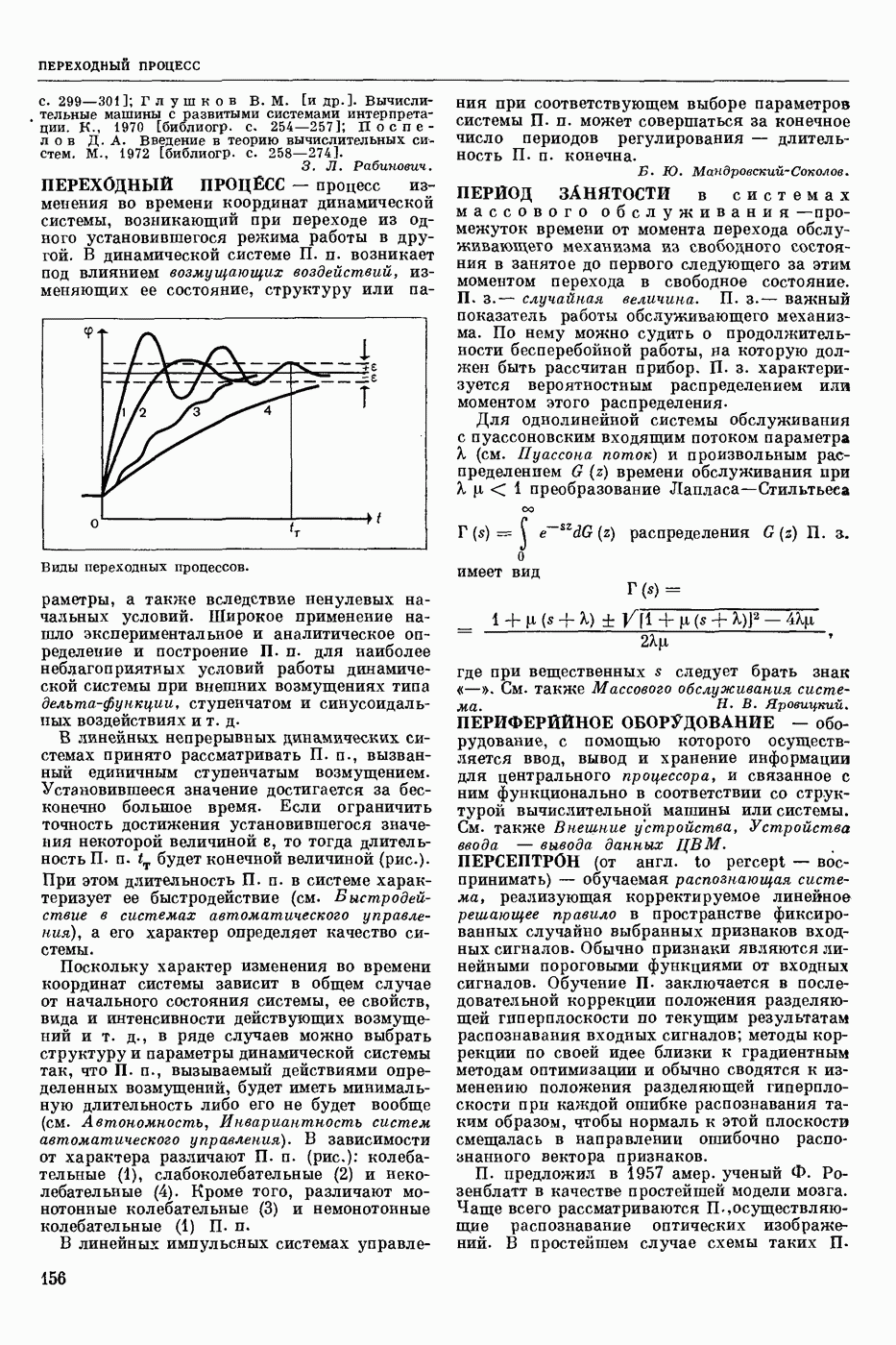
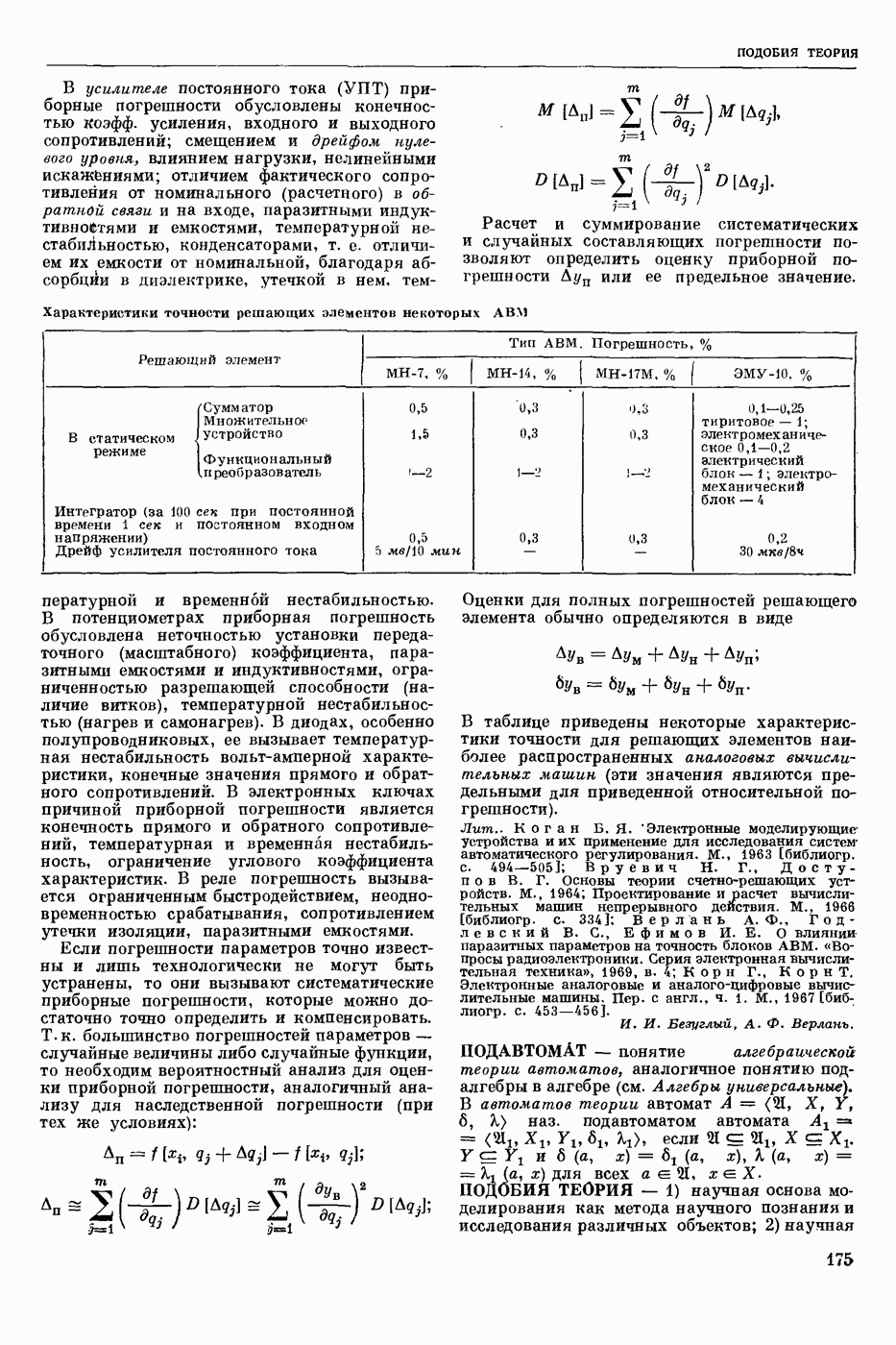
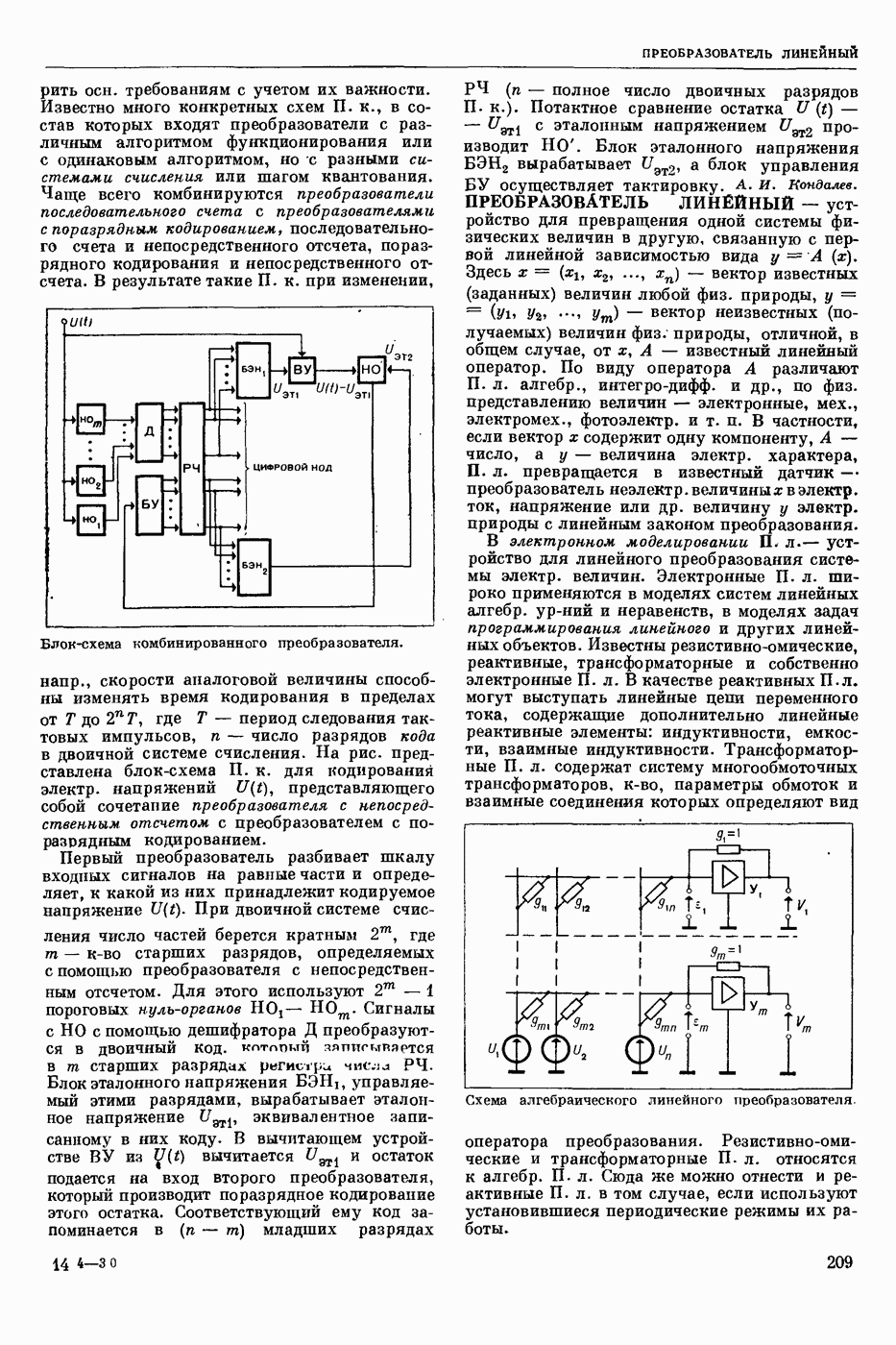
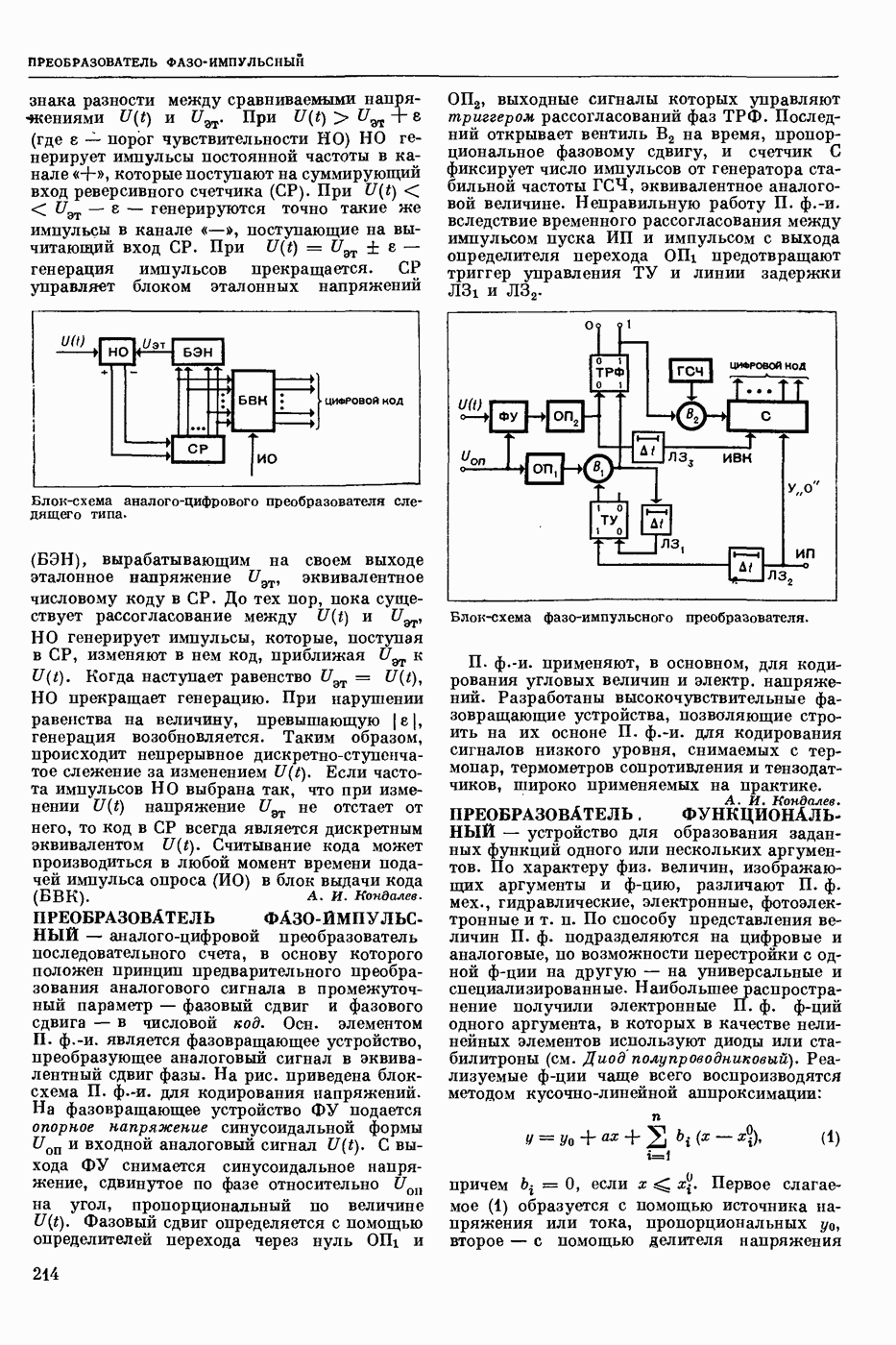
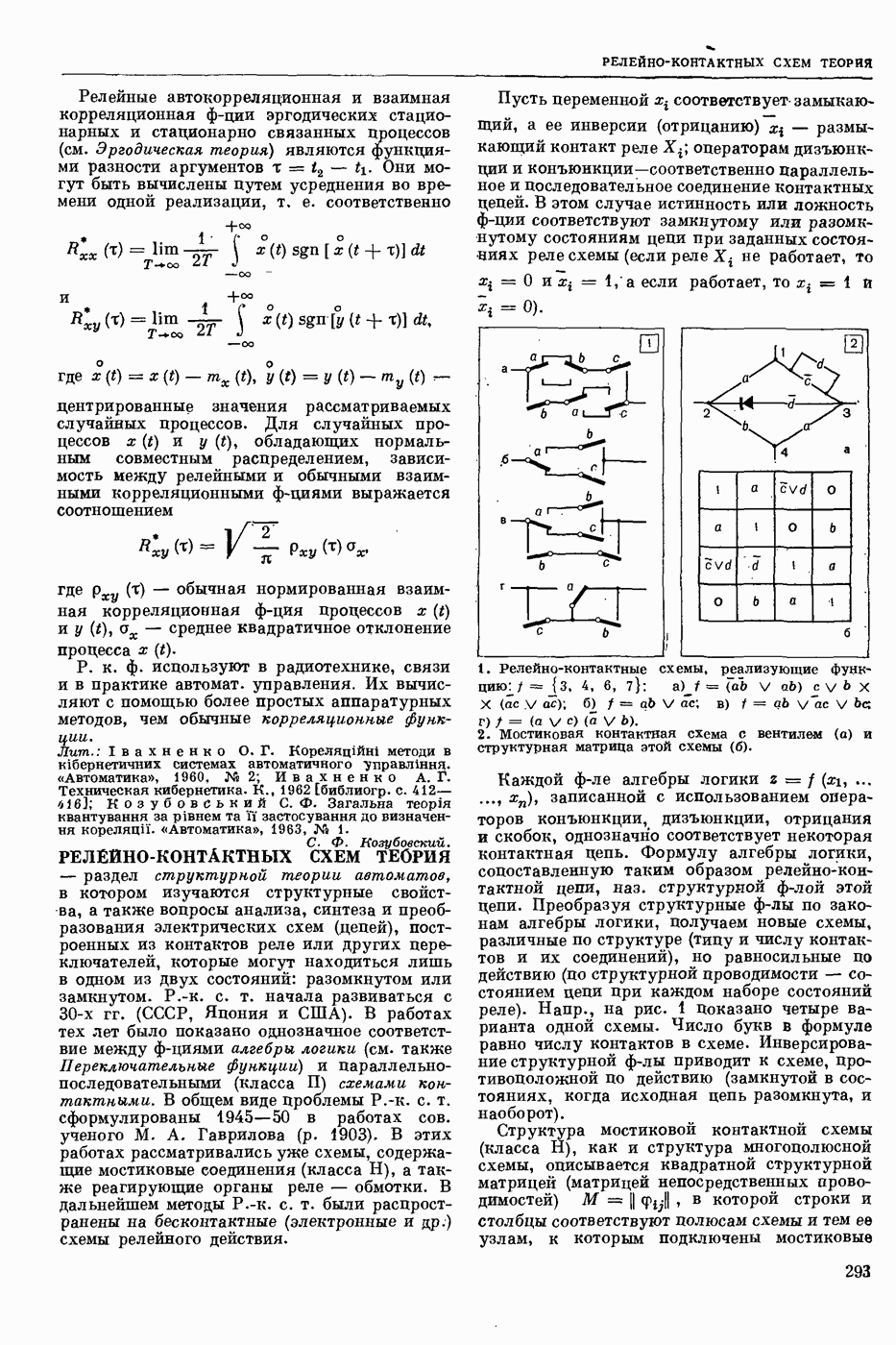
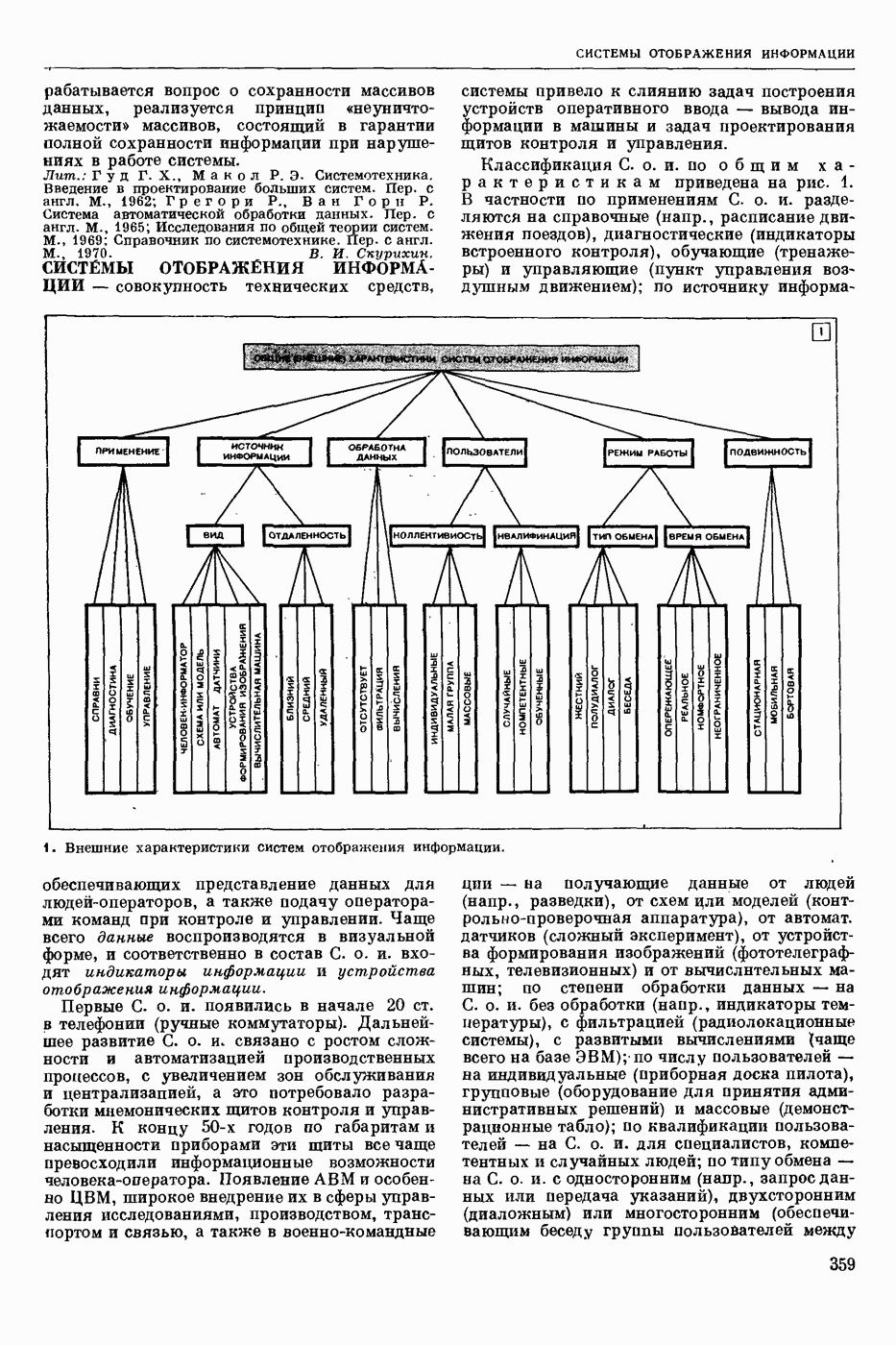
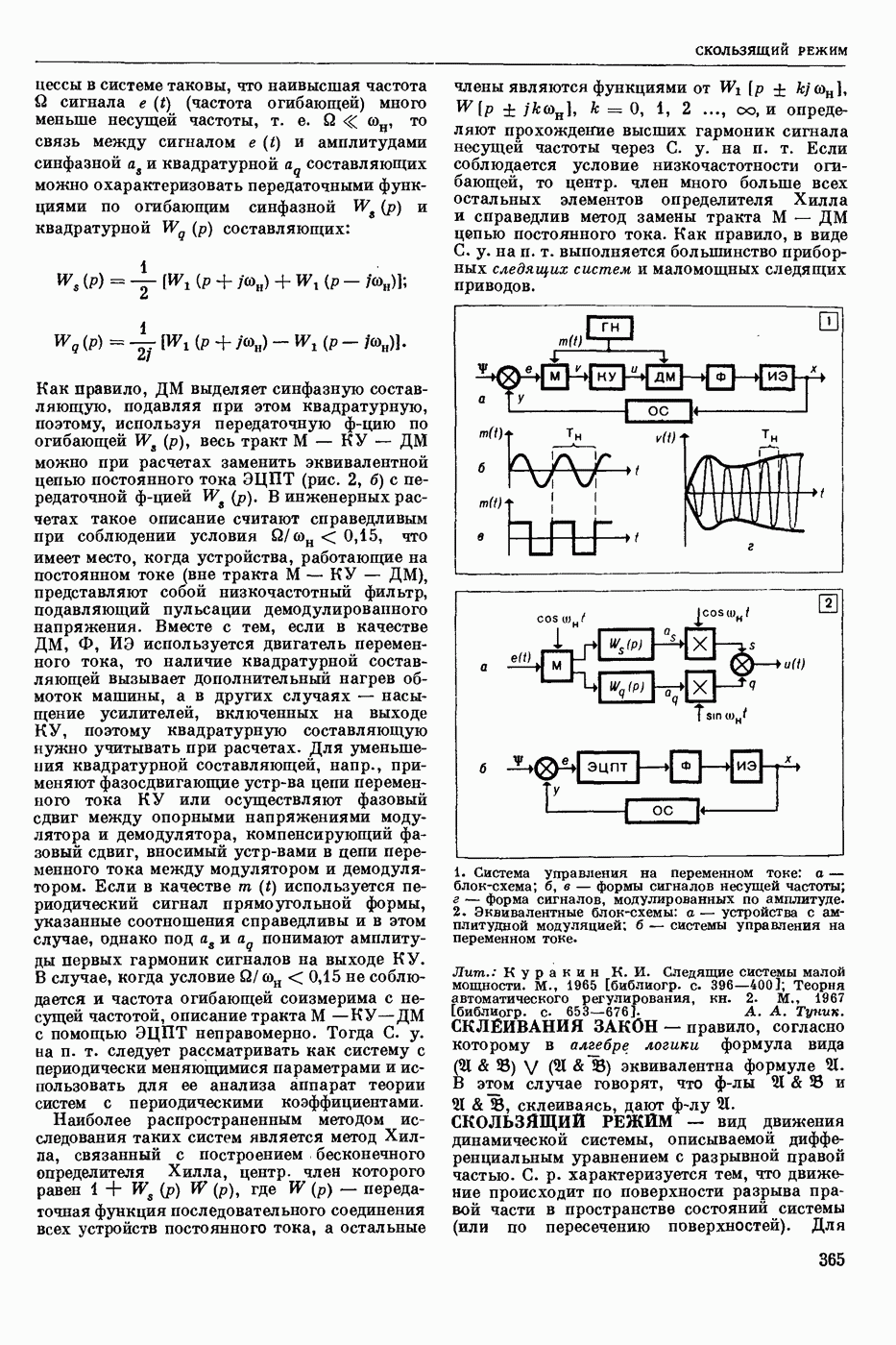
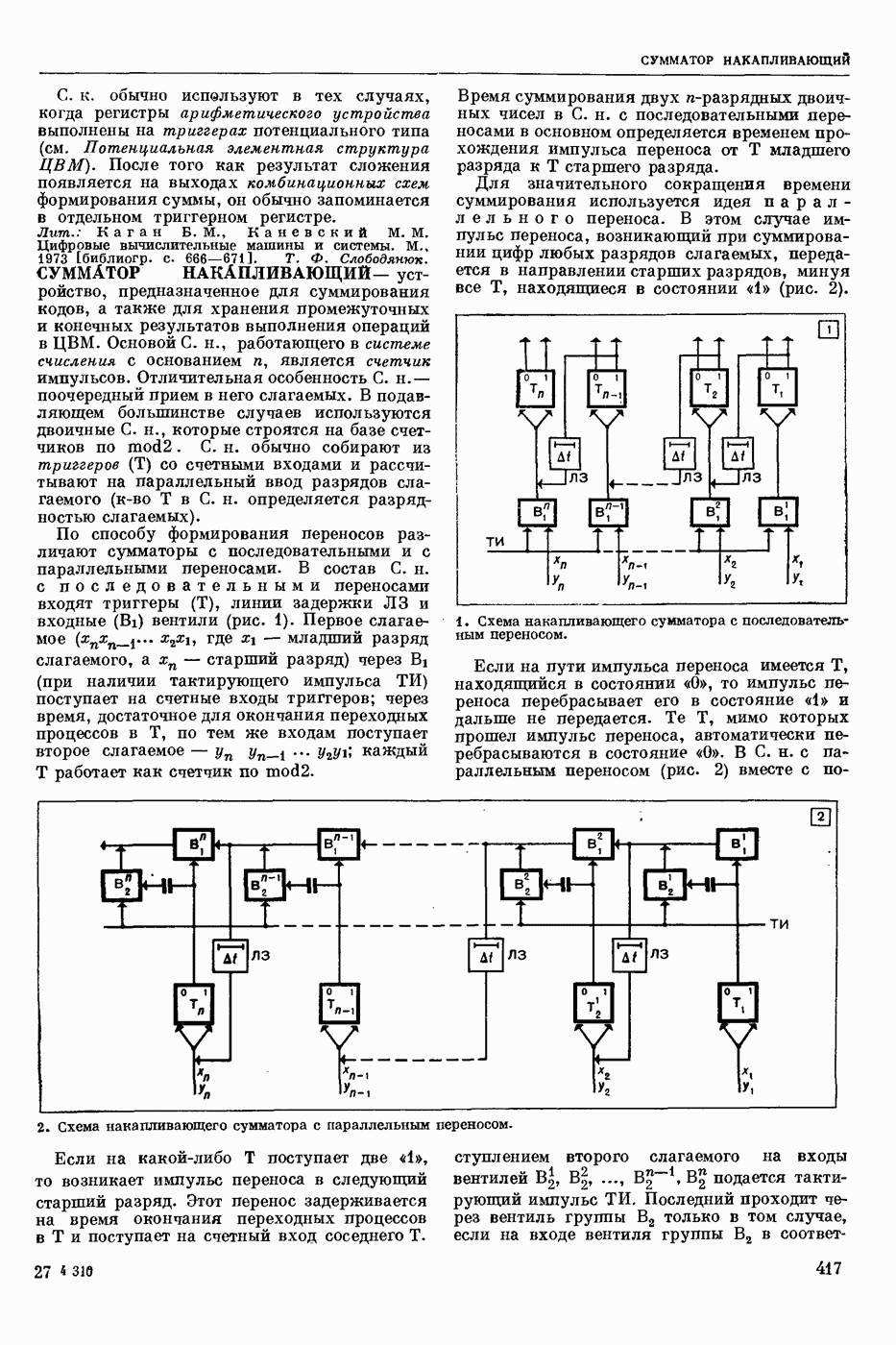
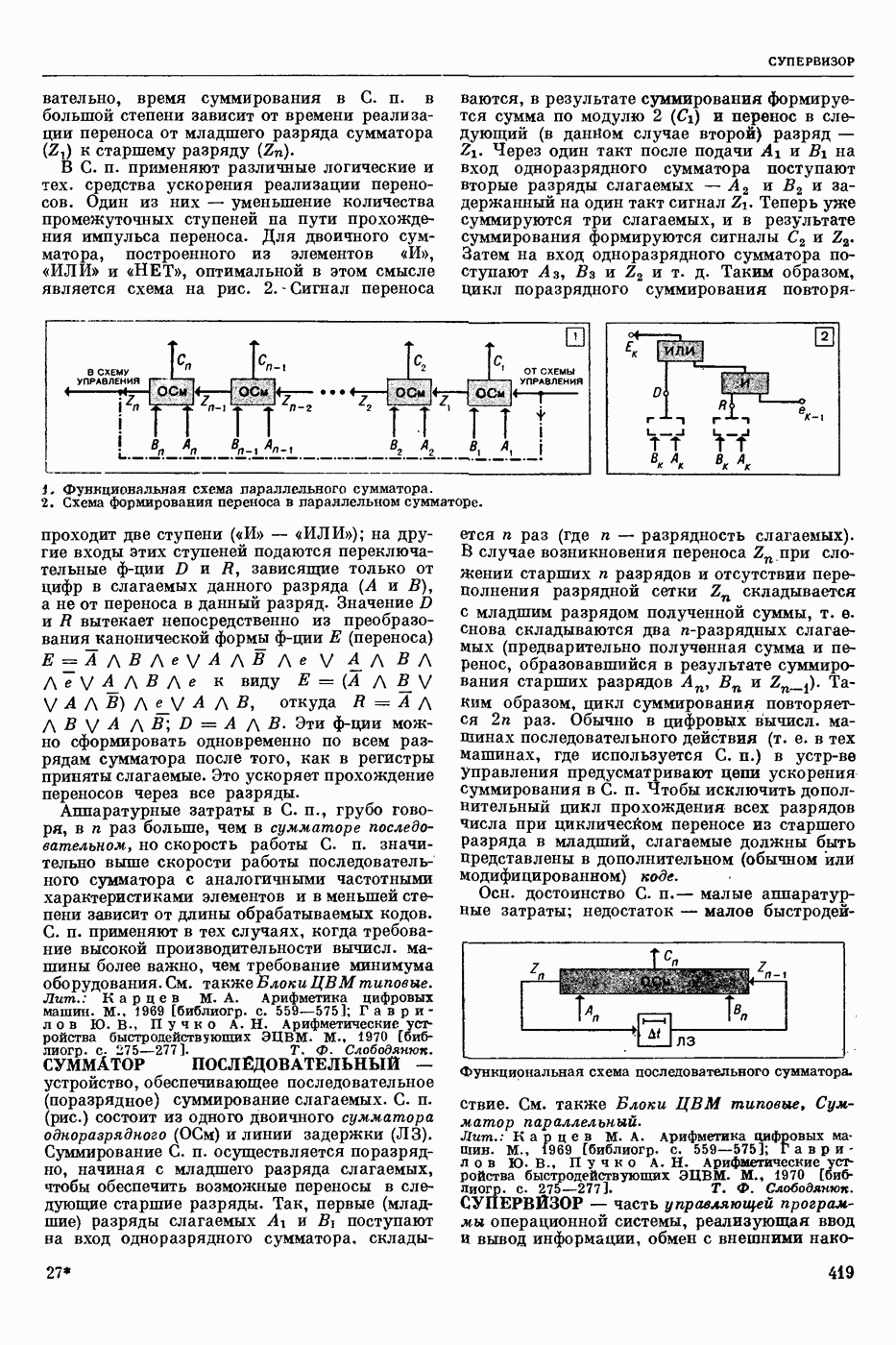
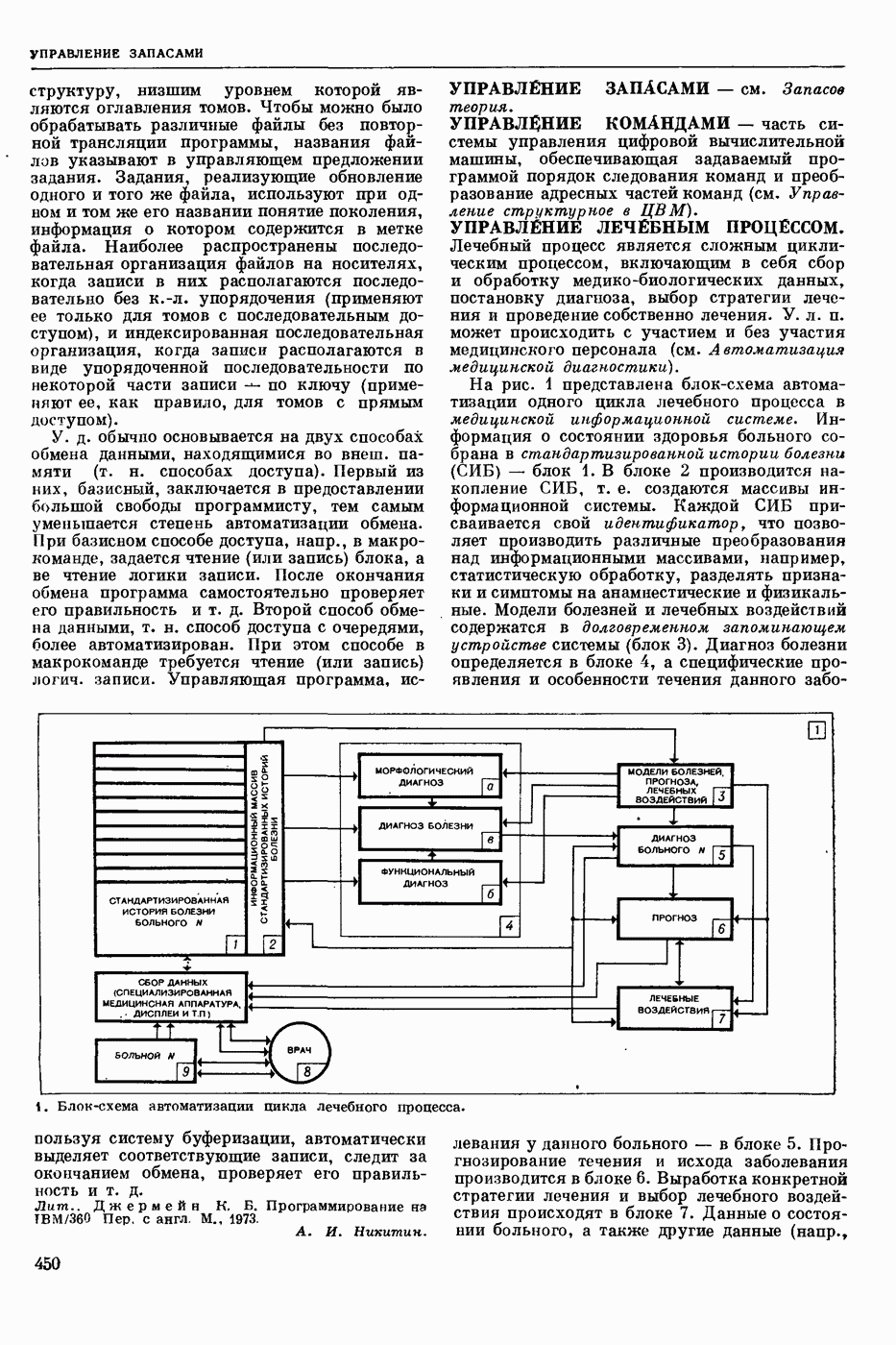
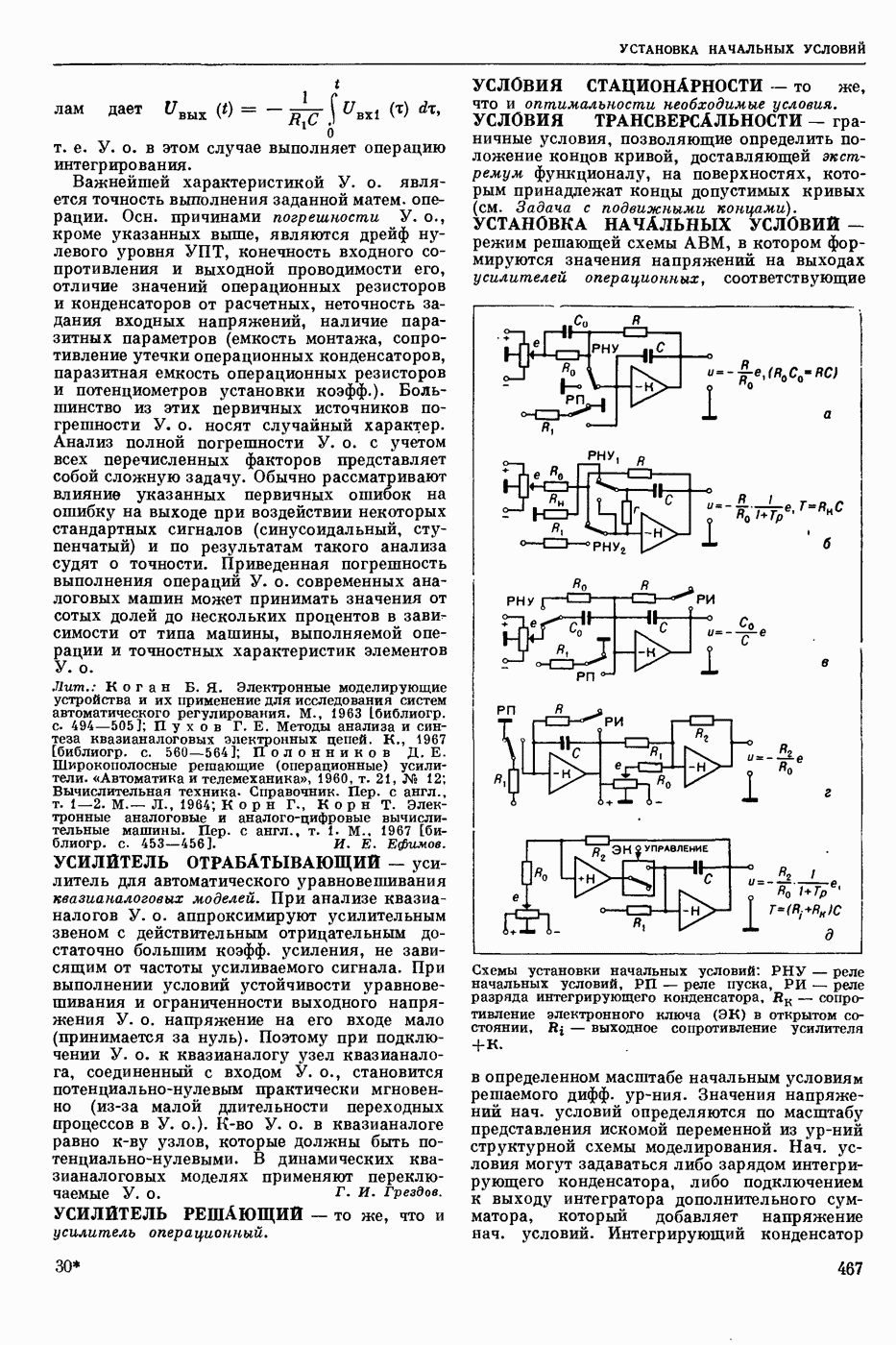
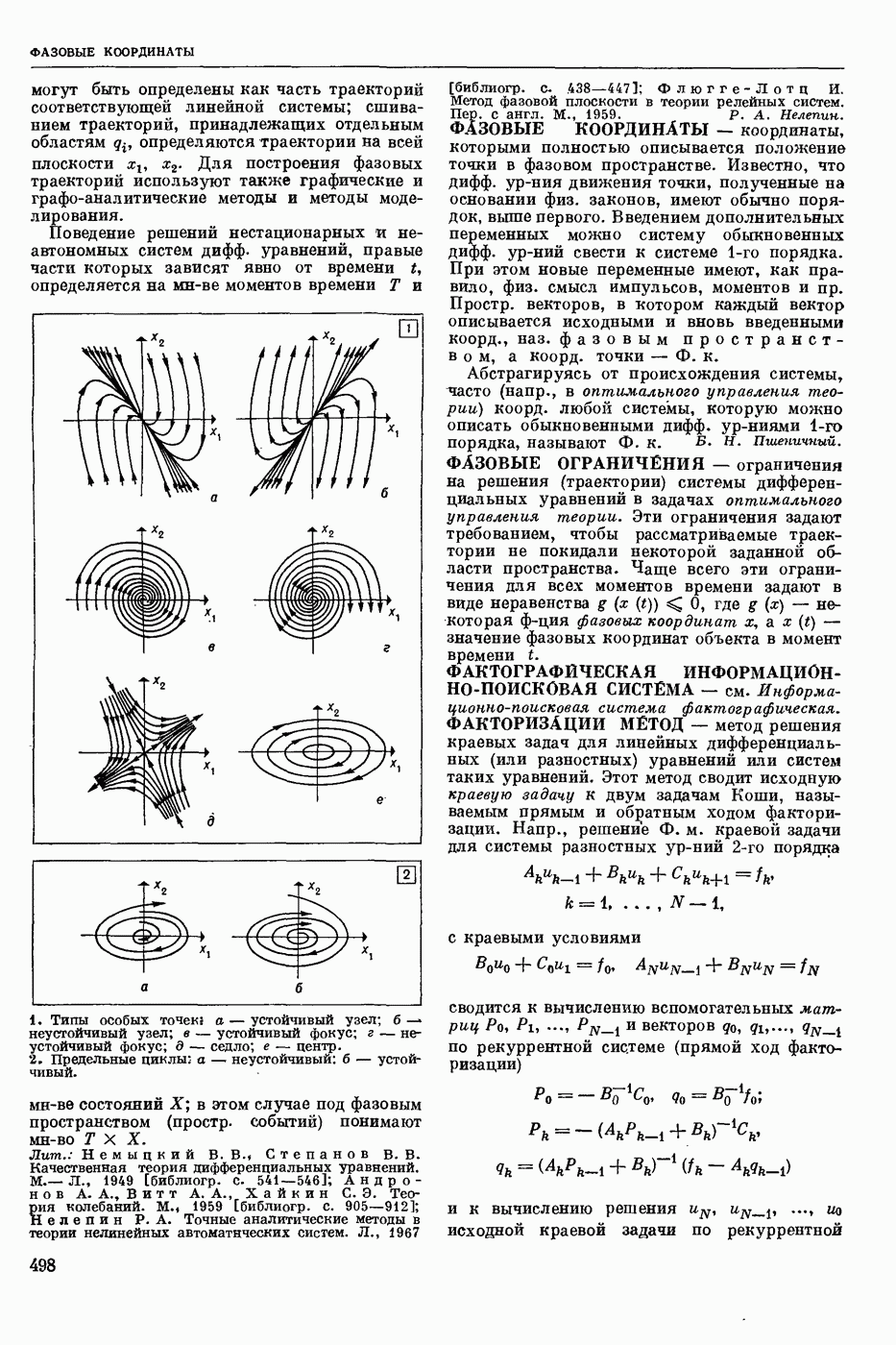
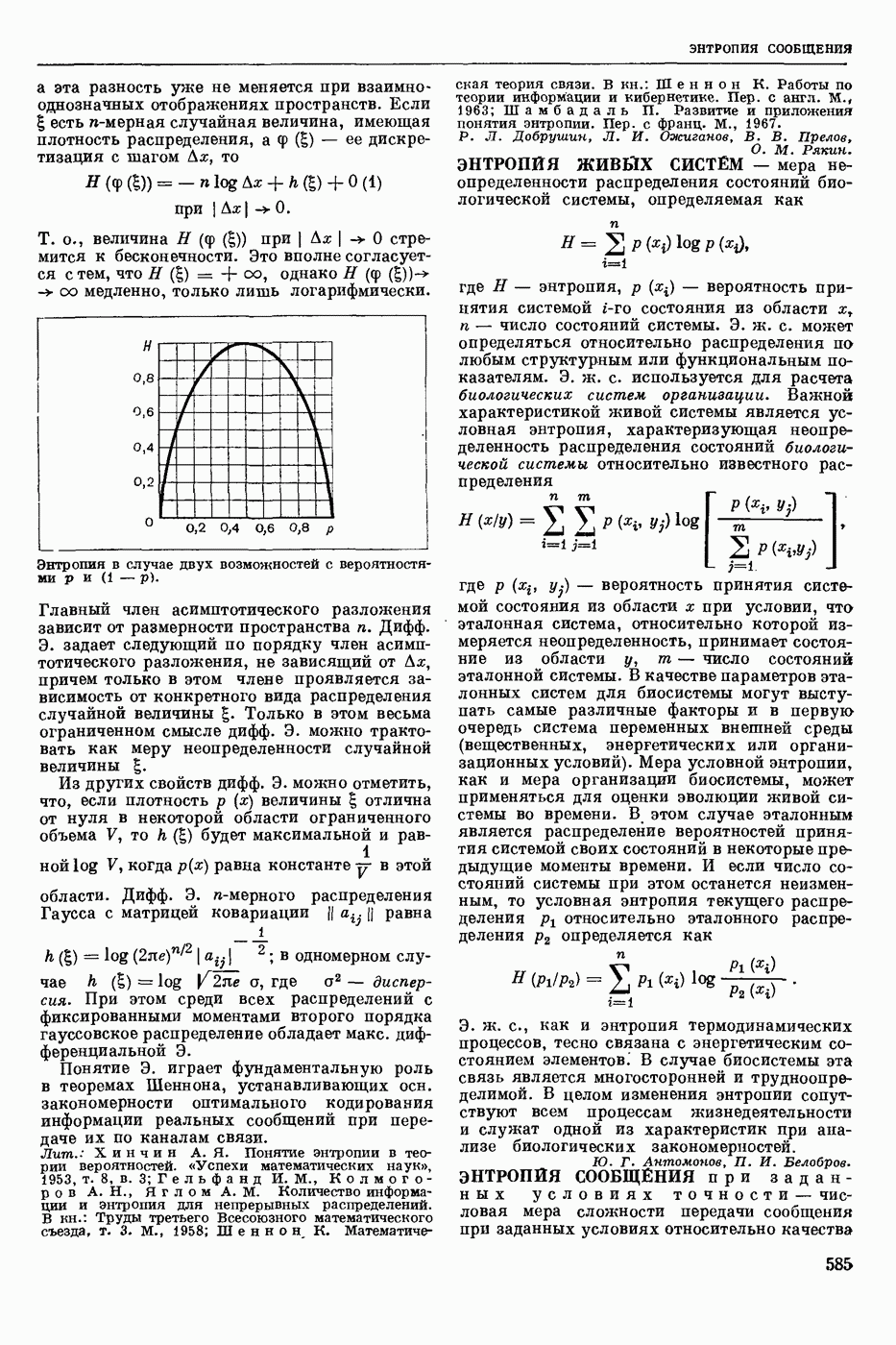
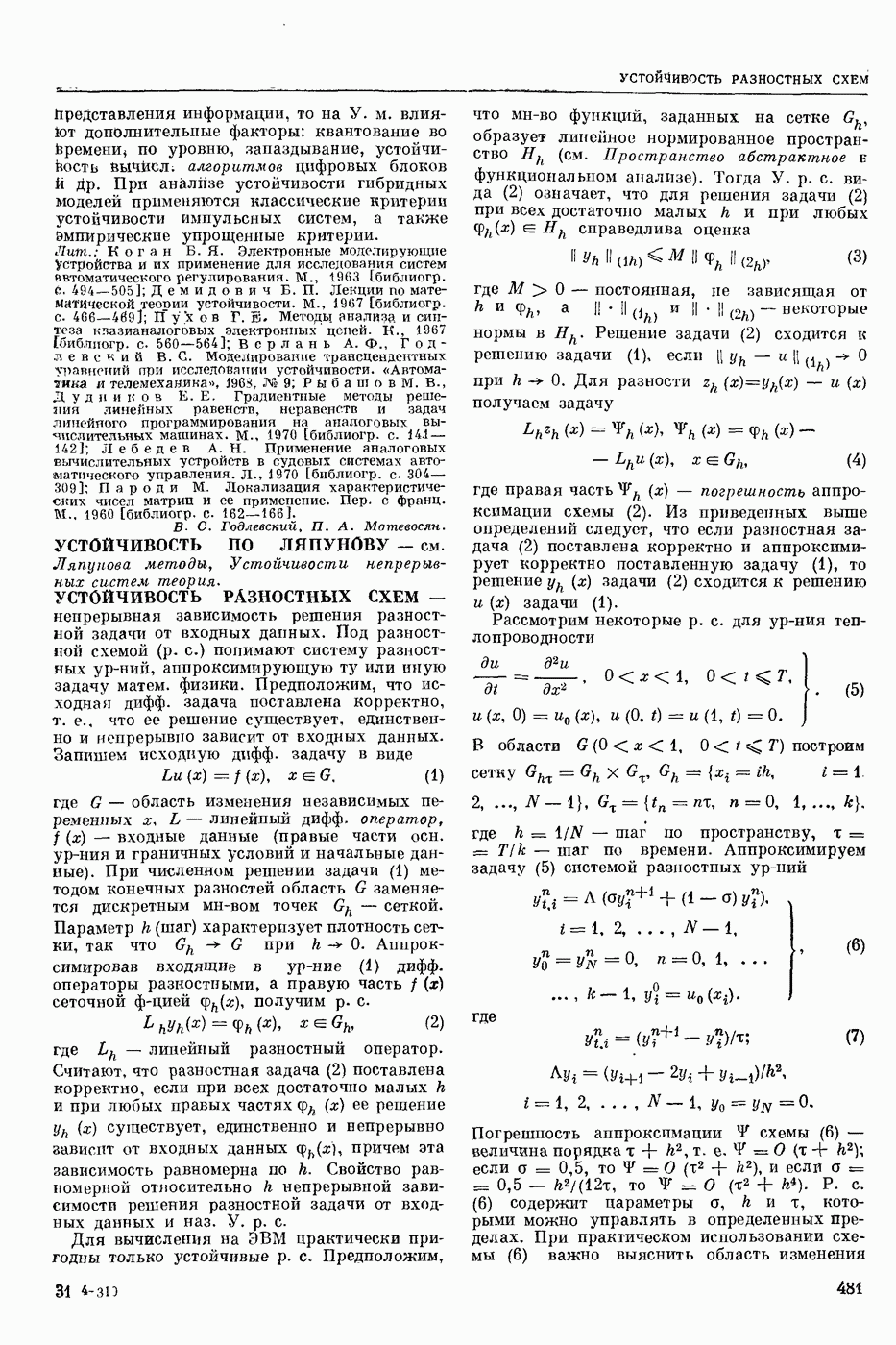Задача автомат. Р. з. о. возникает в тех случаях, когда необходимо обрабатывать большое к-во каких-либо изображений и желательно поручить эту работу машине. Напр., при необходимости ввести в ЦВМ информацию, содержащуюся в печатных или рукописных документах, желательно избежать ручного перфорирования. Для автоматизации ввода необходимо устр-во, которое распознает изображение каждой буквы (или цифры), т. е. определяет наименование буквы и посылает в ЦВМ код этого наименования. Таким образом, в один класс попадают изображения, соответствующие буквам одного наименования. Изображения могут отличаться особенностями начертания, присущими различным шрифтам или почеркам, а также всевозможными случайными помехами — непропечаткой отдельных частей, наличием загрязнений и т. п. Задача Р. з. о. возникает также в случаях, когда надо принимать решения об изображениях быстрее или надежнее, чем это могут делать люди.
Типичными и важнейшими задачами Р. з. о. являются, помимо указанной выше задачи ввода текстов в ЦВМ, анализ фотографий треков частиц, получаемых при физ. экспериментах, автоматизация дешифровки аэрофотоснимков, анализ микрофотографий биол. объектов, напр., кровяных телец, и др.
Сравнительно простой можно считать задачу распознавания печатных цифр или букв определенного шрифта. Для ее решения было предложено большое к-во разнообразных методов. В большинстве методов ради простоты реализации использовалась лишь часть информации, содержащейся в изображении: измерялась яркость (или почернение) только отдельных участков поля зрения (метод зондов, фрагментов), с помощью следящей развертки прослеживался контур — непрерывная граница белого и черного полей изображения и т. п. Все эти методы оказались недостаточно помехоустойчивыми.
Тщательное изучение проблемы Р. з. о. показало, что для знаков фиксированного шрифта могут быть построены несложные математические модели объектов распознавания. Исследование таких моделей позволило сравнить различные методы распознавания и внести существенные усовершенствования в некоторые из них. Многочисленные теор. и экспериментальные работы показали, что для распознавания знаков фиксированного шрифта наиболее помехоустойчивым является метод сравнения изображений с эталонами или масками. Эталоны представляют собой идеализированные изображения всех знаков алфавита.
Сравнение осуществляется следующим образом. С помощью аппаратуры, в принципе подобной телевизионной передающей трубке, изображение разлагается на много элементарных ячеек, образующих прямоугольный растр. В каждой ячейке измеряется яркость или другая оптическая величина, характеризующая «черноту» данного участка изображения. Набор результатов таких измерений можно рассматривать как вектор, компоненты которого равны значениям яркости для каждой ячейки растра. Аналогичными векторами представлены эталоны. Скалярное произведение вектора изображения на вектор эталона характеризует их сходство (см. Сходства критерии). По аналогии с подобными вычислениями в вероятностей теории это скалярное произведение наз. коэффициентом корреляции (см. Корреляционный метод распознавания). Необходимо найти эталон, дающий наибольший коэффициент корреляции с данным изображением. Его наименование или соответствующий код является результатом распознавания. Сравнение данного изображения с эталонами приходится производить многократно при различных их взаимных расположениях, т. к. точное расположение изображения заранее неизвестно, а предварительное определение его к.-л. более простым способом (т. н. центрирование) не помехоустойчиво.
Подобный сравнительно простой способ распознавания применим только в простейших случаях, когда изображения одного класса имеют одно и то же начертание и постоянные размеры. Однако и в этом простейшем случае возникают трудности, связанные, напр., с непостоянством толщины и контраста линий, со случайными смещениями (переносами) изображений относительно растра. Для преодоления этих трудностей приходится строить по нескольку эталонов для каждого класса и вводить другие усложнения.
При автомат, чтении текстов, помимо распознавания отдельных знаков, возникает задача членения строки на знаки. Машинописные знаки обычно не разделены отчетливыми пробелами, поэтому возникает проблема распознавания сложного изображения, составленного из известных элементарных частей. В качестве сложных изображений рассматривают также буквы произвольных начертаний, составляемые из прямолинейных отрезков и дуг, снимки треков, различные чертежи и т. п.
Т. н. лингвистический подход к анализу сложных изображений состоит в том, что набор известных правил, по которым сложные изображения составляют из данных элементарных частей, рассматривается как грамматика формальная. В этом случае проблема распознавания сводится к формально - синтаксическому анализу сложного изображения. Напр., при распознавании букв элементарные части представляют собой всевозможные прямолинейные отрезки и дуги, а грамматика — набор правил, по которым нужно построить первый отрезок, а затем присоединять новые части к частично построенному изображению, чтобы получилась определенная буква. Анализ состоит в том, что для данного изображения к.-л. способом, выходящим за рамки лингвистического подхода, обнаруживают все отрезки (и дуги), а затем делают проверку, есть ли среди них отрезок, могущий играть роль первого при построении определенной буквы по заданным правилам. Затем следует проверка того, присоединен ли к нему должным образом второй отрезок и т. д. В случае обнаружения какого-либо
несоответствия с правилами принимается решение о том, что данное изображение не принадлежит к мн-ву допустимых.
Лингвистический подход имеет существенный недостаток: он дает правильный результат только тогда, когда все элементарные части распознаны безошибочно. На практике такое требование трудно выполнить, т. к. реальные изображения всегда в большей или меньшей степени искажены различными помехами. В связи с этим практическим потребностям лучше соответствует такая более сложная постановка задачи распознавания или анализа сложных изображений: заданы правила составления эталонных изображений из элементарных частей; для каждого наблюдаемого (искаженного помехами) изображения необходимо найти наиболее похожее на него эталонное изображение из числа допустимых. Количественное измерение сходства осуществляется на основе знания статистических характеристик помех. Решение подобной задачи связано в общем случае с определенными матем. трудностями. Однако многие частные задачи, как, напр., членение строки и анализ треков, могут быть успешно решены.
Для экспериментальной проверки различных методов распознавания наиболее удобным и универсальным является способ моделирования на ЦВМ. Машина должна быть снабжена спец. вводным устр-вом, осуществляющим развертку изображения, т. е. измерение его яркости (или другой оптической характеристики) во всех нужных ячейках растра. Результаты измерения яркости вводятся в цифровой форме в ЦВМ. Распознавание осуществляет ЦВМ, которая обрабатывает введенные данные по спец. программе. Такой способ позволяет легко и быстро сравнивать эффективность различных методов распознавания до того, как эти методы будут воплощены в соответствующую аппаратуру. При этом легко вносить в них усовершенствования, т. к. переделывать нужно только программу для ЦВМ.
Однако для практического применения распознавание с помощью ЦВМ большей частью непригодно, т. к. даже самые быстродействующие ЦВМ выполняют распознавание слишком медленно. Для распознавания одного изображения требуются десятки секунд или даже несколько минут. Это объясняется тем, что ЦВМ выполняет все операции последовательно. Для практического применения создают специализированные вычисл. устр-ва, в которых многие необходимые операции выполняются параллельно, хотя и с меньшей, чем в ЦВМ, точностью. Такие устр-ва, предназначаемые гл. обр. для распознавания букв и цифр, наз. читающими автоматами.
Создание таких автоматов является важным практическим применением Р. з. о. Другие применения находятся на стадии лабораторных экспериментов. Наиболее впечатляющим из этих экспериментов является созданная в Станфордском университете (США) система «глаз — рука», где управление мех. рукой осуществляет большая и очень быстродействующая ЦВМ, снабженная телевизионной камерой и программами для распознавания простейших объектов реального мира: кубиков различных размеров. Машина может по данному ей заданию брать с пола кубики нужной формы и складывать из них пирамиду. Предполагают, что в будущем подобные системы послужат для создания «зрячих» роботов.
В. А. Ковалевский.