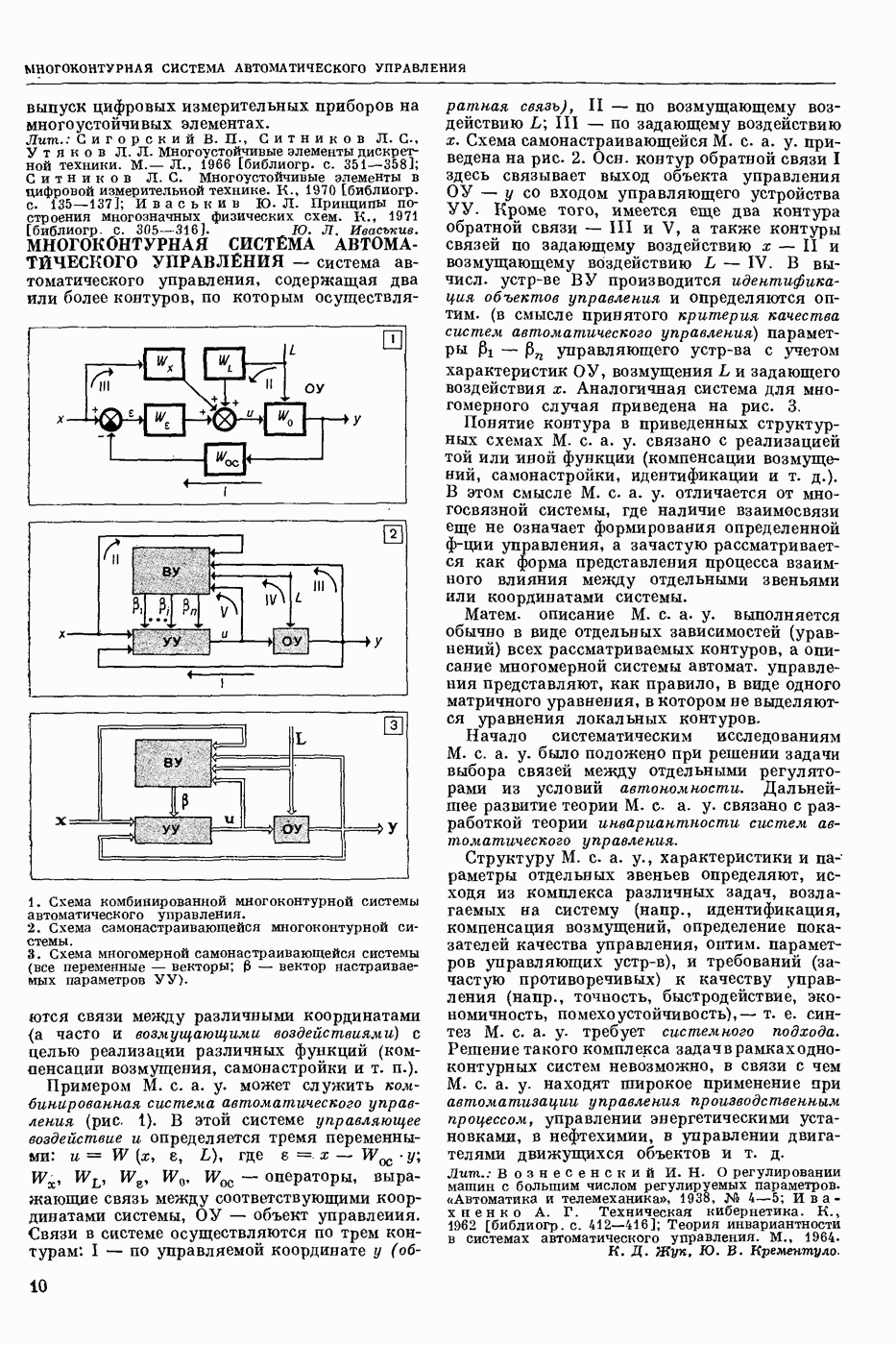
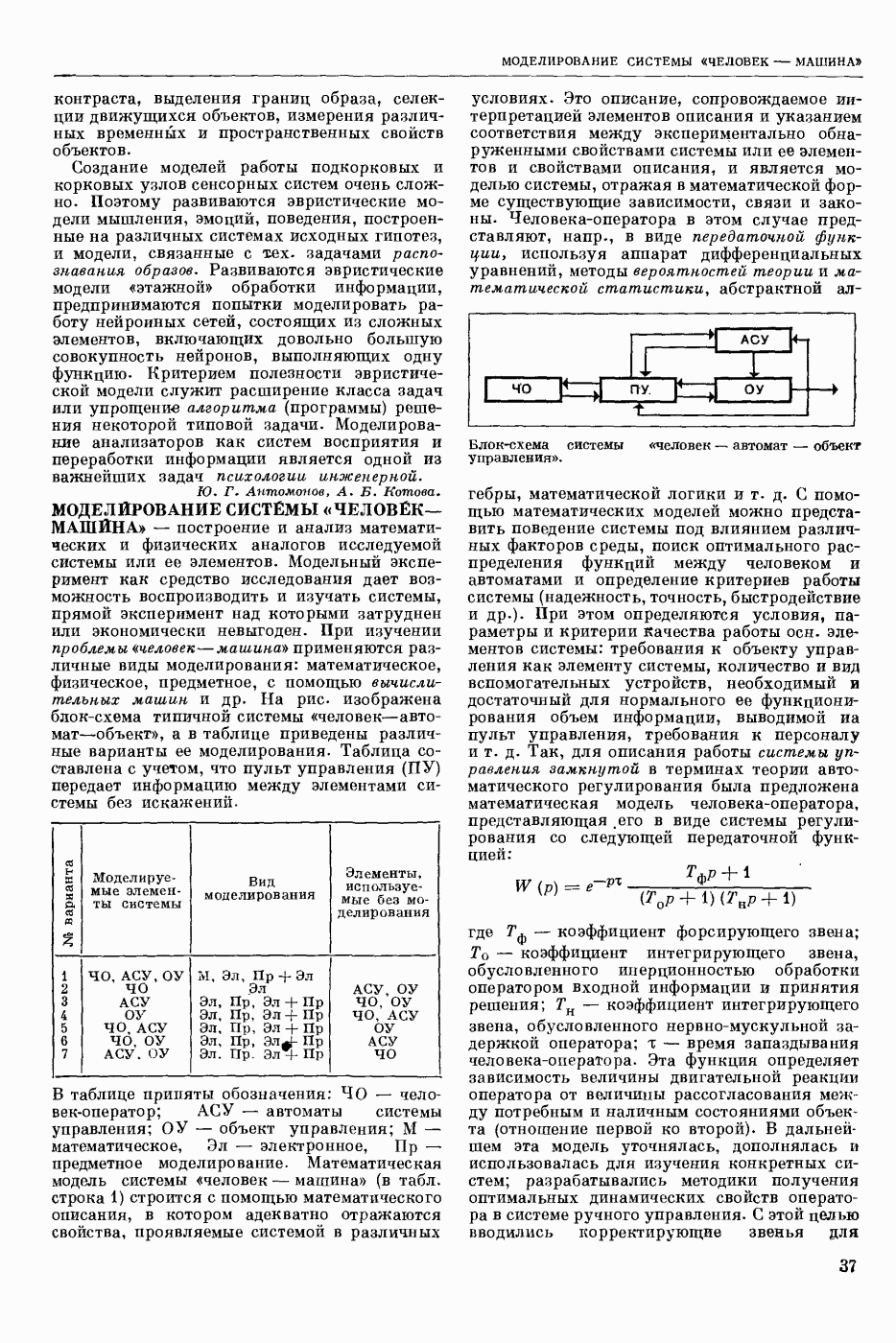
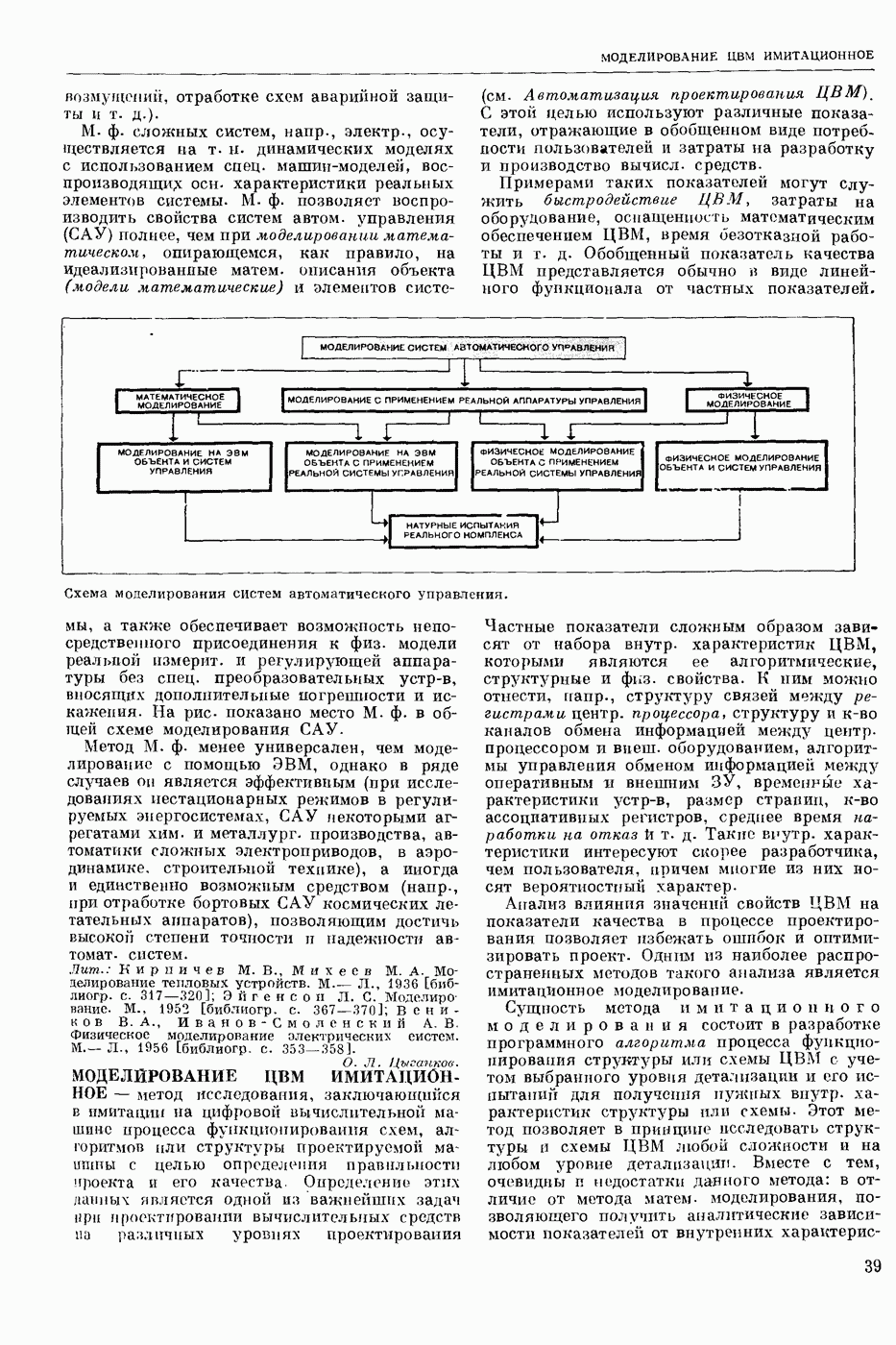
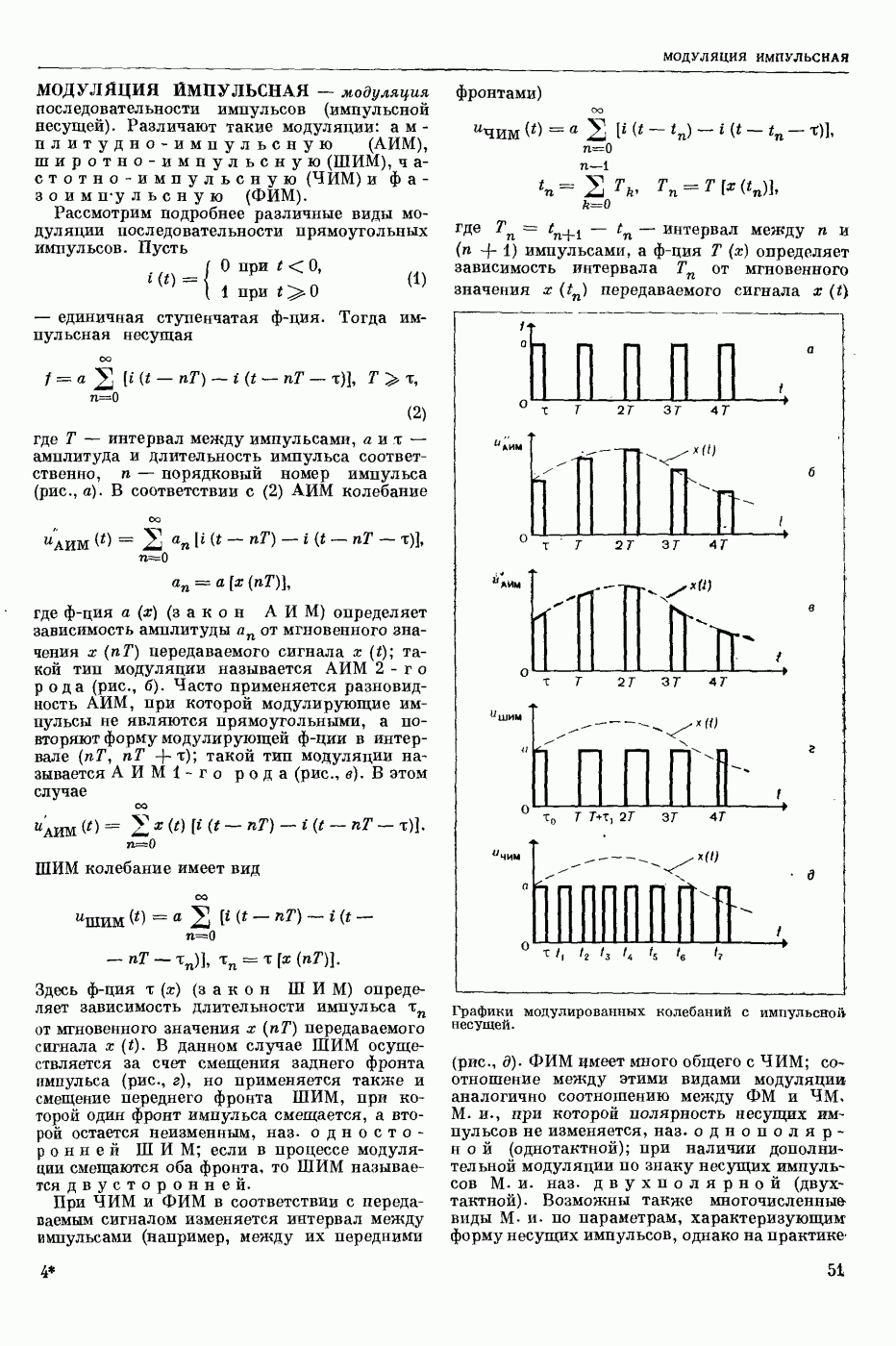
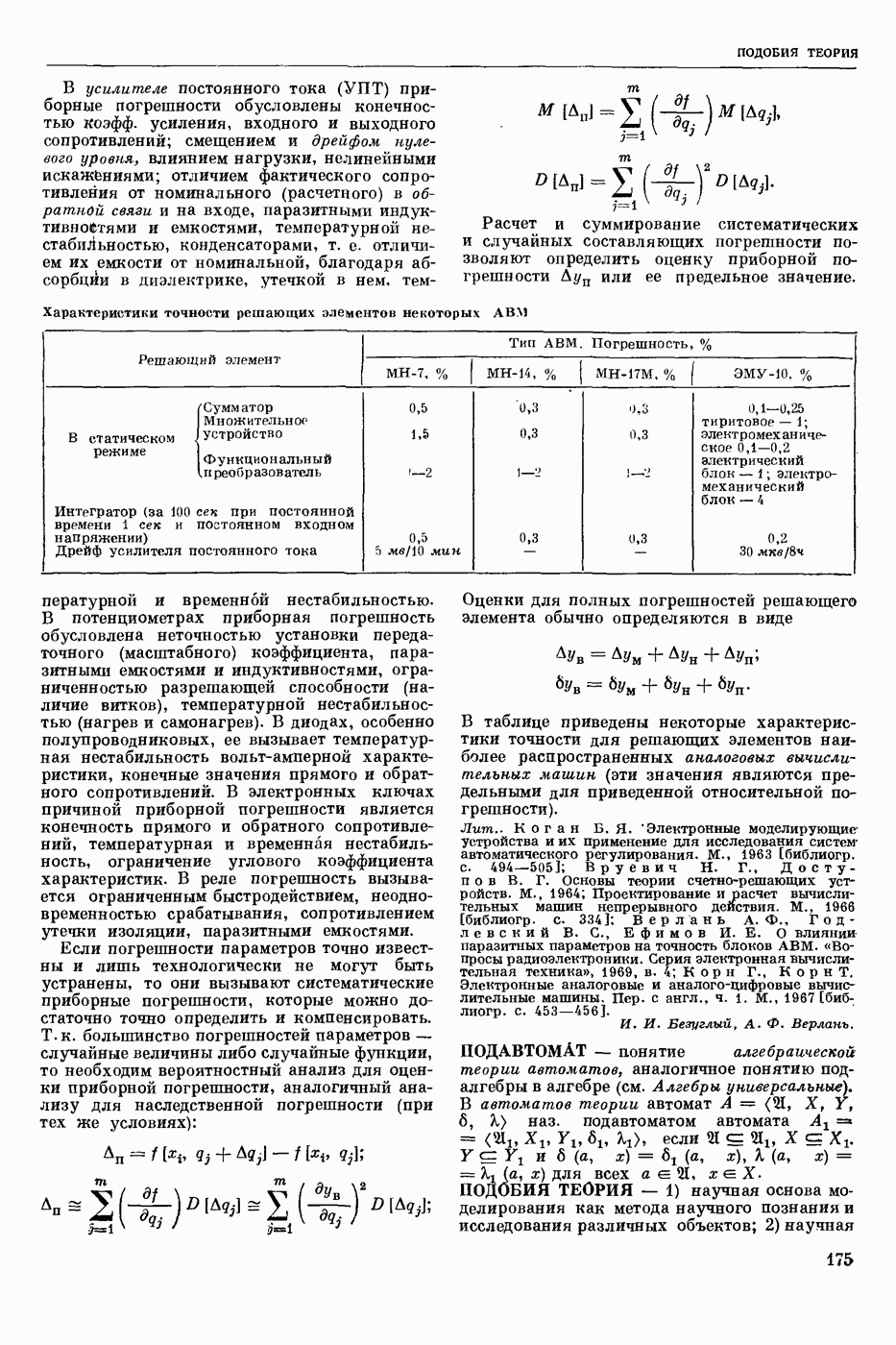
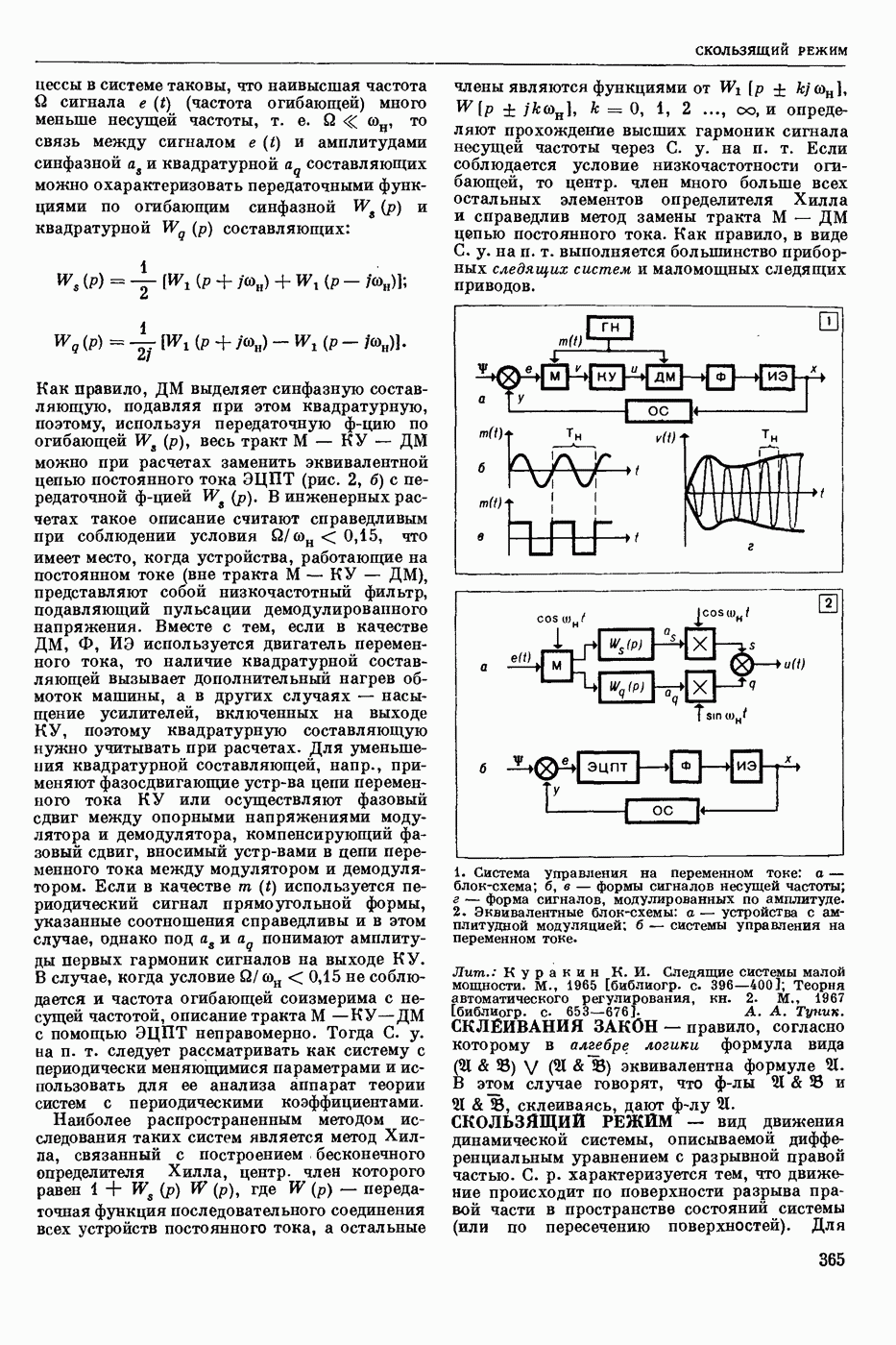
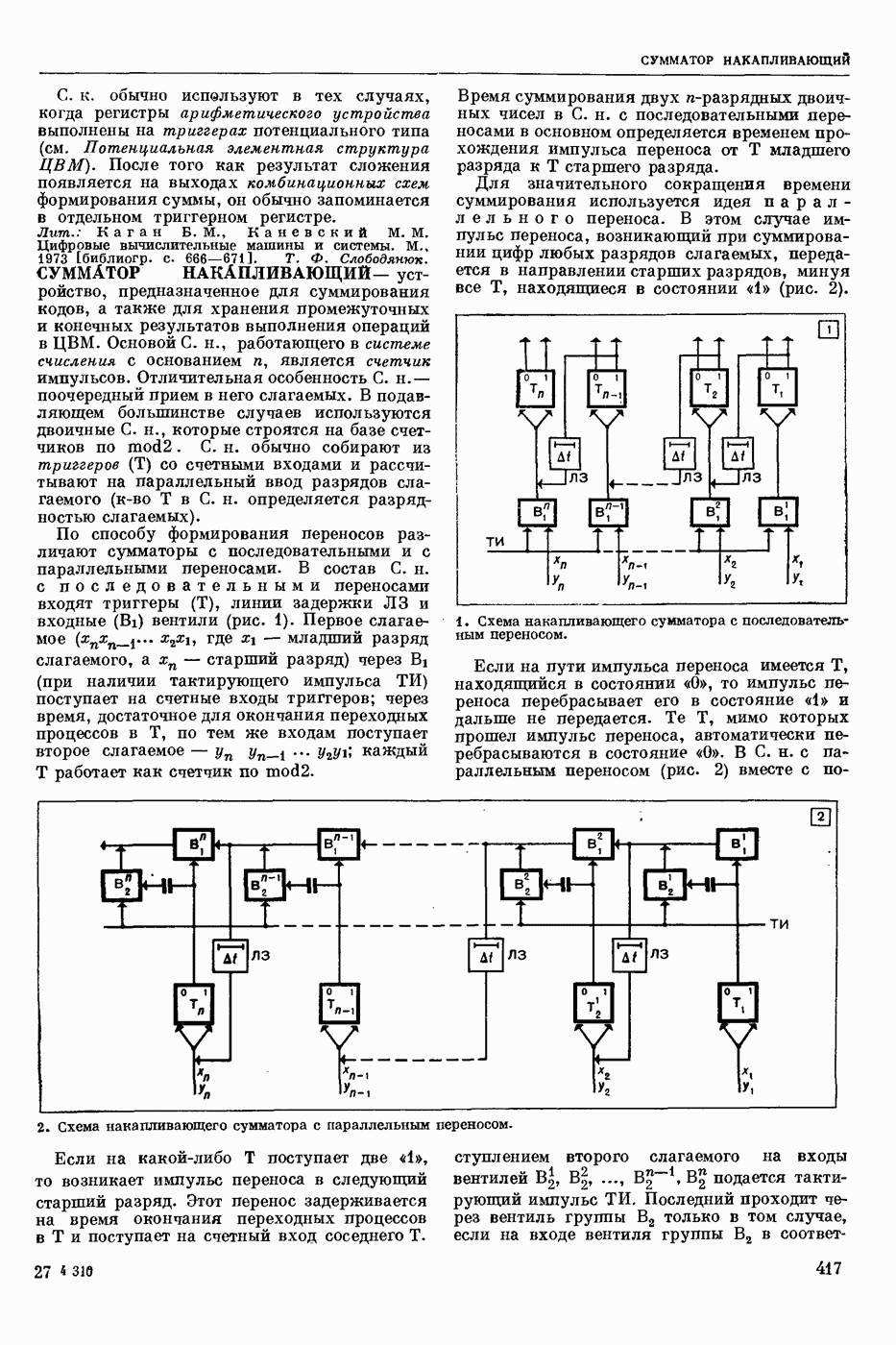
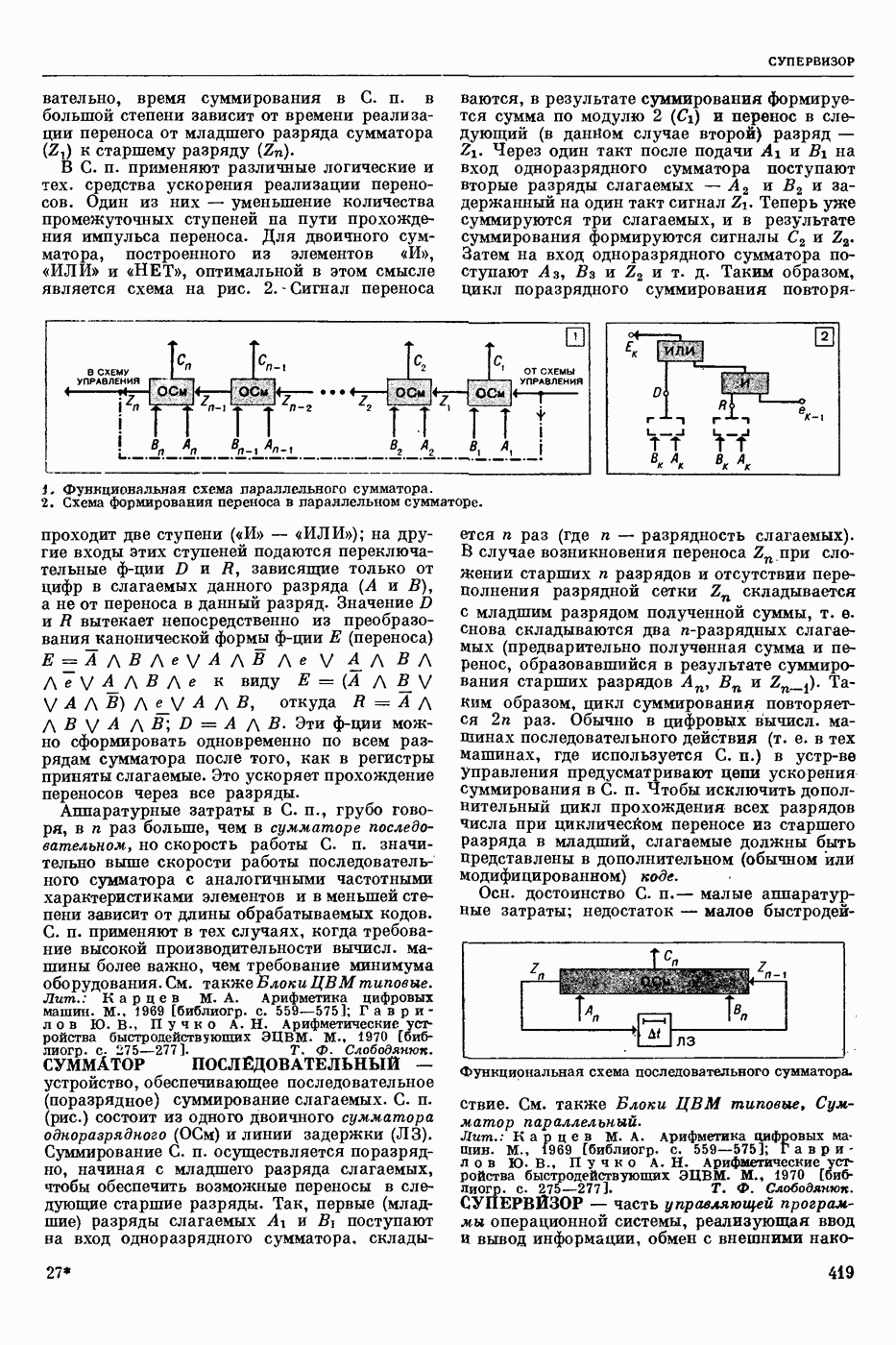
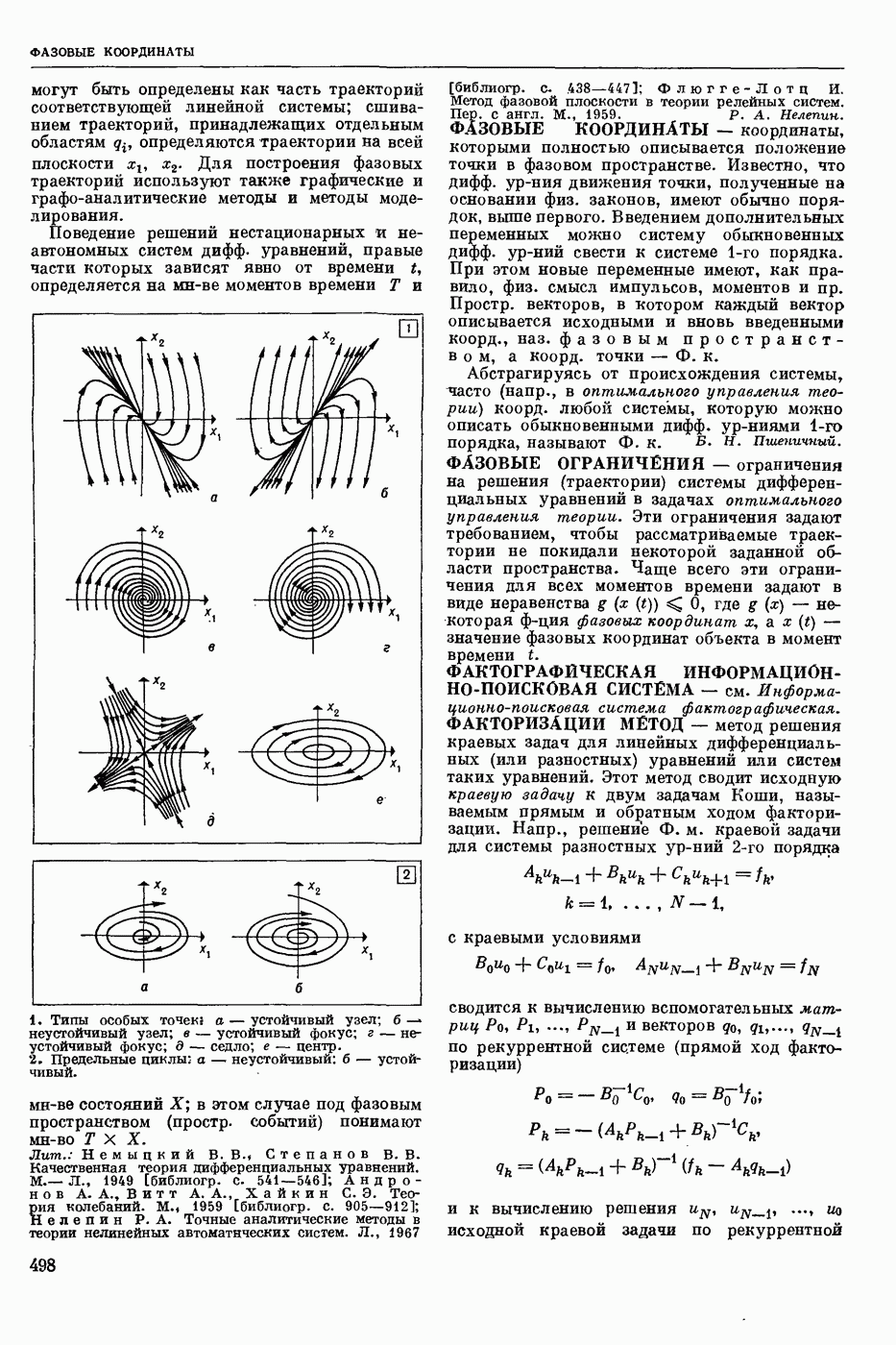
РАСПОЗНАВАНИЕ РЕЧЕВЫХ СИГНАЛОВ
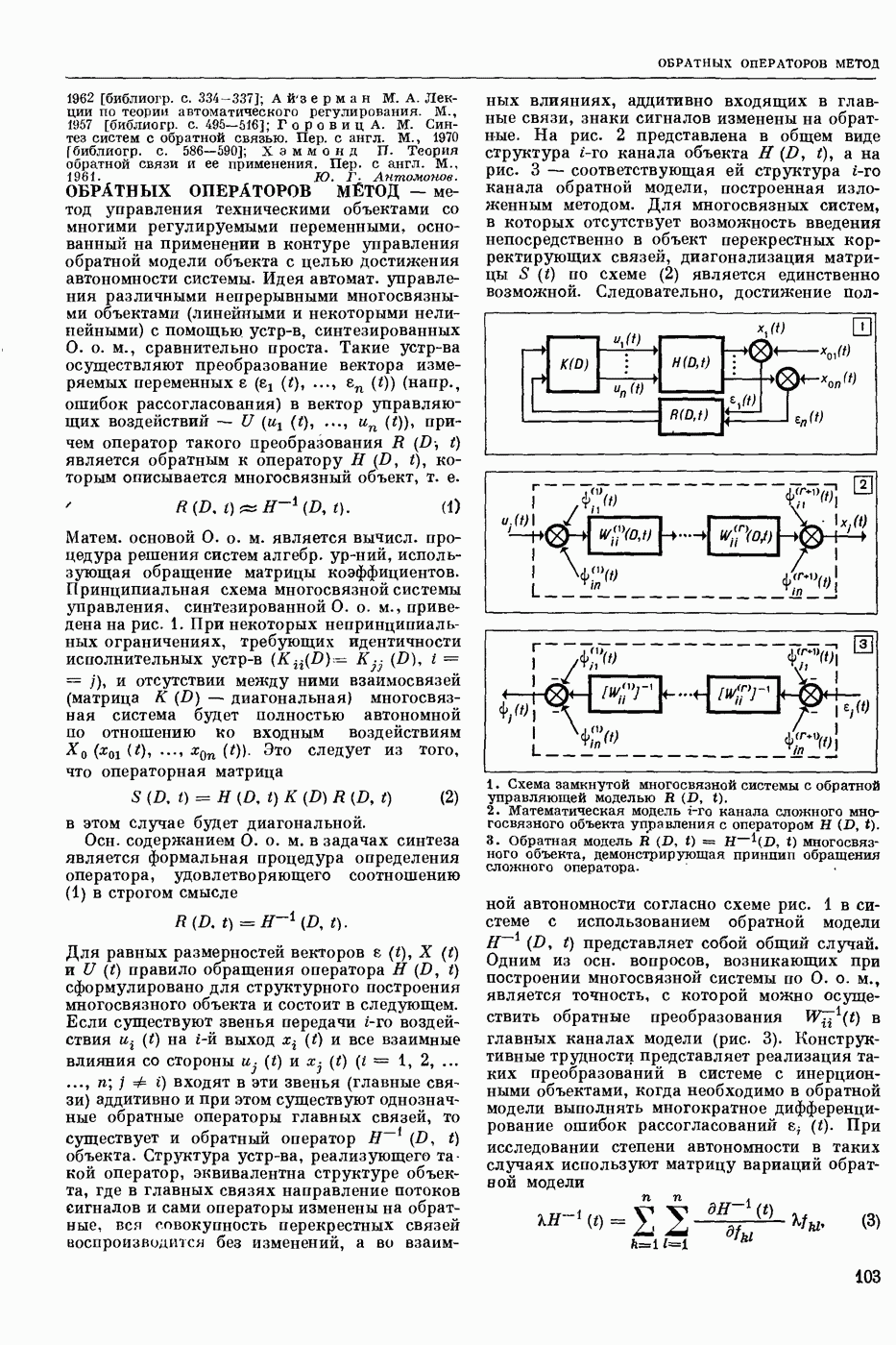
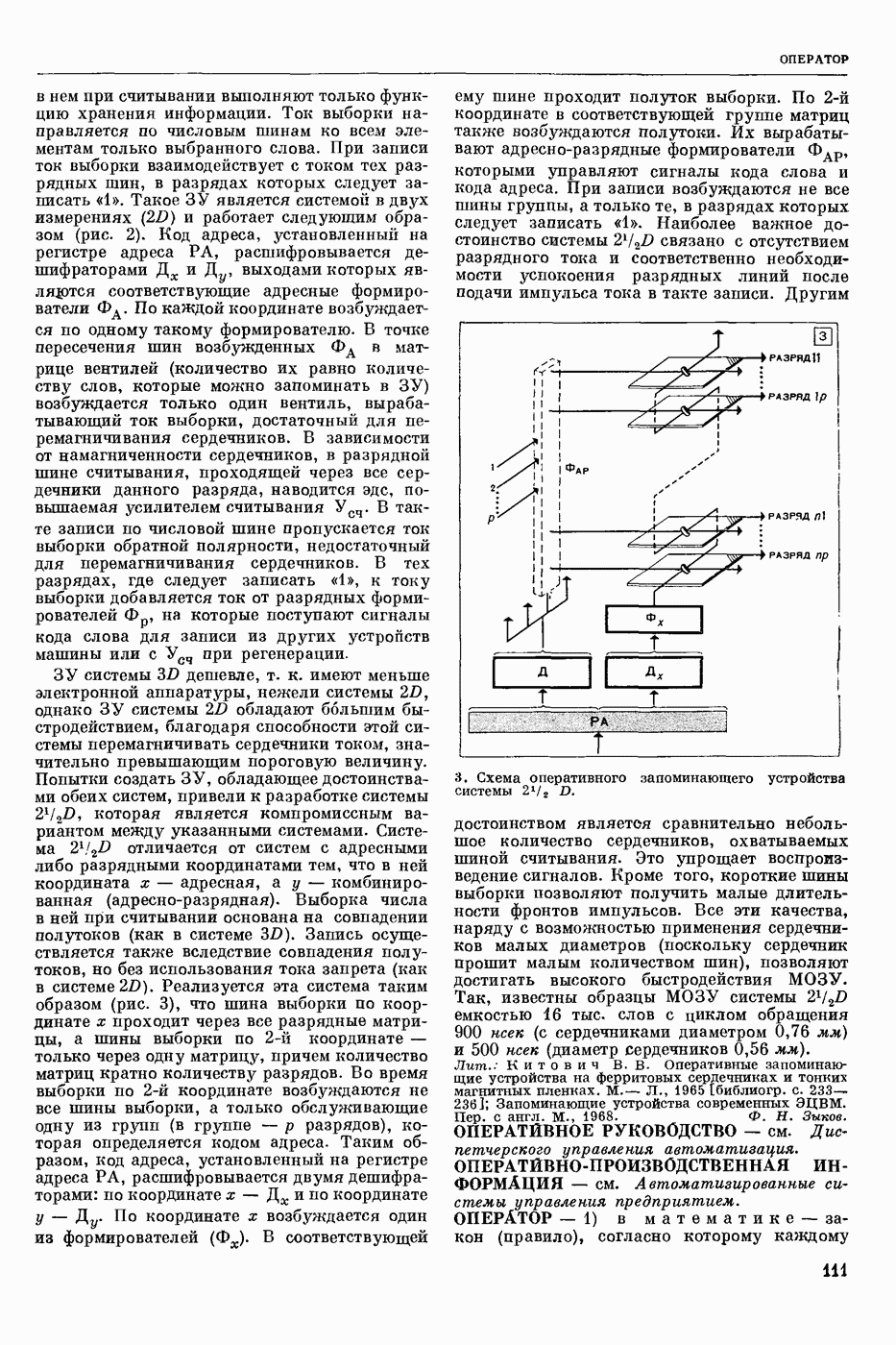
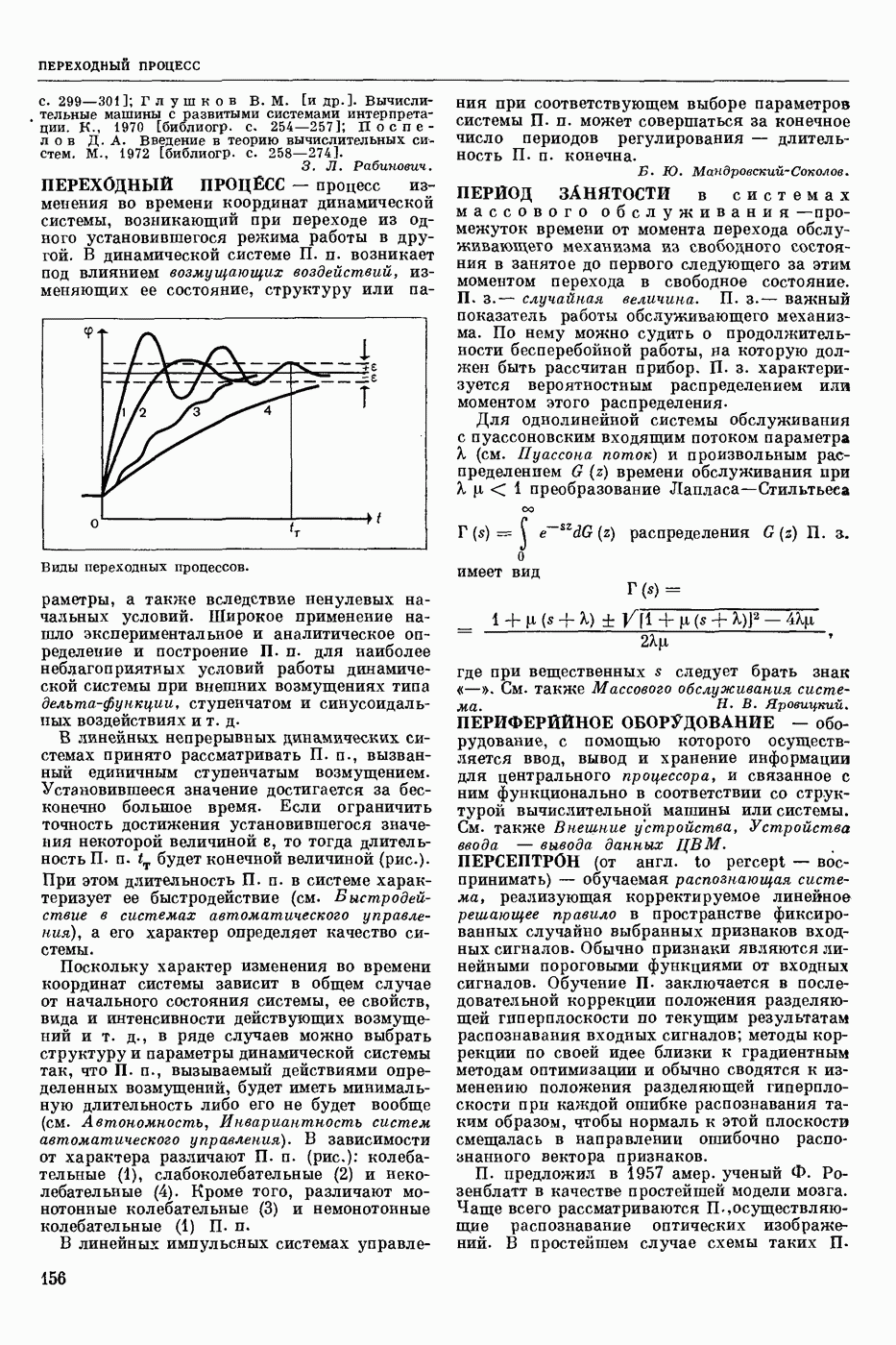
- автоматическое отнесение предъявленного речевого сигнала к одному из заранее выбранных классов. Решение задачи Р. р. с. означает нахождение способа классификации речевых сигналов, наиболее точно соответствующего классификации, осуществляемой человеком.
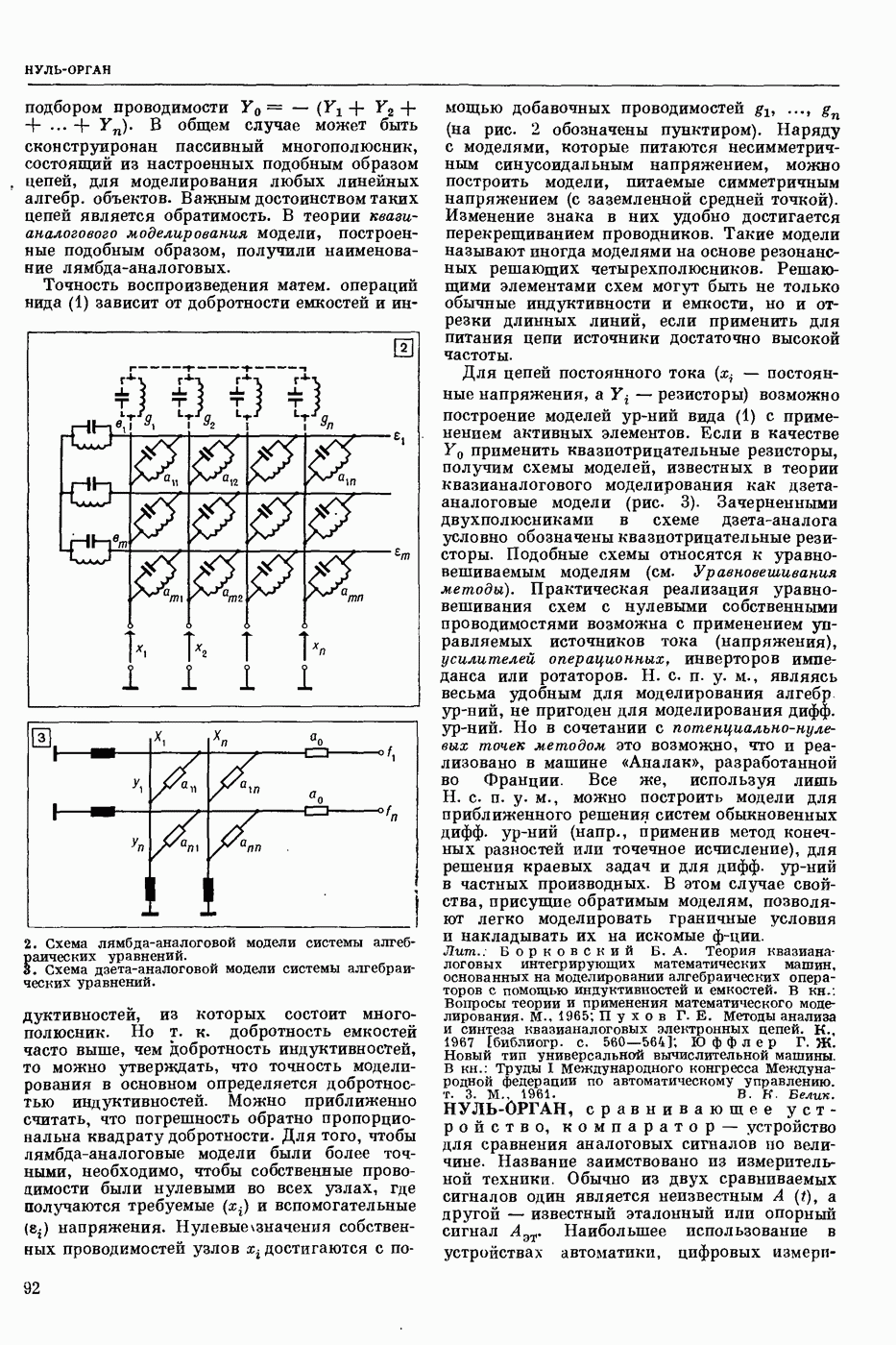
Р. р. с. в широком смысле — это фонемное перекодирование речевого акустического сигнала. Классами речевых сигналов в этом случае являются фонемы. Понятие «фонема» определяется как обозначение всех тех элемевтарных звуков речи, которым соответствует при написании в фонетической транскрипции одна и та же буква или символ.
Р. р. с. в узком смысле — это решение частных задач распознавания речи, когда с целью облегчения решения задачи распознавания искусственно ограничиваются условия, при которых производится классификация. Такой задачей является, напр., распознавание изолированно произнесенных слов из заранее выбранного словаря. В зависимости от поставленной цели ответом при Р. р. с. может быть не только фонема или слово, но также индивидуальность диктора (идентификация личности по ее голосу), его эмоциональное состояние и др.
С созданием речераспознающих автоматов открываются возможности организовать связь
человека с машиной в удобной для человека форме — посредством голоса. В большинстве случаев для управления машинами и механизмами, для ввода в управляющие и вычислительные системы данных и команд посредством голоса достаточно иметь речераспознающие автоматы, которые различают несколько сот слов.
Первые работы по Р. р. с. выполнены в 1943. Этими исследованиями была установлена возможность автоматического Р. р. с. С тех пор предложено много различных устр-в, часто весьма сложных, которые предназначались для пофонемного, послогового или словесного Р. р. с.

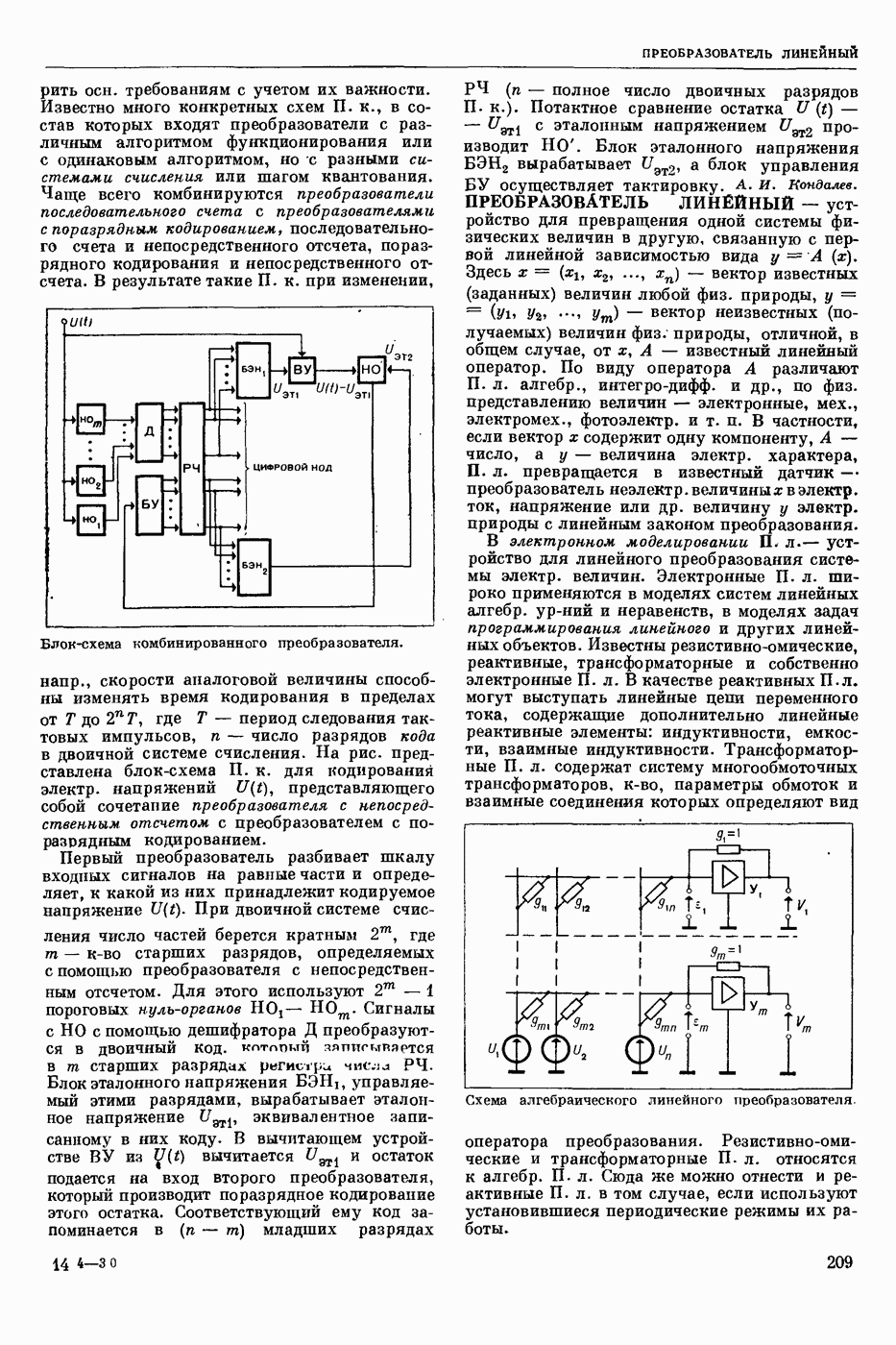
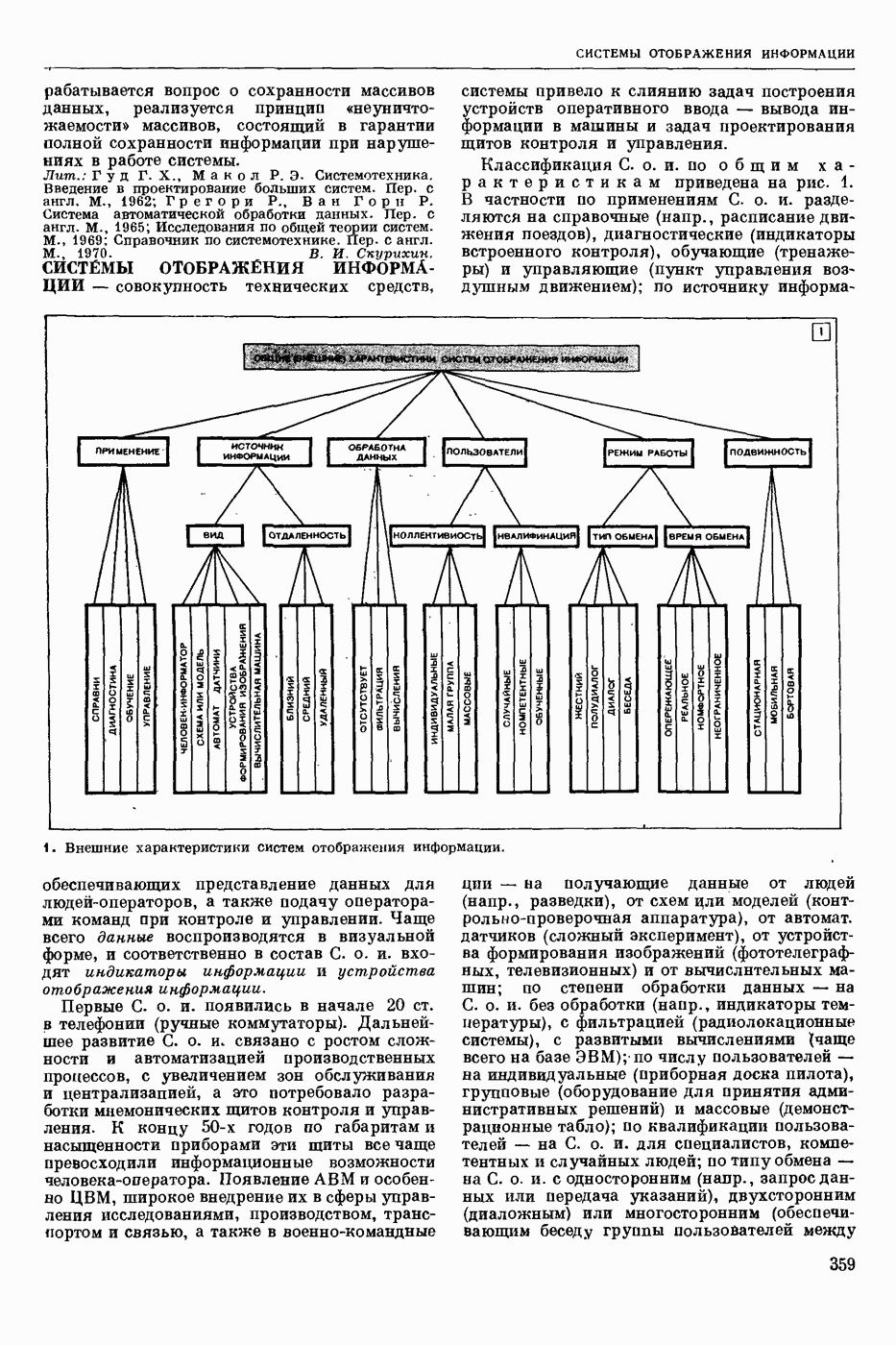
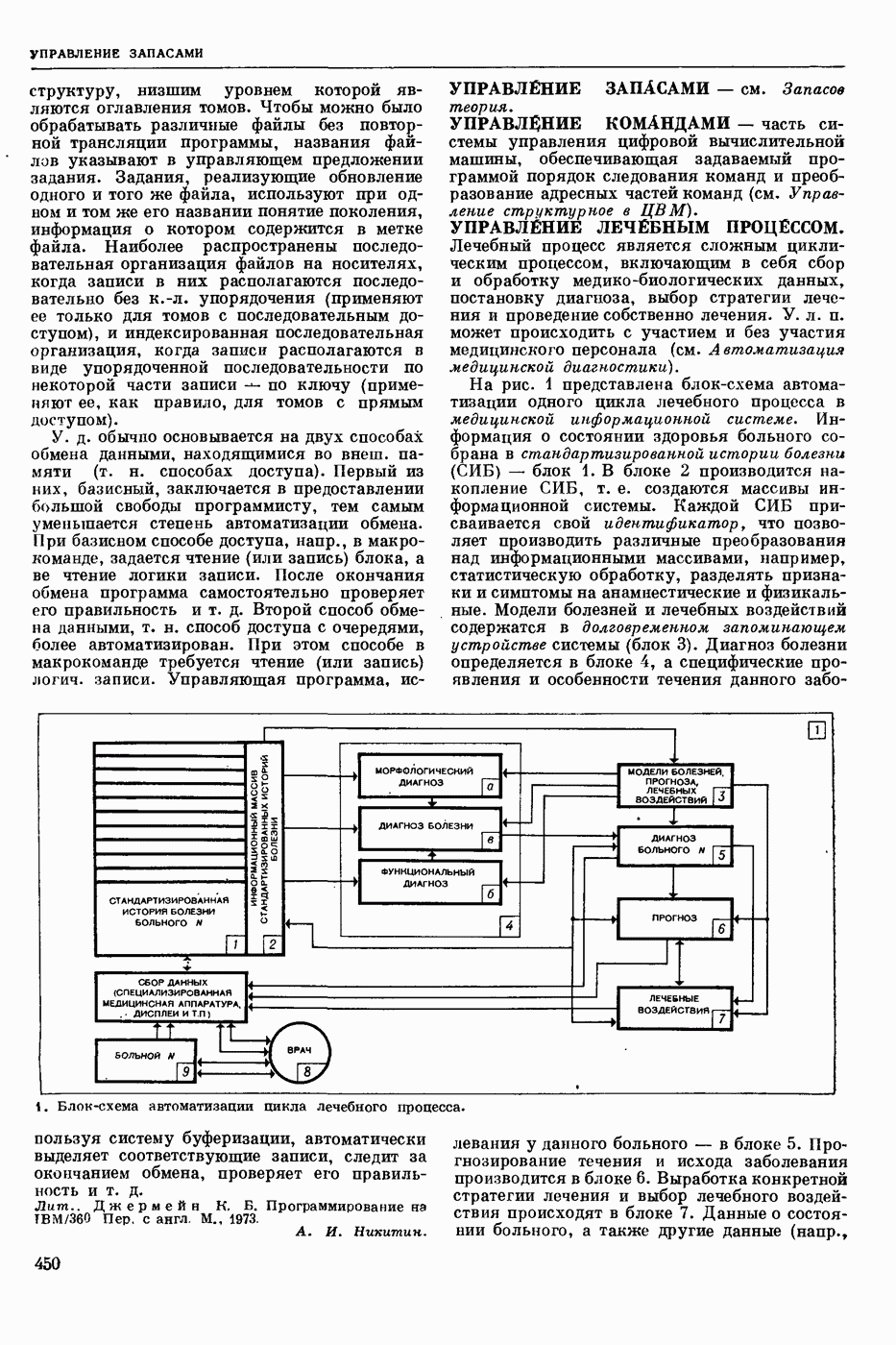
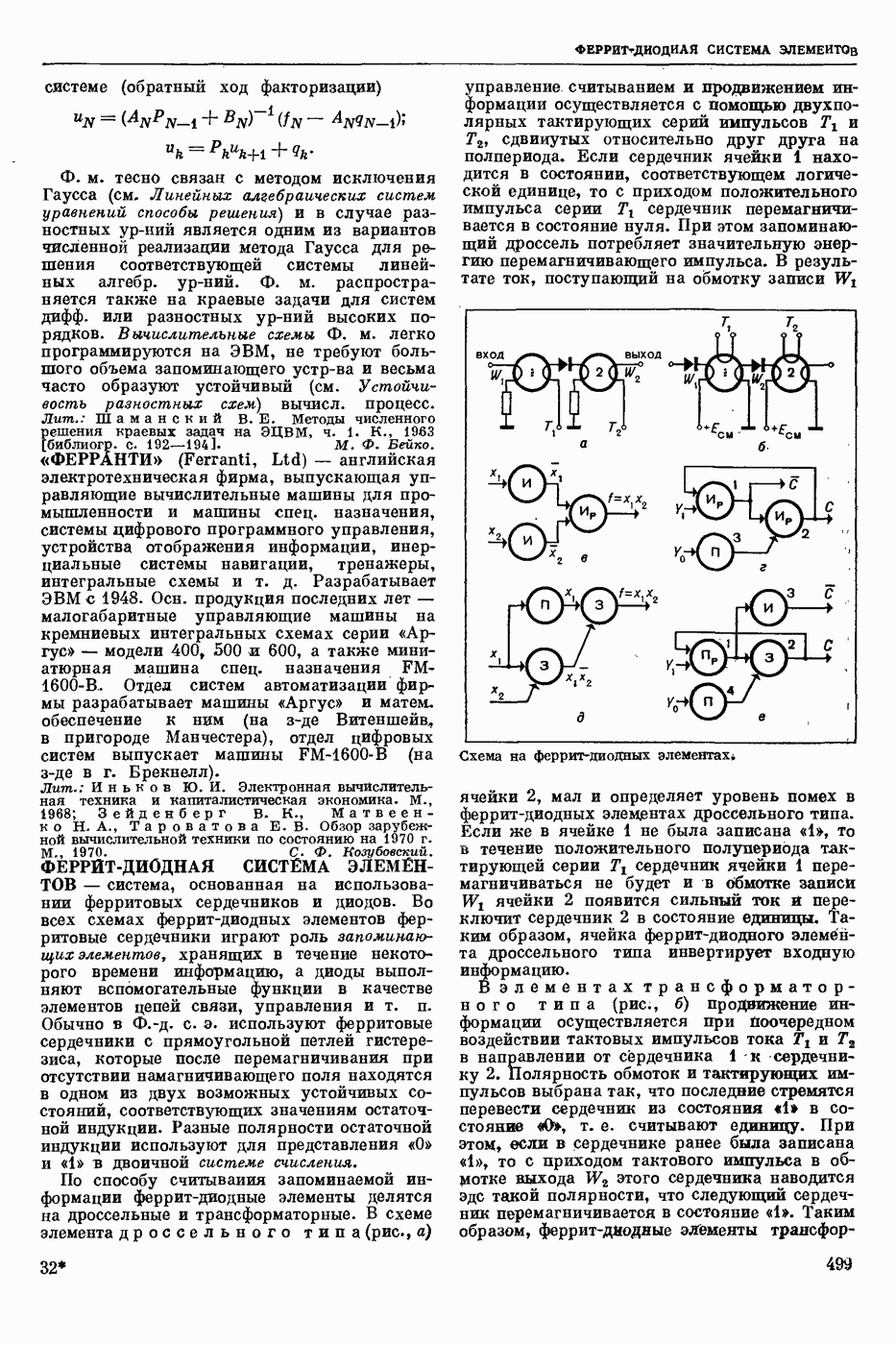
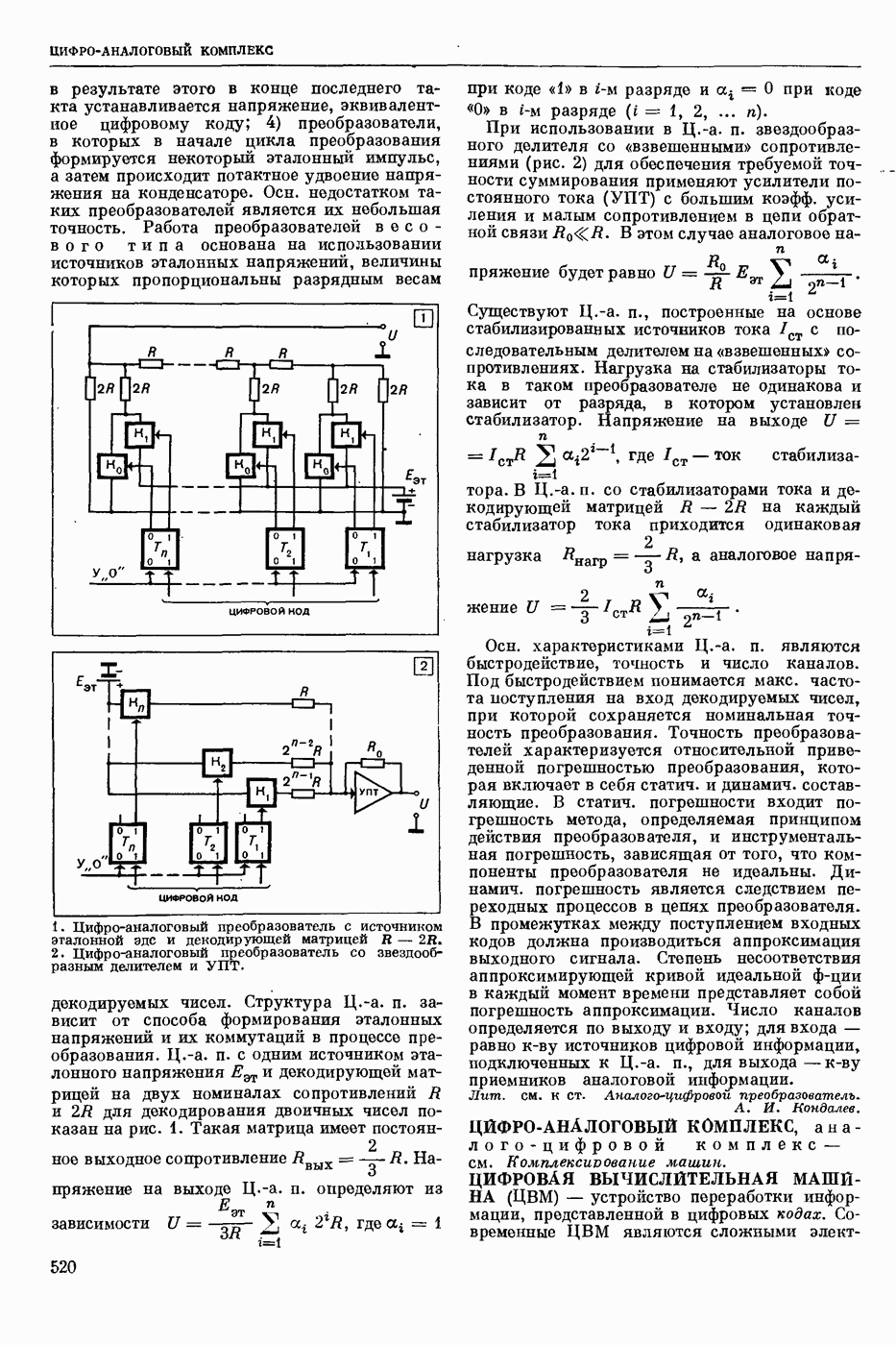
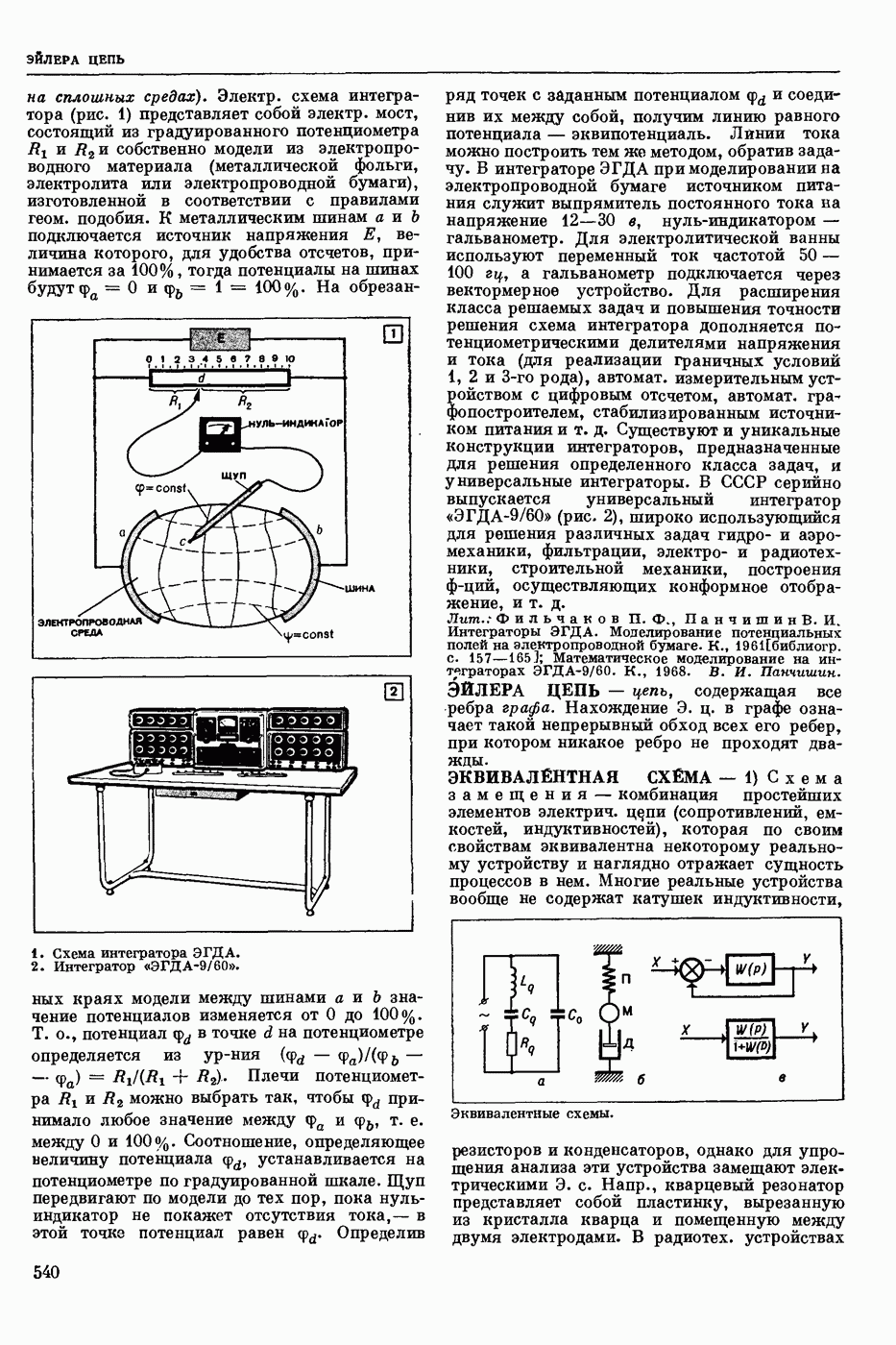
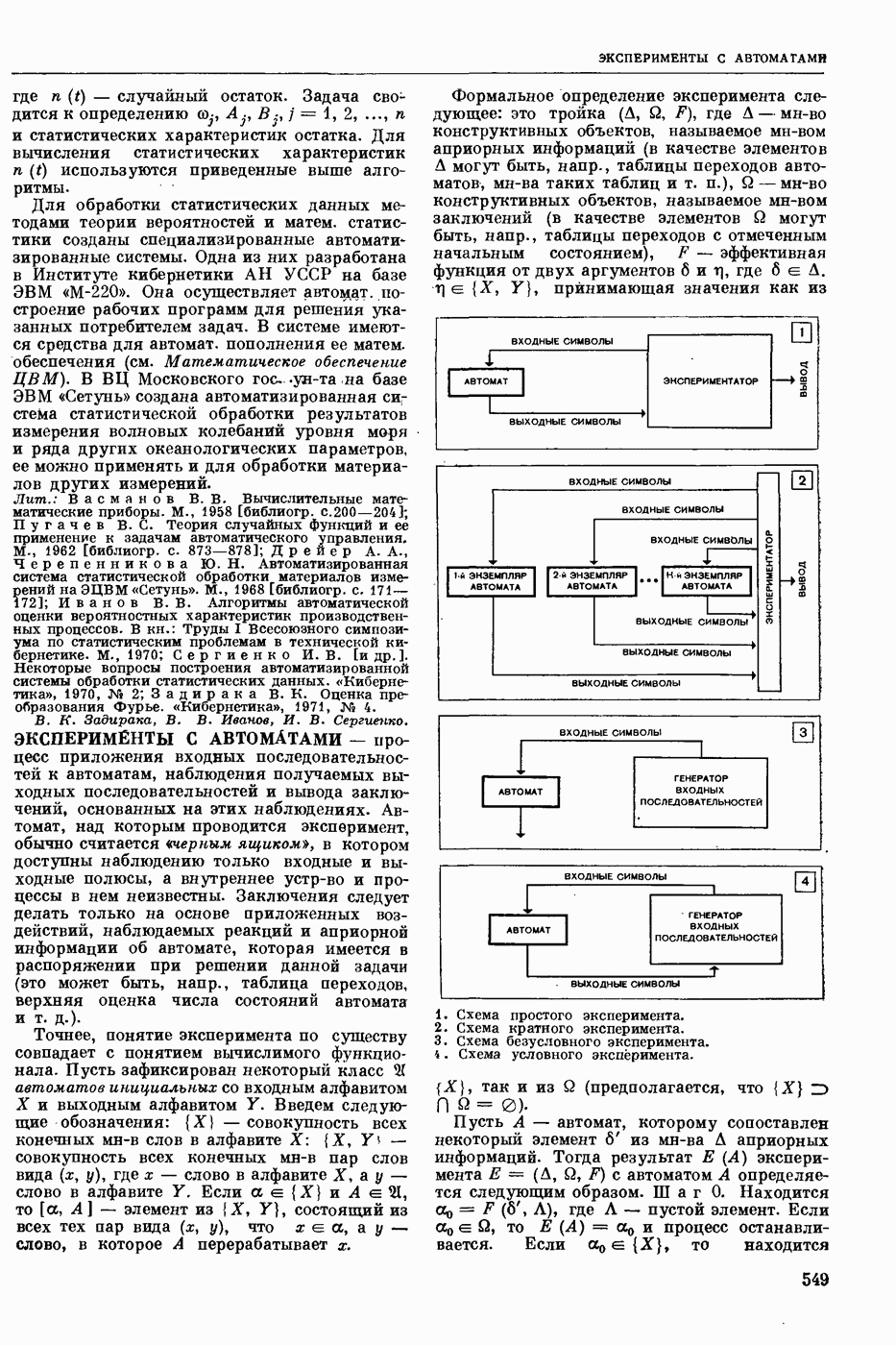
Видеоспектрограмма слова «Усы».
Однако экспериментальные испытания показали их непригодность для этой цели. Тогда попытались переделать некоторые устр-ва под распознавание ограниченного количества слогов и слов (до ста слов в словаре). Однако и эти попытки были неудачными. Главная причина неудач заключалась в несовершенстве применяемых методов распознавания. Новые возможности в Р. р. с. открылись с появлением электронных цифровых вычисл. машин. При их использовании осн. внимание уделяется методам Р. р. с. и их экспериментальной проверке.
Успехи, достигнутые в Р. р. с., весьма скромны. В настоящее время нет серийно выпускаемых устр-в, решающих хотя бы весьма частную задачу Р. р. с. Имеются только действующие алгоритмы и программы, реализованные с помощью вычисл. машин, которые могут распознавать изолированно произнесенные слова из фиксированного набора. Количество распознаваемых слов — несколько сотен для одного диктора и несколько десятков — для многих дикторов. Надежность распознавания составляет 90—96%.
При Р. р. с., как и при распознавании образов вообще, исходят из некоторых признаков, которые в случае Р. р. с. являются результатом анализа сигналов на выходе микрофонного усилителя. Выделяют признаки, более или менее полно описывающие положение артикуляционных органов в процессе произношения речи. Для этих целей используется в основном мгновенный спектр речи, задающий спектральное распределение энергии речевого сигнала во времени.
Мгновенный спектр речи наглядно представляется т. н. картинками видимой речи или видеоспектрограммами. На рис. приведена видеоспектрограмма слова «усы». По оси абсцисс отложено время, по оси ординат — частота. Яркостью (чернотой) моделируется величина спектральной интенсивности, темные участки изображения соответствуют более интенсивным составляющим речевого сигнала. Получают мгновенный спектр с помощью анализаторов речи, содержащих параллельную систему узкополосных фильтров. Видеоспектрограммы отдельной фонемы, слога или слова изменяются от произношения к произношению в зависимости от условий окружающей среды, темпа речи, манеры произношения, индивидуальности диктора и т. п. Видеоспектрограммы фонем связной речи в значительной степени зависят от соседних фонем. Изменяемость видеоспектрограмм от реализации к реализации затрудняет Р. р. с.
При разработке алгоритмов автоматического Р. р. с. преобладают два подхода, условно называемые модельным и логическим. При модельном подходе, исходя из известных свойств речевого сигнала, формулируют матем. модели (в частности, статистические) всех возможных видеоспектрограмм речи для каждого класса. Из этих моделей, пользуясь, напр., байесовским решающим правилом, выводят оптим. алгоритмы распознавания. Одним из возможных способов построения модели является конструктивное задание всех возможных видеоспектрограмм слова речи. Для этого слово речи представляется некоторой упорядоченной совокупностью элементарных эталонных сигналов, являющихся частями фонем. Из них по определенным правилам конструируются все возможные эталоны слова, отличающиеся длительностью и интенсивностью составляющих слово фонем. Распознавание неизвестного слова заключается в синтезе для него эталона наибольшего правдоподобия и в отнесении слова к тому классу, из эталонных элементов которого получается наиболее правдоподобный эталон. Задача синтеза решается методами программирования динамического.
Совершенно аналогично формулируется и решается задача распознавания слитной (связной, без пауз между словами) речи, составляемой из слов заданного словаря. В этом случае решение задачи Р. р. с. заключается в нахождении наиболее правдоподобной устной фразы.
составляемой из конструируемых эталонов слов, и в указании последовательности слов, из эталонов которых такая фраза составлена. Модели речевых сигналов могут быть сформулированы с точностью до неизвестных параметров. Тогда возникает необходимость в обучаемых алгоритмах Р. р. с. Для таких алгоритмов в процессе обучения оцениваются неизвестные параметры, напр., эталоны слова. Благодаря обучению алгоритмы Р. р. с. легко перенастраиваются на распознавание других классов речевых сигналов, напр., других слов.
При логическом подходе из видеоспектрограммы речи стремятся выделить некоторые устойчивые вторичные признаки, принимающие одинаковое значение на всех реализациях одного класса или группы классов. Такие признаки, как правило, формулируются для жестко фиксированного (раз навсегда выбранного) набора классов. Напр., для различения слова «мама» и «Саша» достаточно воспользоваться двоичным признаком — есть шумный звук или нет его. По этому признаку слова речи могут быть разбиты на две группы. Примеры других признаков: наличие одного гласного звука в слове, наличие двух гласных в слове, знак разности энергий сигнала в нижней и верхней частях спектра, наличие глухой смычки в слове и т. п. Распознавание неизвестного слова заключается в проверке определенных логических условий в пространстве вторичных признаков и в отнесении слова к тому классу, для которого эти условия выполняются.
Осн. усилие исследователей по Р. р. с. направлено на распознавание слов речи из некоторого словаря. Предпочтение отдается т. н. двуступенчатым системам распознавания, в которых сначала выделяются более мелкие части речевого сигнала, чем слово, напр., слоги, фонемы или элементы фонем, а затем производится распознавание этих частей и принятие решения о слове в целом. Членение на части делается не жестким, а управляемым в зависимости от принимаемых решений на второй ступени, в частности, делается целенаправленный перебор всех возможных вариантов членения. Двуступенчатую систему можно рассматривать как реализацию одного из простейших вариантов пофонемного принципа распознавания слов речи. Один из возможных подходов к решению задачи Р. р. с. в широком смысле состоит в увеличении количества слов, распознаваемых двуступенчатой системой, и оптимизации последней, что, возможно, в итоге приведет к реализации фонемного или близкого к нему принципа распознавания речи на первой ступени.
На формулировку алгоритмов Р. р. с. большое влияние оказывают исследования по речеобразованию и восприятию речи человеком. Эти исследования позволяют изучить свойства речевого сигнала и принципы его переработки человеком.
Лит.: Сапожков М. А. Речевой сигнал в кибернетике и связи. М., 1963 [библиогр. с. 419—450]; Волошин Г. Я. Об использовании языковой избыточности для повышении надежности автоматического распознавания речевых сигналов. В кн.: Вычислительные системы, в. 28. Новосибирск, 1967; Винцюк Т. К. Распознавание слов устной речи методами динамичебкого программирования. «Кибернетика», 1968, № 1; Труды IV Всесоюзной школы-семинара. Автоматическое распознавание слуховых образов. К.» 1969; Величко В. М., Загоруйко Н. Г. Автоматическое распознавание ограниченного набора устных команд. В кн.: Вычислительные системы, в. 36. Новосибирск, 1969; Чистович Л. А., Кожевников В. А. Восприятие речи. В кн.: Вопросы теории и методов исследования восприятия речевых сигналов, в. 22. Л., 1969; Винцюк Т. К. Поэлементное распознавание непрерывной речи, составленной из слов заданного словаря. «Кибернетика», 1971, № 2.
Т. К. Винцюк.