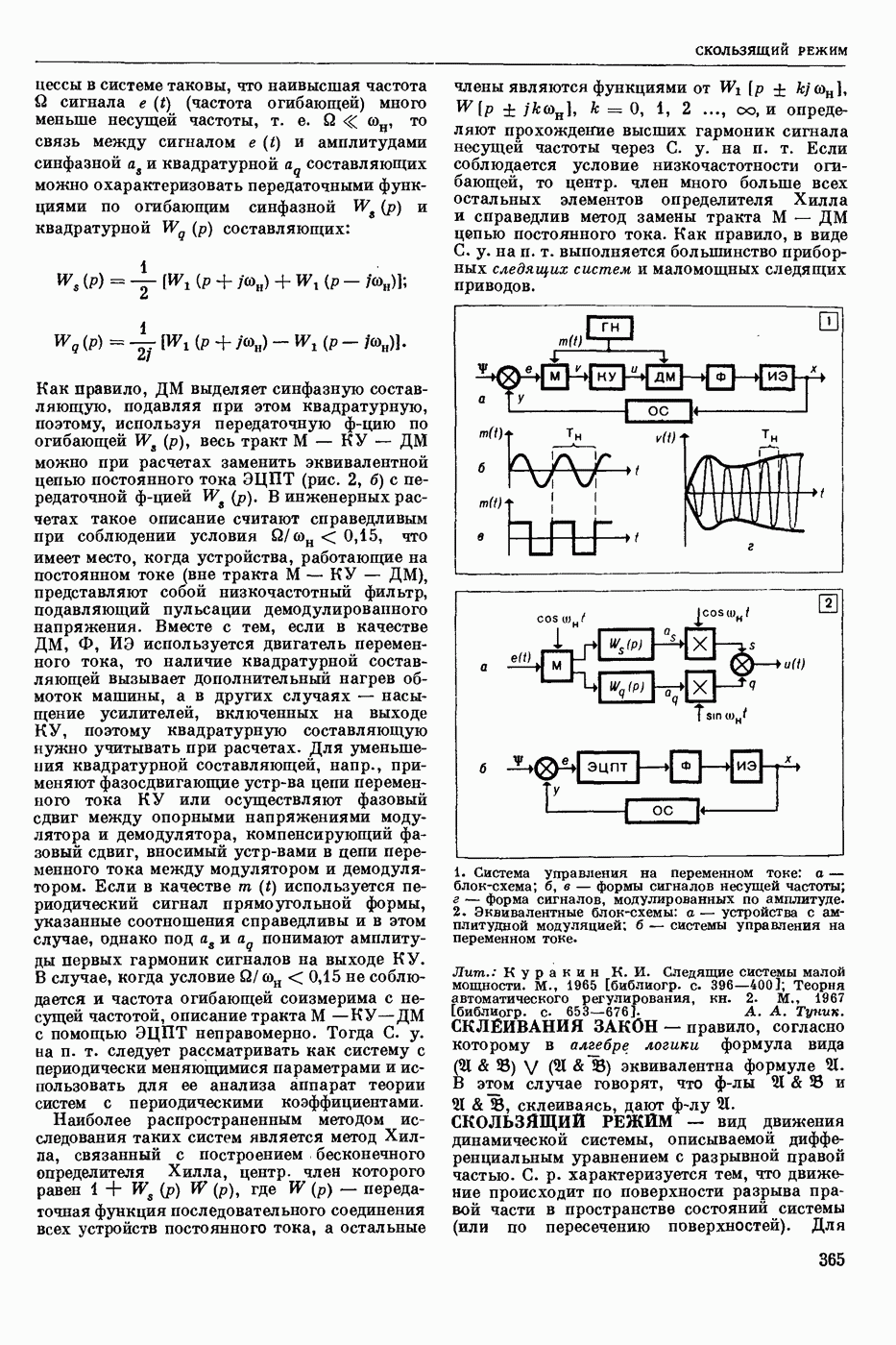
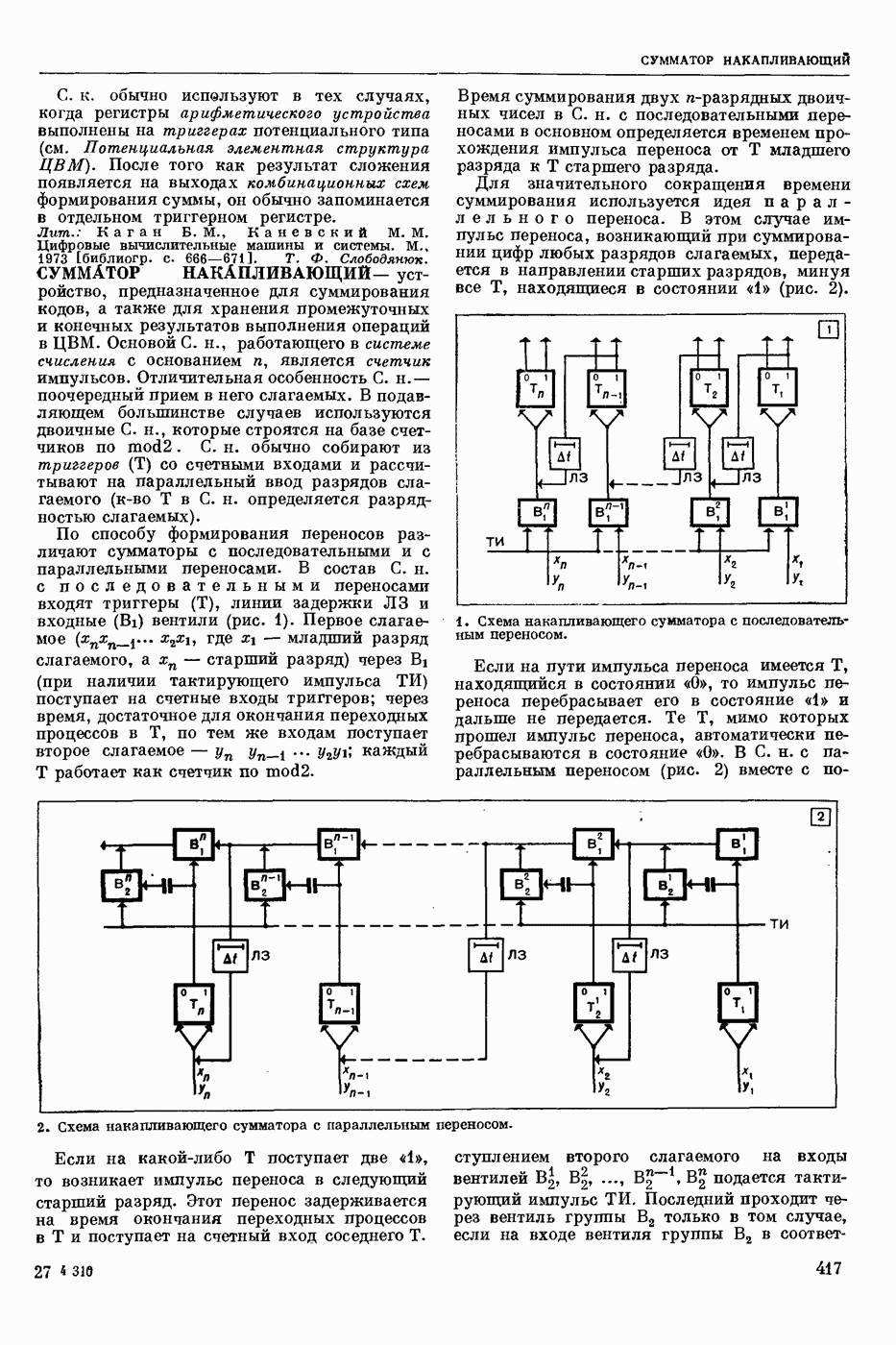
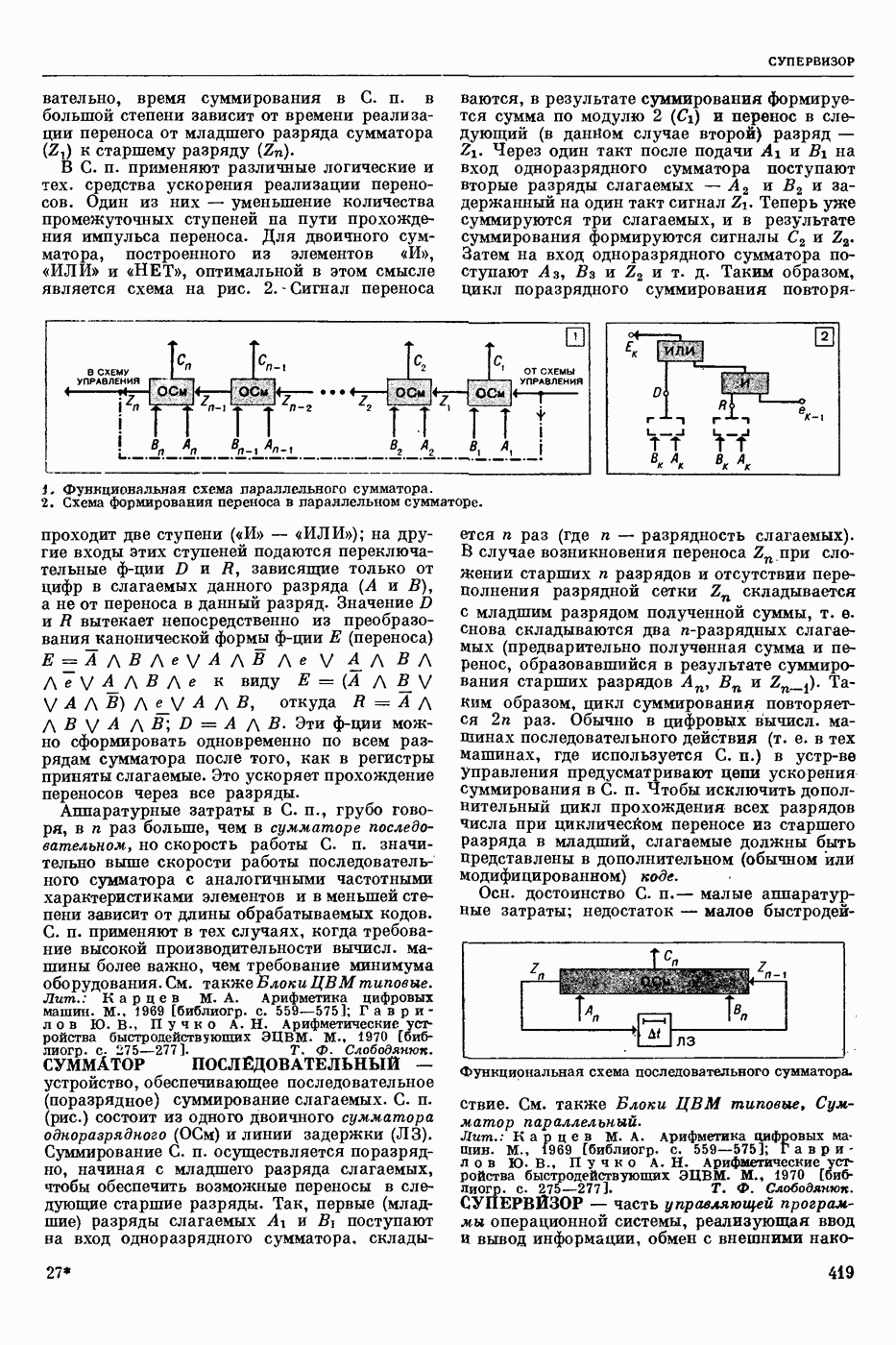
частности,  синтаксической структуры. Выполняется алгоритмом, использующим определенную совокупность сведений о синтаксисе данного языка. С. а. а. - важный этап различных процессов автоматической обработки текстов: перевода с одного естественного языка на другой, перевода с естественного языка на язык информационный (в информационно-справочных системах) и др.
синтаксической структуры. Выполняется алгоритмом, использующим определенную совокупность сведений о синтаксисе данного языка. С. а. а. - важный этап различных процессов автоматической обработки текстов: перевода с одного естественного языка на другой, перевода с естественного языка на язык информационный (в информационно-справочных системах) и др.

До середины 60-х годов С. а. а., как правило, являлся осн. этапом процесса автоматического перевода (см. Машинный перевод), причем он завершал анализ. Полученное при С. а. а. синтаксическое представление служило входом либо для этапа преобразования, либо, чаще, — сразу для этапа синтеза. Использование результата С. а. а. как входа для синтеза приводило к тому, что к С. а. а. предъявлялись неоправданно высокие требования, т. к. синтаксическое представление должно было одновременно годиться как для переводимого, так и для переводящего текста, т. е. учитывать особенности и входного, и выходного языков; кроме того, в нем требовалось отразить многие чисто семантические факторы. С выделением в процессе перевода отдельного этапа семантического анализа требования к С. а. а. изменились: во-первых, синтаксическое представление теперь не ориентировано на выходной язык, во-вторых, в нем не делается попыток учесть семантику.
В системах автоматического перевода С. а. а. начинается тогда, когда текст уже некоторым образом обработан, т. е. входом для С. а. а. является не последовательность слов, а последовательность условных единиц, каждая из которых содержит сведения о том, из какой лексической единицы (т. е. из какого слова или словосочетания) она получена, а также все те сведения об этой лексической единице, которые извлечены из словаря или получены на предшествующих этапах обработки (одной лексической единице может соответствовать несколько таких условных единиц — лексикограмматическая омонимия). В современных системах перевода объектом С. а. а. является цепочка условных единиц, соответствующая одной фразе обрабатываемого текста. Выходом С. а. а. является совокупность сведений, задающая синтаксическое представление анализируемой фразы, т. е. данные о синтаксической структуре фразы, о связях между местоимениями и их антецедентами, о логическом акценте и т. п. Однако до последнего времени целью С. а. а. считалось только установление синтаксической структуры фразы, а остальные сведения не вырабатывались.
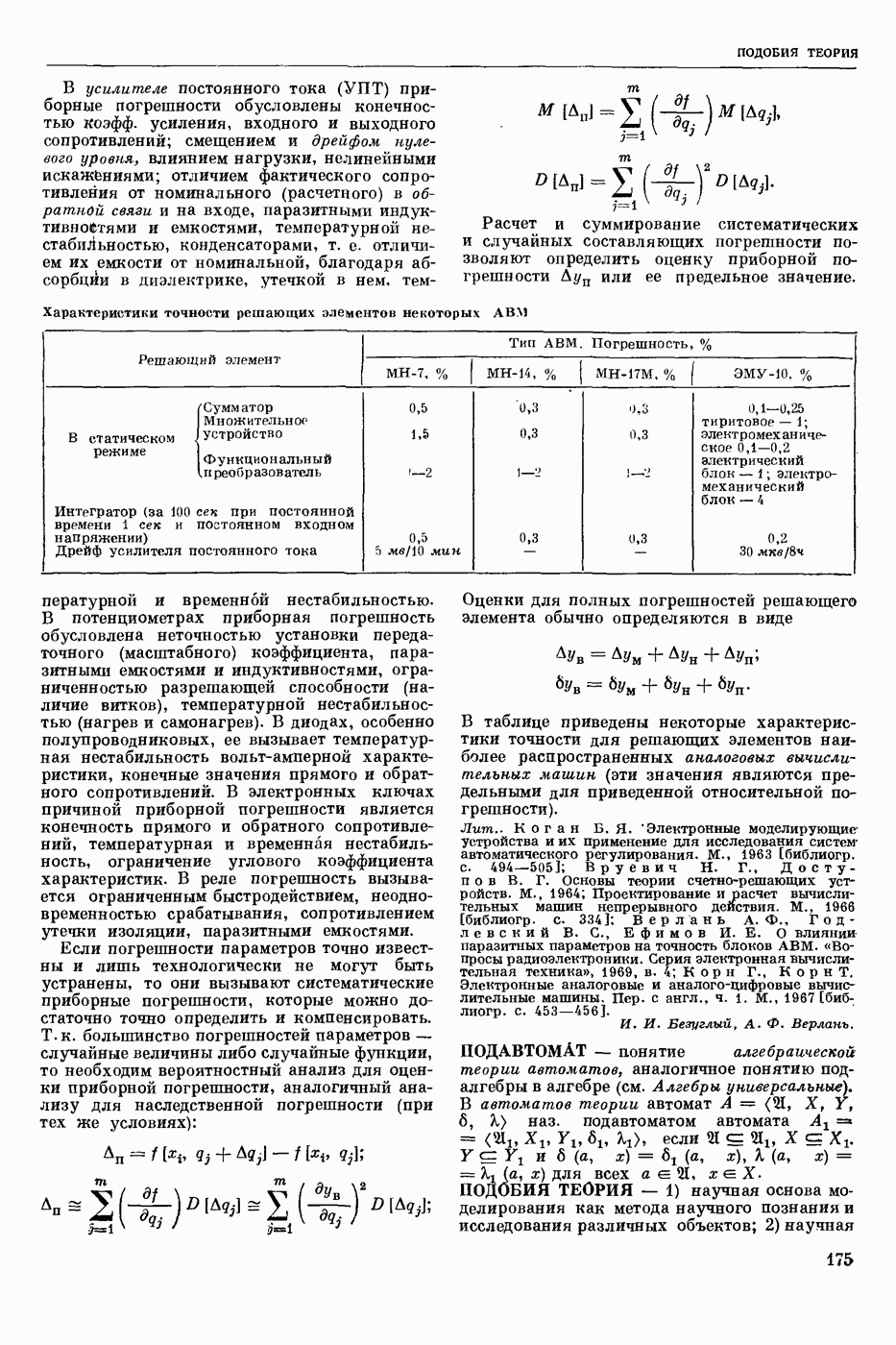
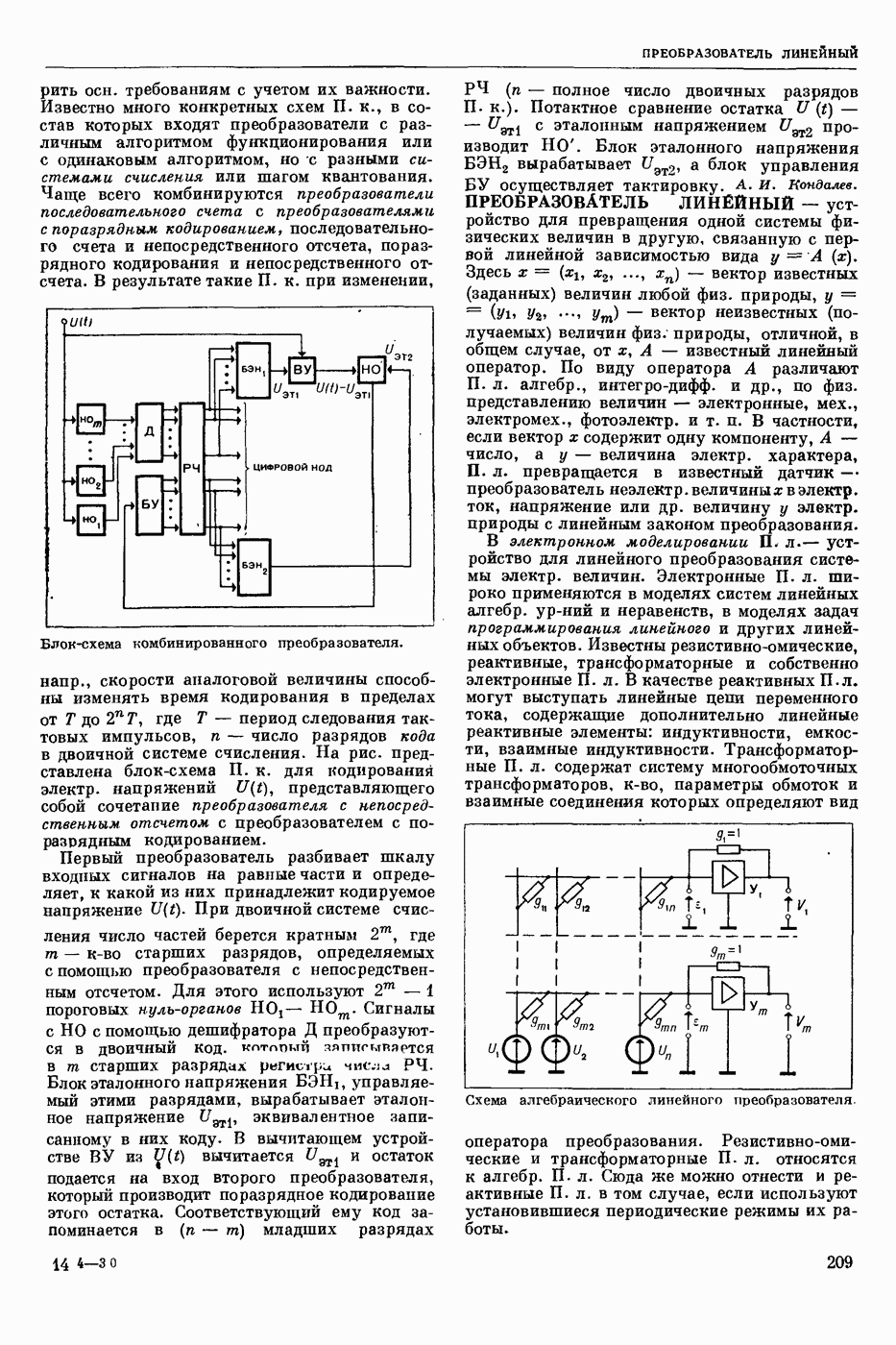
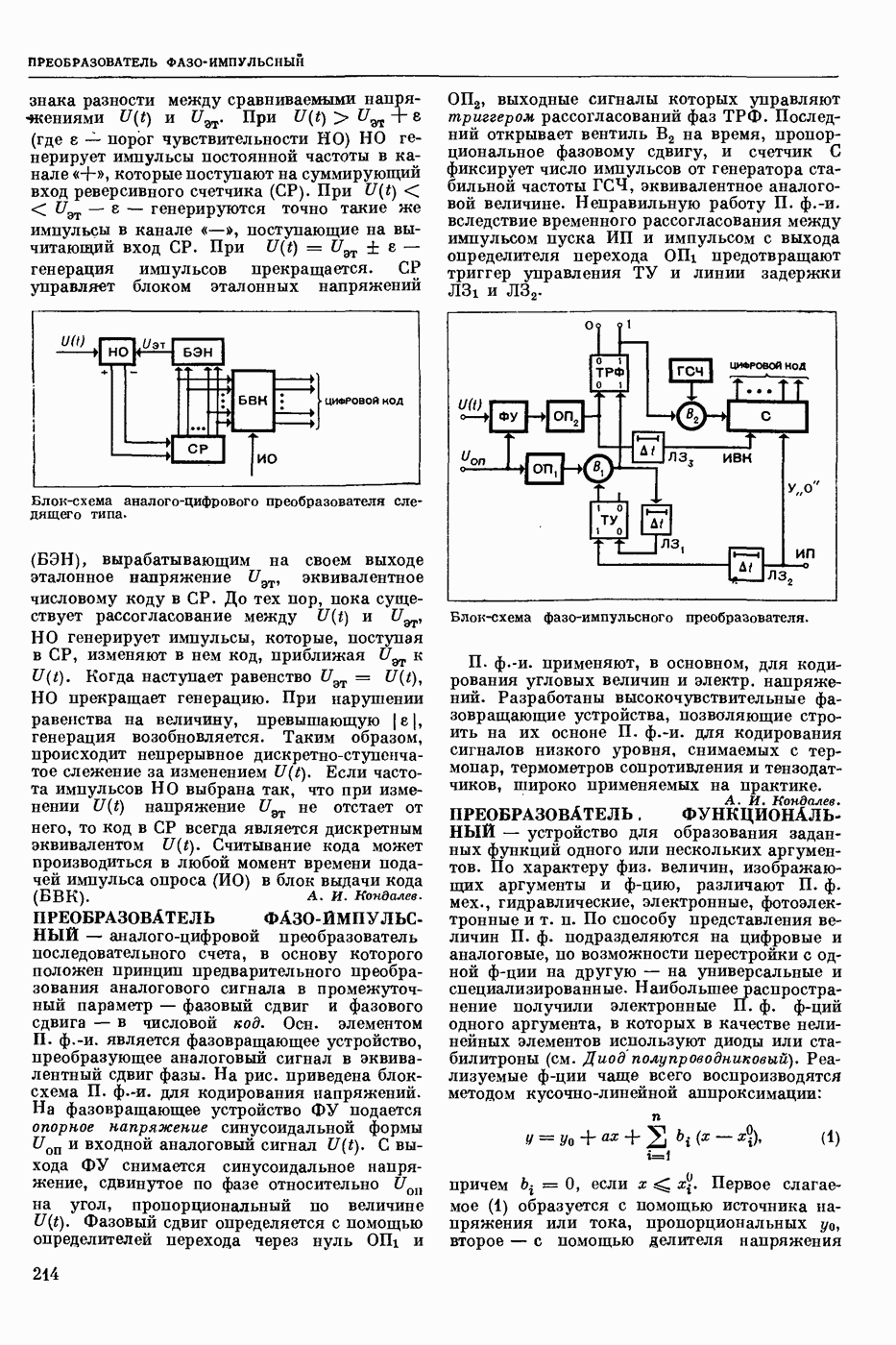
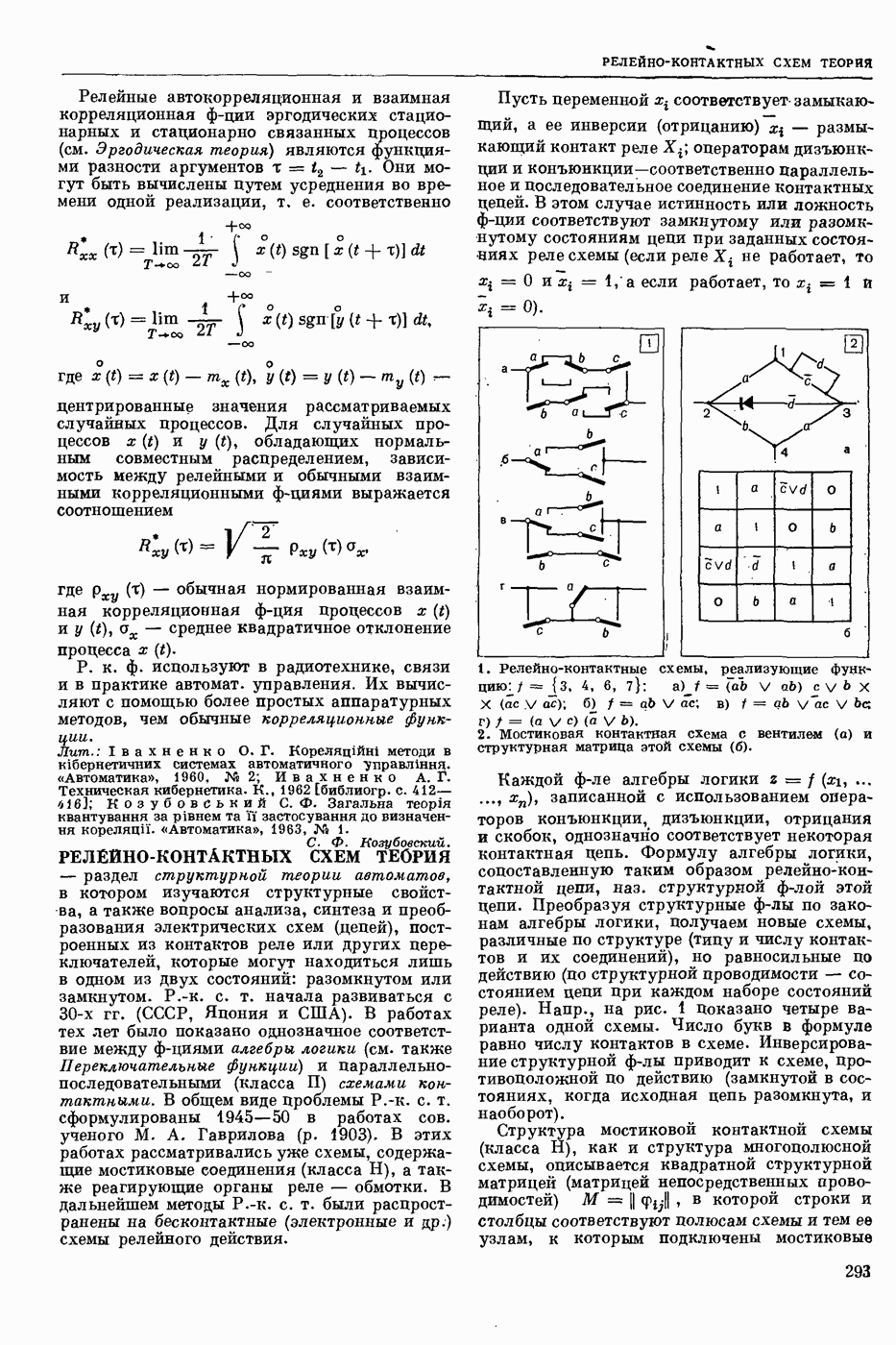
Среди способов записи синтаксической структуры наиболее распространенными являются «дерево» составляющих и едерево» зависимостей. При первом способе анализируемая цепочка членится на составляющие, которые, в свою очередь, членятся на более мелкие составляющие, и т. д., пока не будут получены одноэлементные составляющие. При втором способе для каждого элемента анализируемой цепочки, кроме одного — вершины, указывается элемент, им управляющий, и тип связи между ними (эти связи обычно указываются при помощи стрелок, идущих от управляющих элементов к управляемым), напр.: «Синтаксическое представление фразы включает в себя данные о синтаксических связях между словами». «Дерево» составляющих этой фразы (без указания типов составляющих) приведено на рис. 1, а «дерево» зависимостей (без указания типов связей) — на рис. 2.
С точки зрения цели С. а. а. можно выделить два осн. подхода: одноцелевой и многоцелевой. При первом из них для фразы требуется получить одно синтаксическое представление; этот подход характерен для первых алгоритмов С. а. а., когда считалось, что синтаксических средств достаточно для того, чтобы обеспечить правильный анализ фразы, хотя бы для большинства фраз. При втором подходе для фразы требуется получить все те синтаксические представления, которые удовлетворяют определенным соглашениям (все «правильно построенные» представления). Вопрос о том, какое из этих представлений является не только правильно построенным, но и правильным, т. е. соответствующим смыслу анализируемой фразы, в рамках С. а. а. не решается.
Осн. трудности при отыскании правильного синтаксического представления фраз связаны с тем, что в естественных языках широко распространена синтаксическая омонимия, т. е. возможность разной синтаксической интерпретации одинаковых цепочек словоформ. Часто
выбор правильной синтаксической структуры из числа возможных зависит либо от очень тонких синтаксических факторов (не учтенных при составлении алгоритма), либо вообще не может быть выполнен без обращения к смыслу фразы. Поэтому от алгоритмов С. а. а., которые в принципе не используют смысла и основываются на ограниченной информации о синтаксисе языка, можно требовать лишь того, чтобы для большинства фраз они давали правильный вариант анализа плюс малое число лишних фраз.
Среди методов обнаружения синтаксической структуры можно выделить: метод последовательного анализа (локальный) и метод фильтров (глобальный).
При последовательном анализе единицы анализируемой цепочки рассматривают в определенном порядке, причем для каждой единицы алгоритм предписывает определенную совокупность действий, необходимых для того, чтобы определить синтаксическую ф-цию этой единицы (напр., найти ее управляющее слово и тип связи). Эти действия обычно основаны на проверке признаков самой анализируемой единицы и ее окружения (локальность); при этом существенно используются сведения, установленные относительно рассмотренных ранее единиц.
При методе фильтров основой алгоритма С. а. а. является набор требований к правильно построенному синтаксическому представлению; эти требования и есть фильтры, позволяющие отбросить неправильно построенные представления. Некоторые из этих фильтров могут касаться структуры в целом, а также соотношений целой структуры с целой фразой (отсюда и название — глобальный); широко используются и локальные фильтры. Примером часто используемого фильтра является требование проективности. В настоящее время фильтровые алгоритмы широко распространены.
Отделение данных о языке от собственно алгоритма и введение формализмов (в частности, грамматик формальных) для записи этих данных, которые приняты в системах перевода 2-го поколения, в фильтровых алгоритмах выразились в следующем: все лингвистические сведения сосредоточиваются в фильтрах; процедура отыскивания структур, которые потом испытываются фильтрами на правильность, становится независимой от синтаксических свойств языка — она определяется типом выбранной формальной грамматики. Появились многочисленные работы, в которых предлагаются процедуры С. а. а., рассчитанные на различные типы формальных грамматик, а также работы по оценке числа операций таких процедур и т. д. Этот круг работ относится, в сущности, к теории формальных грамматик.
К области собственно С. а. а. принадлежит использование подобных процедур для тех или иных естественных языков. При этом пока остается открытым вопрос о нахождении для естественных языков таких эффективных процедур С. а. а., которые одновременно удовлетворяли бы требованию простоты процедуры и позволяли бы избежать громоздких переборов структур.
Лит.:  .
.