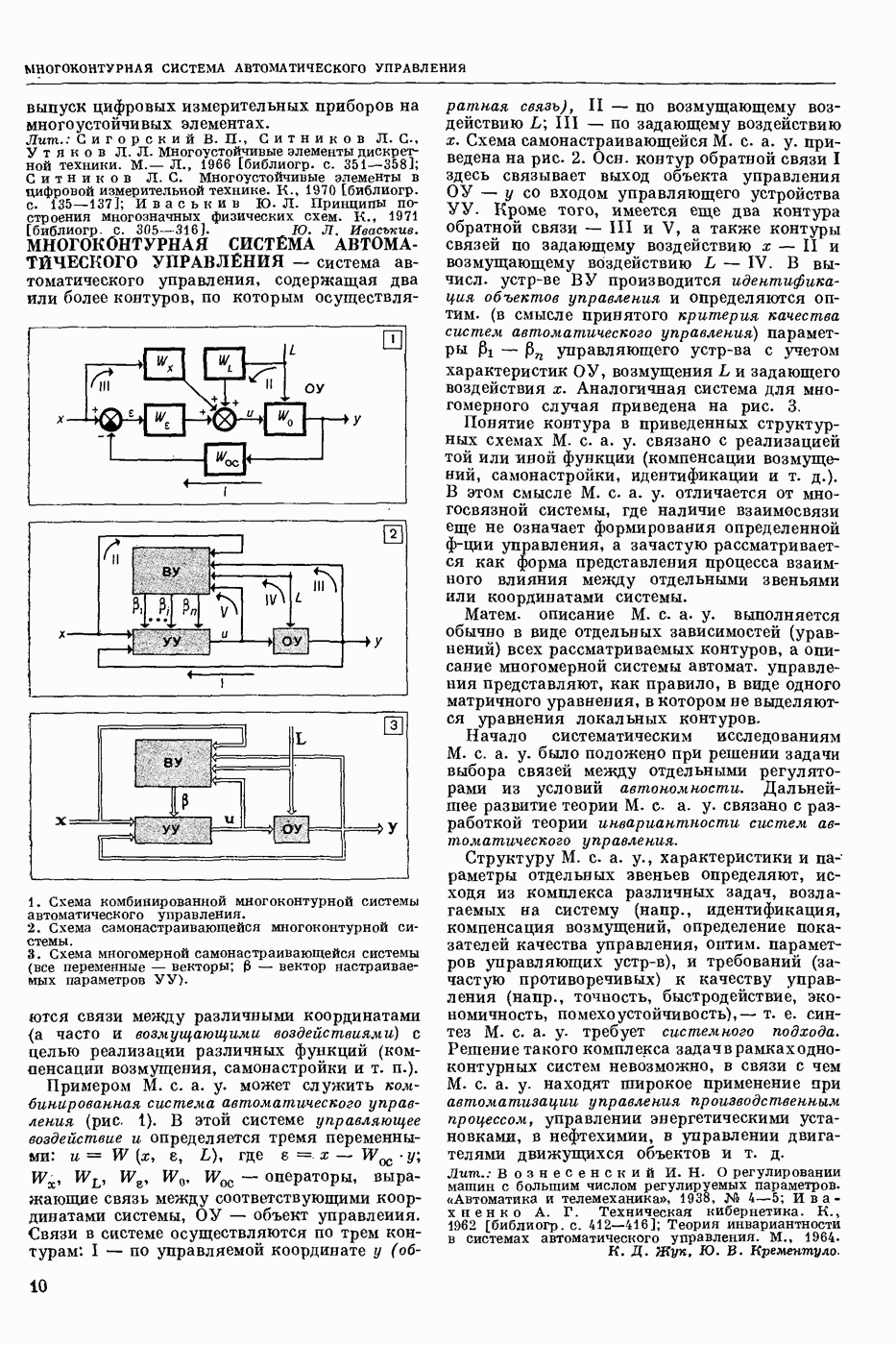
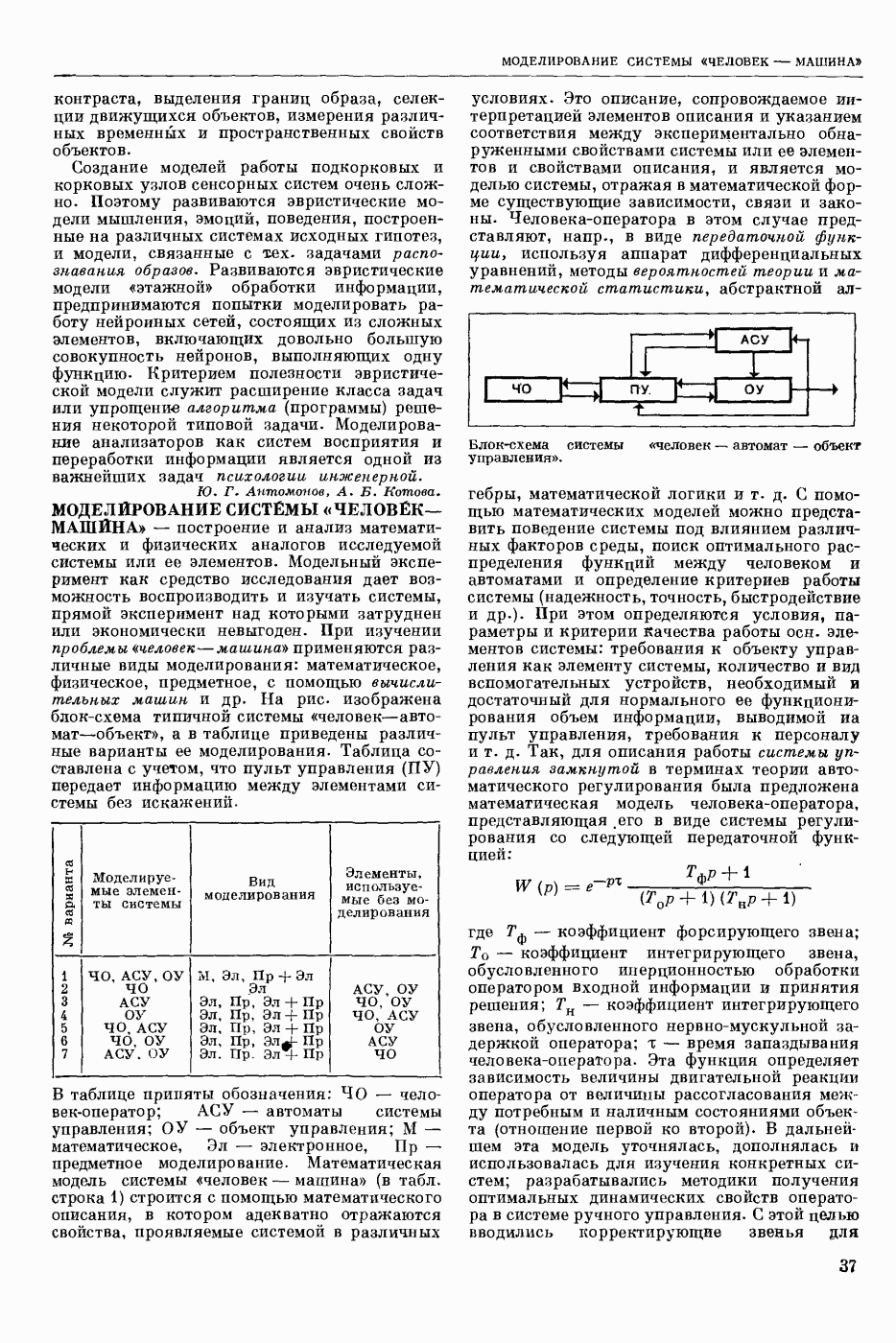
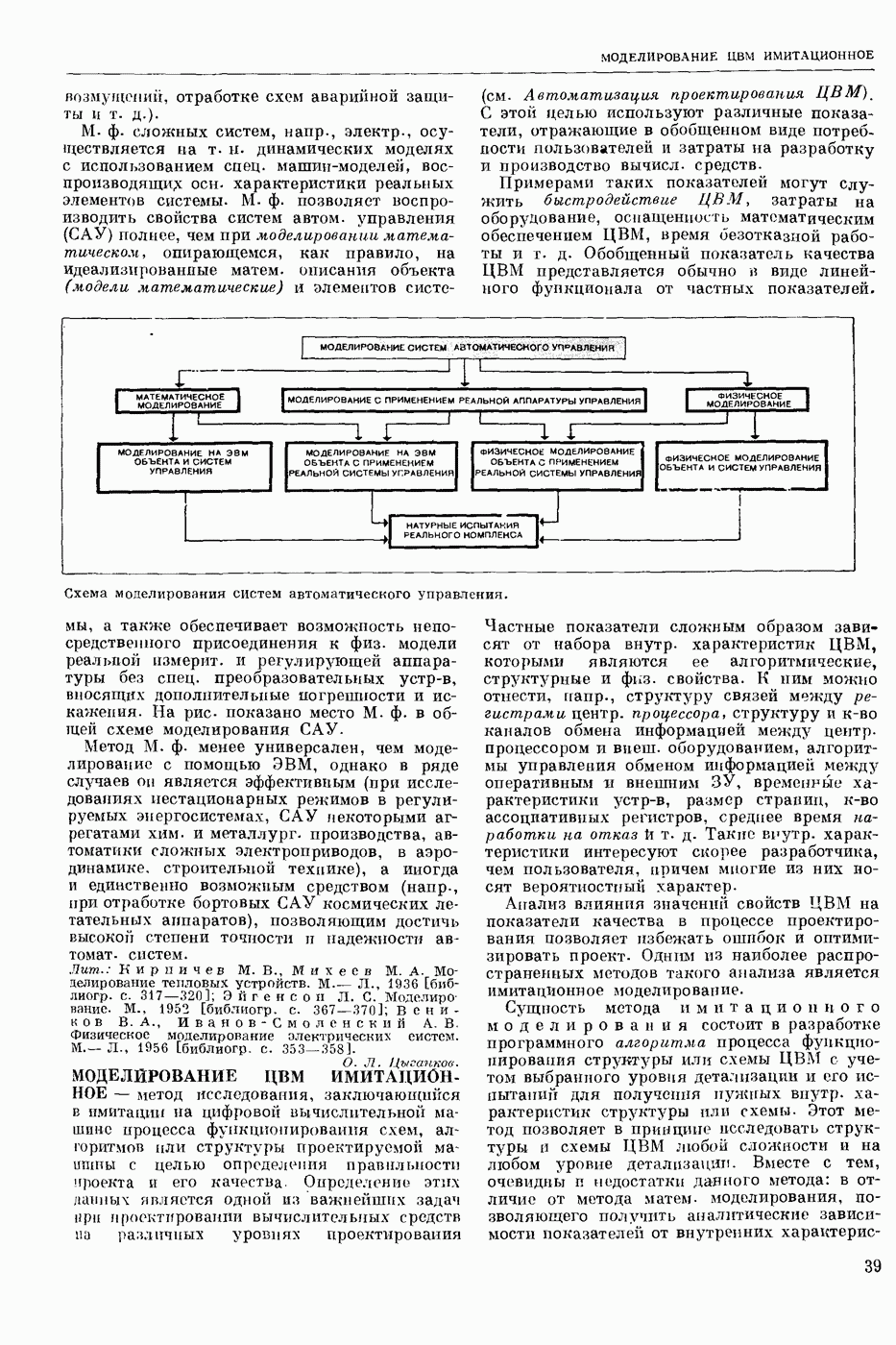
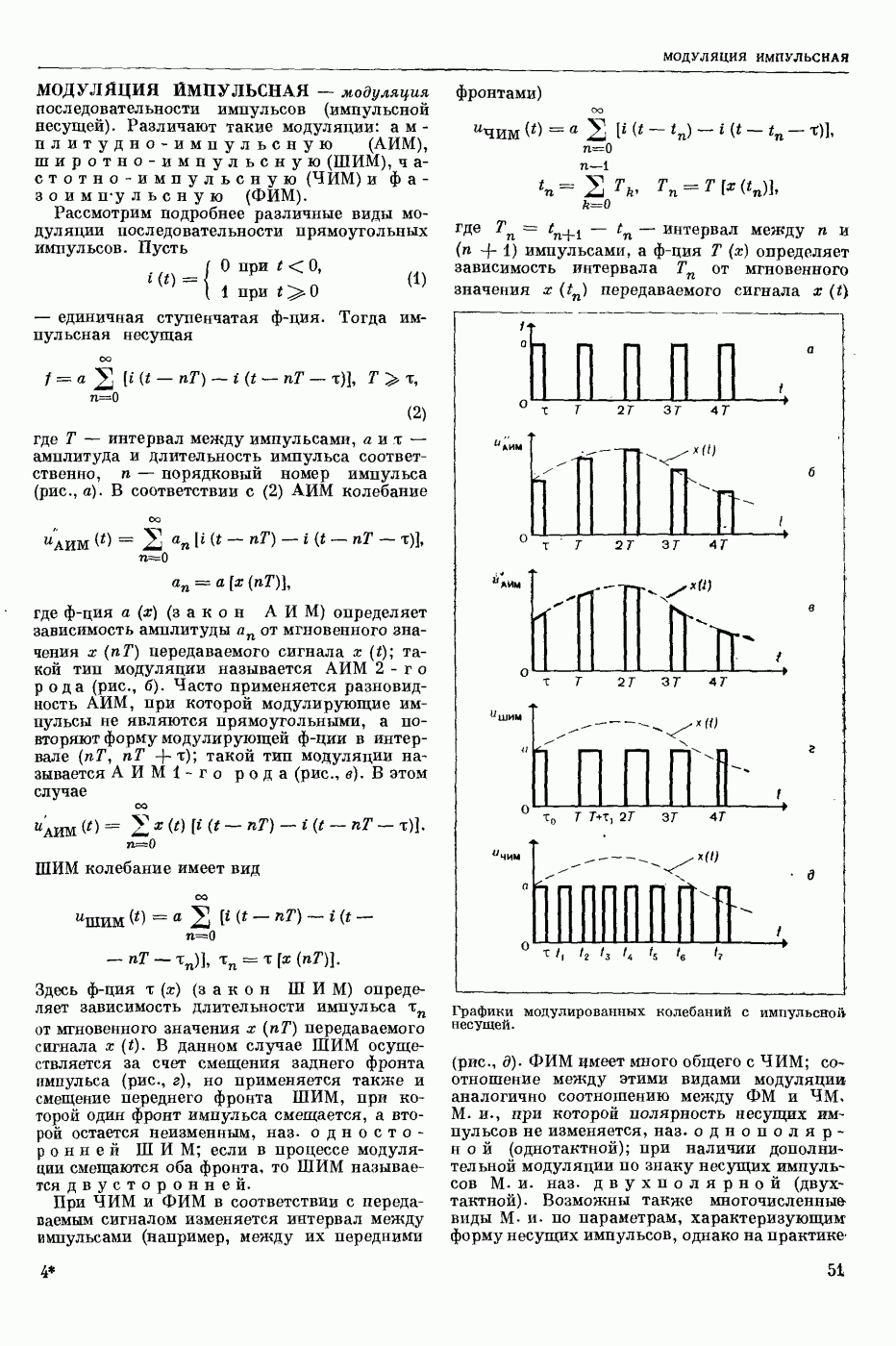
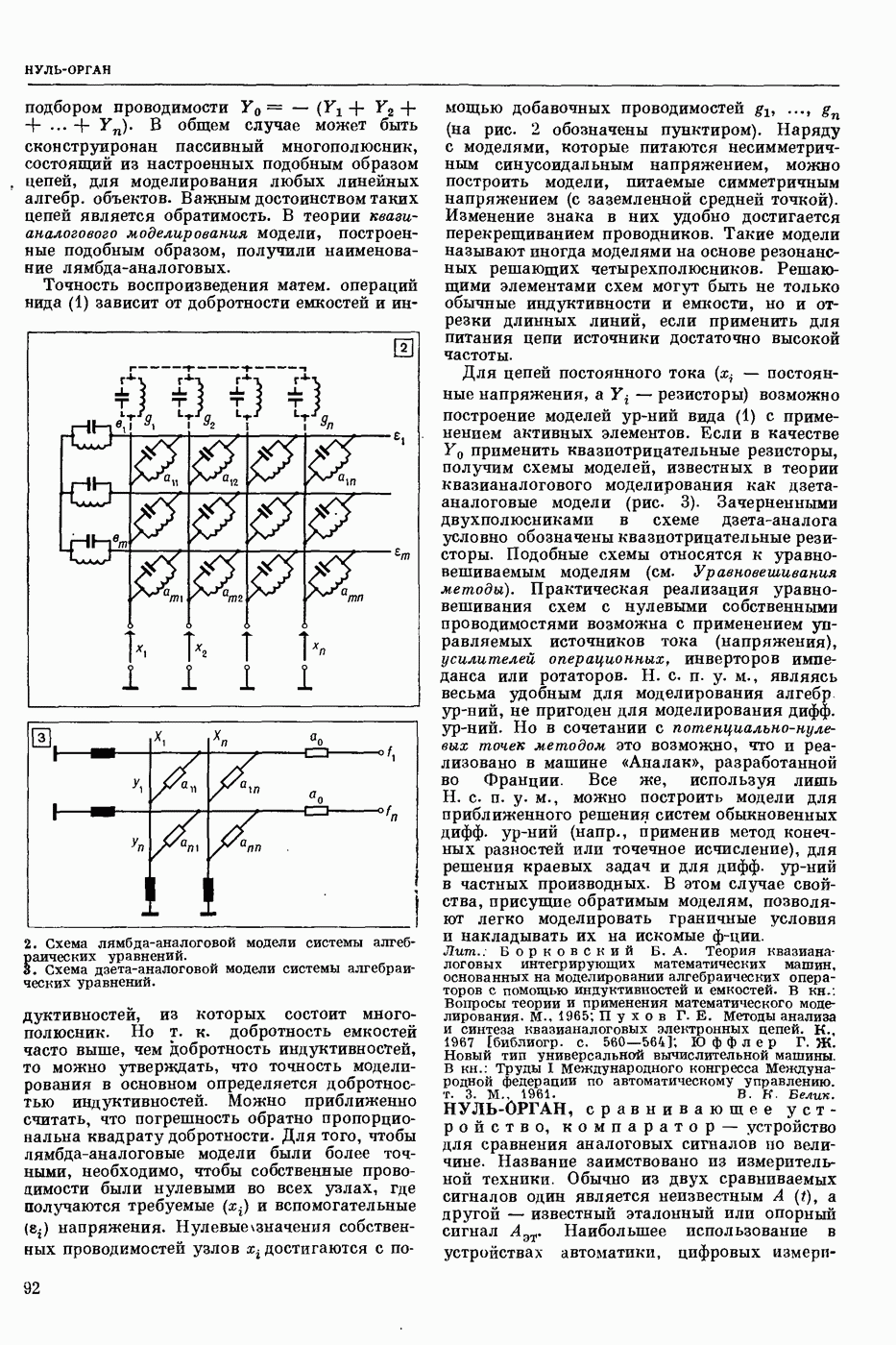
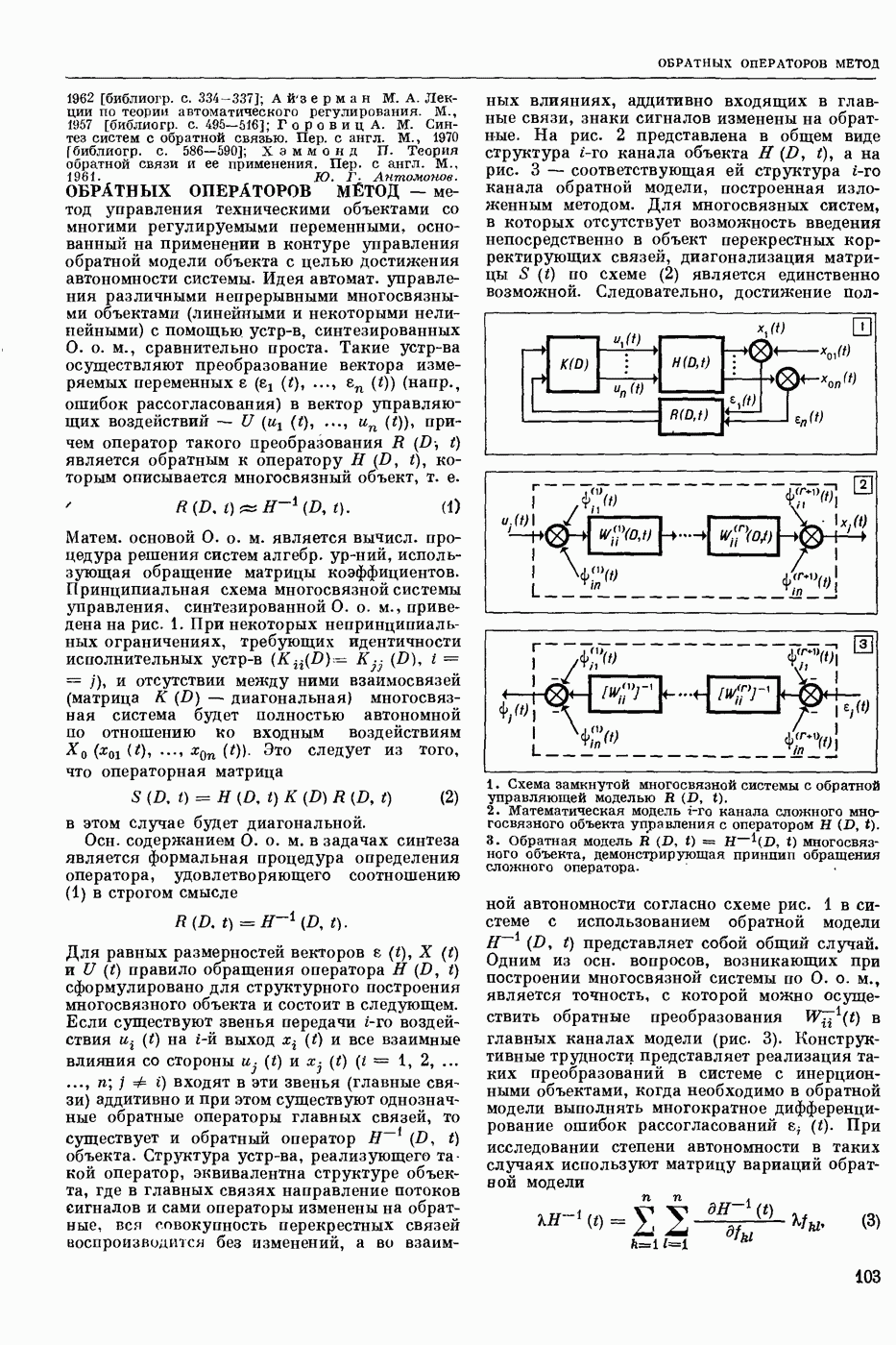
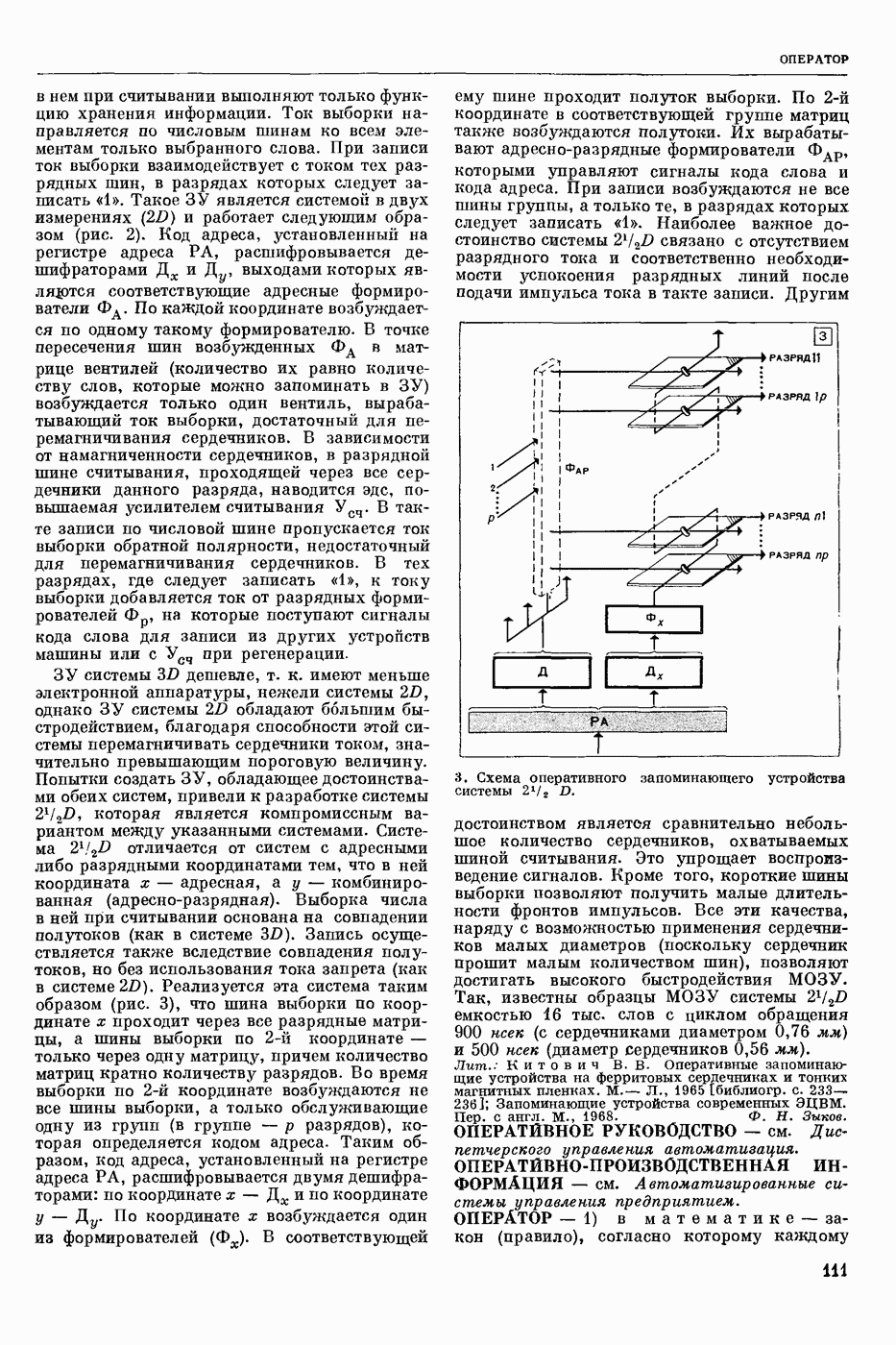
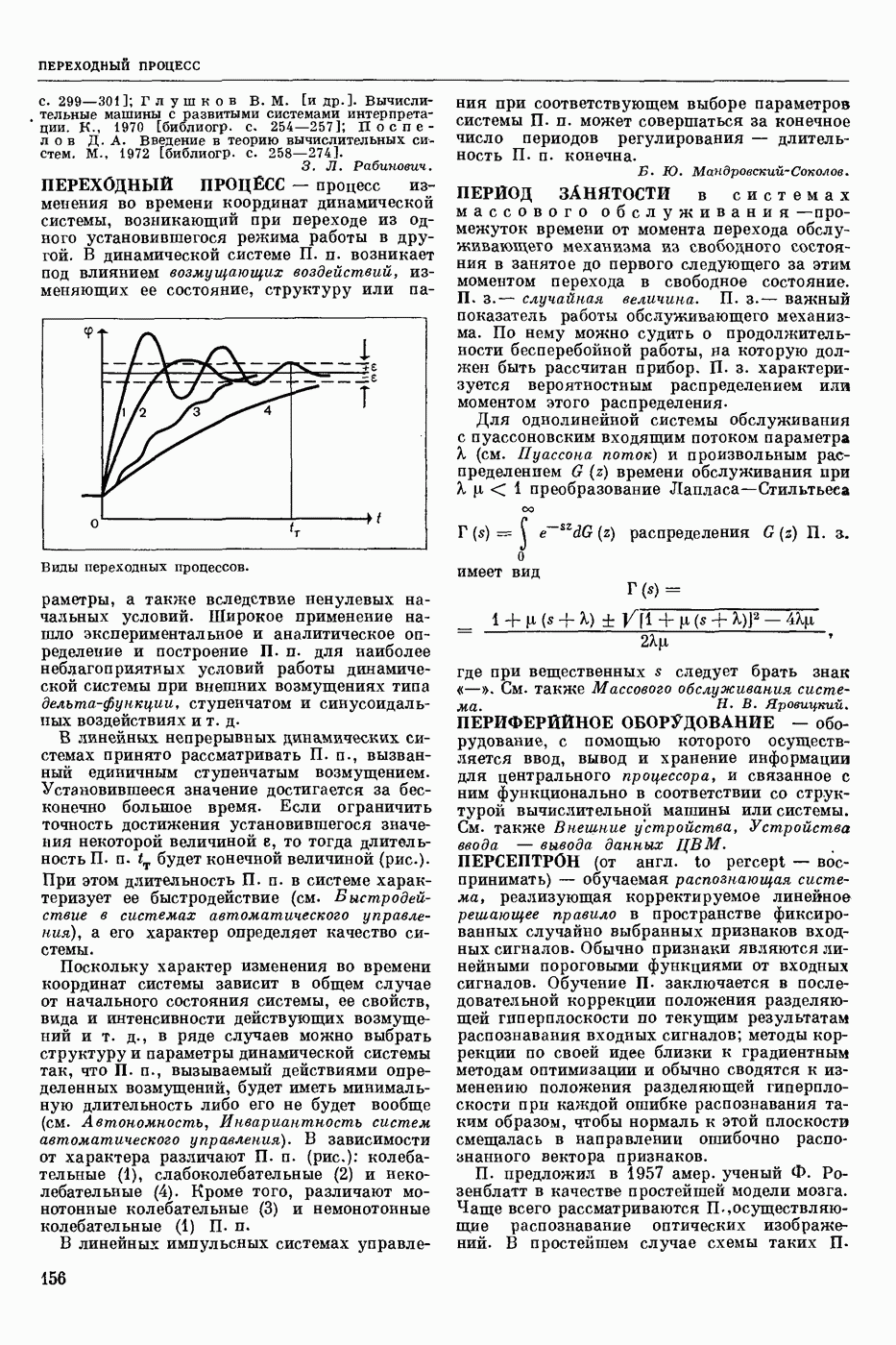
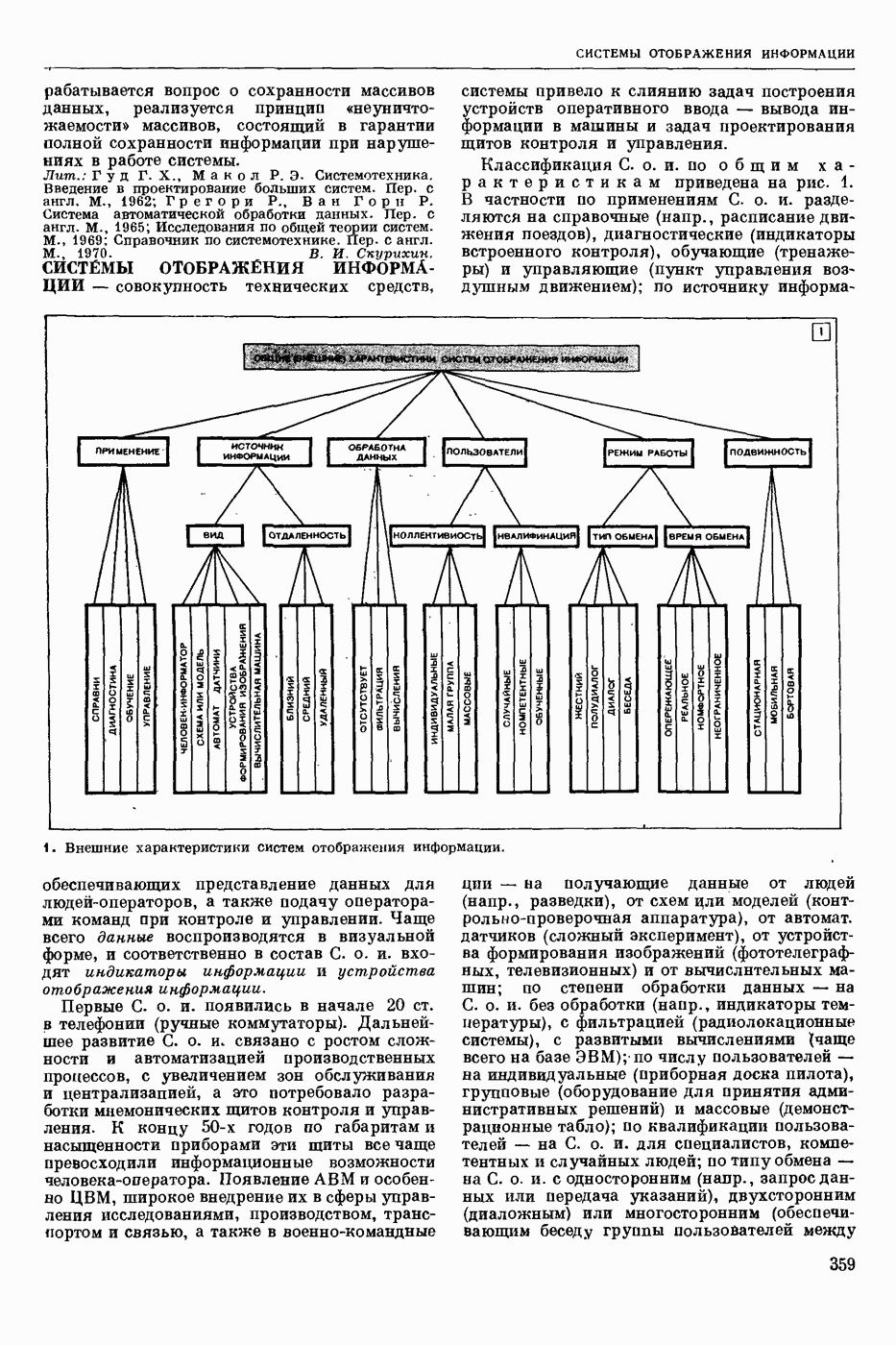
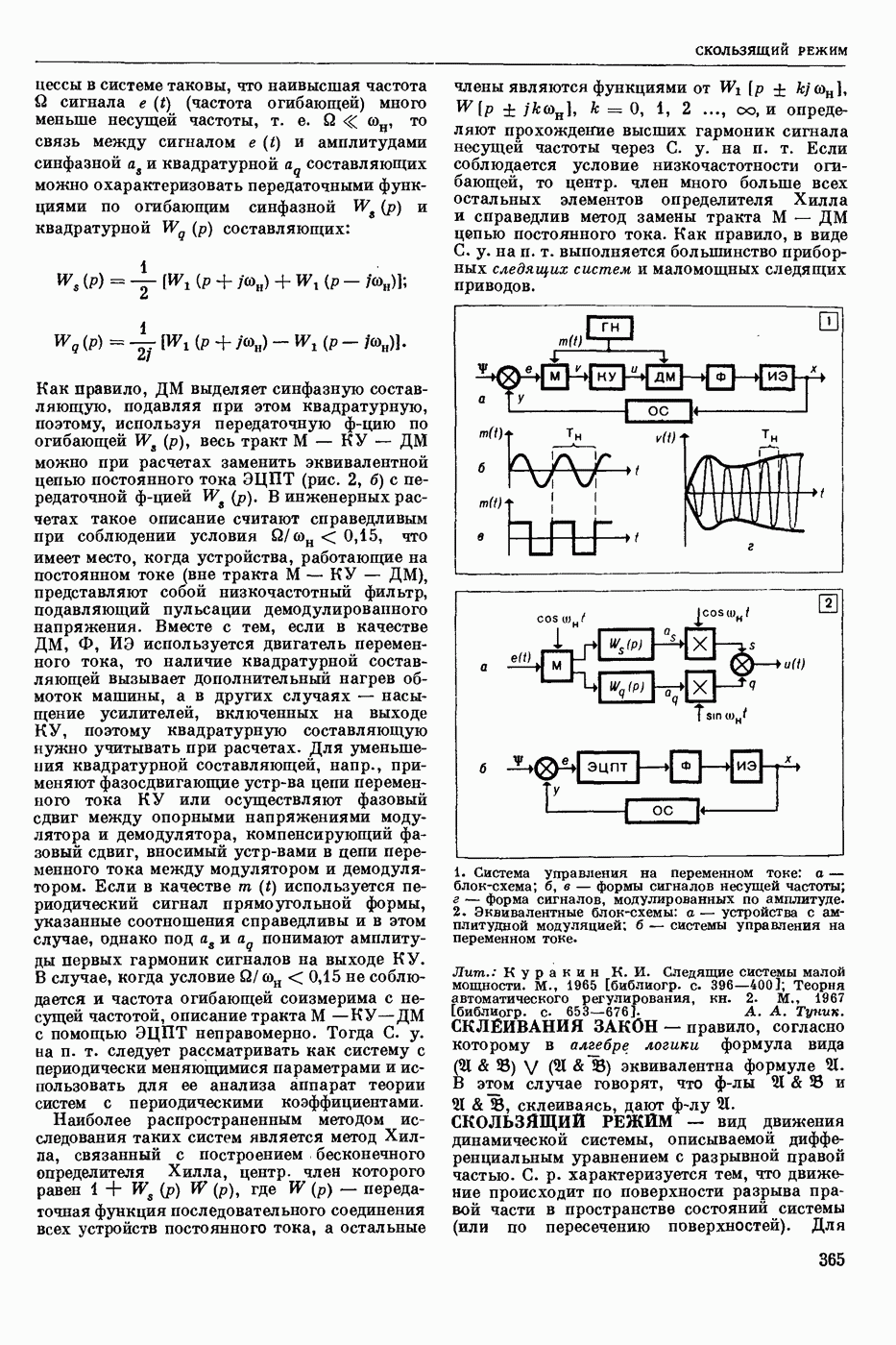
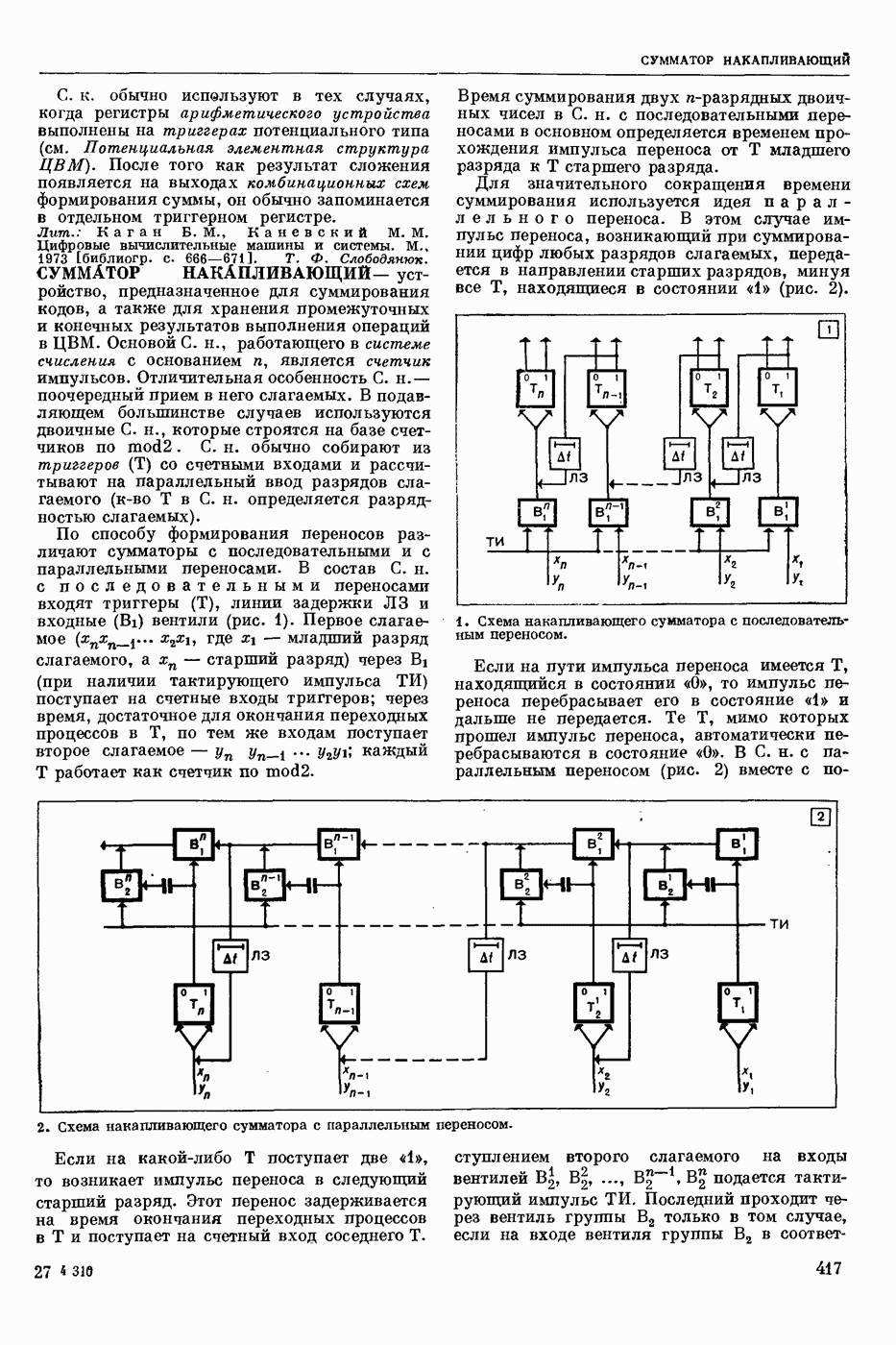
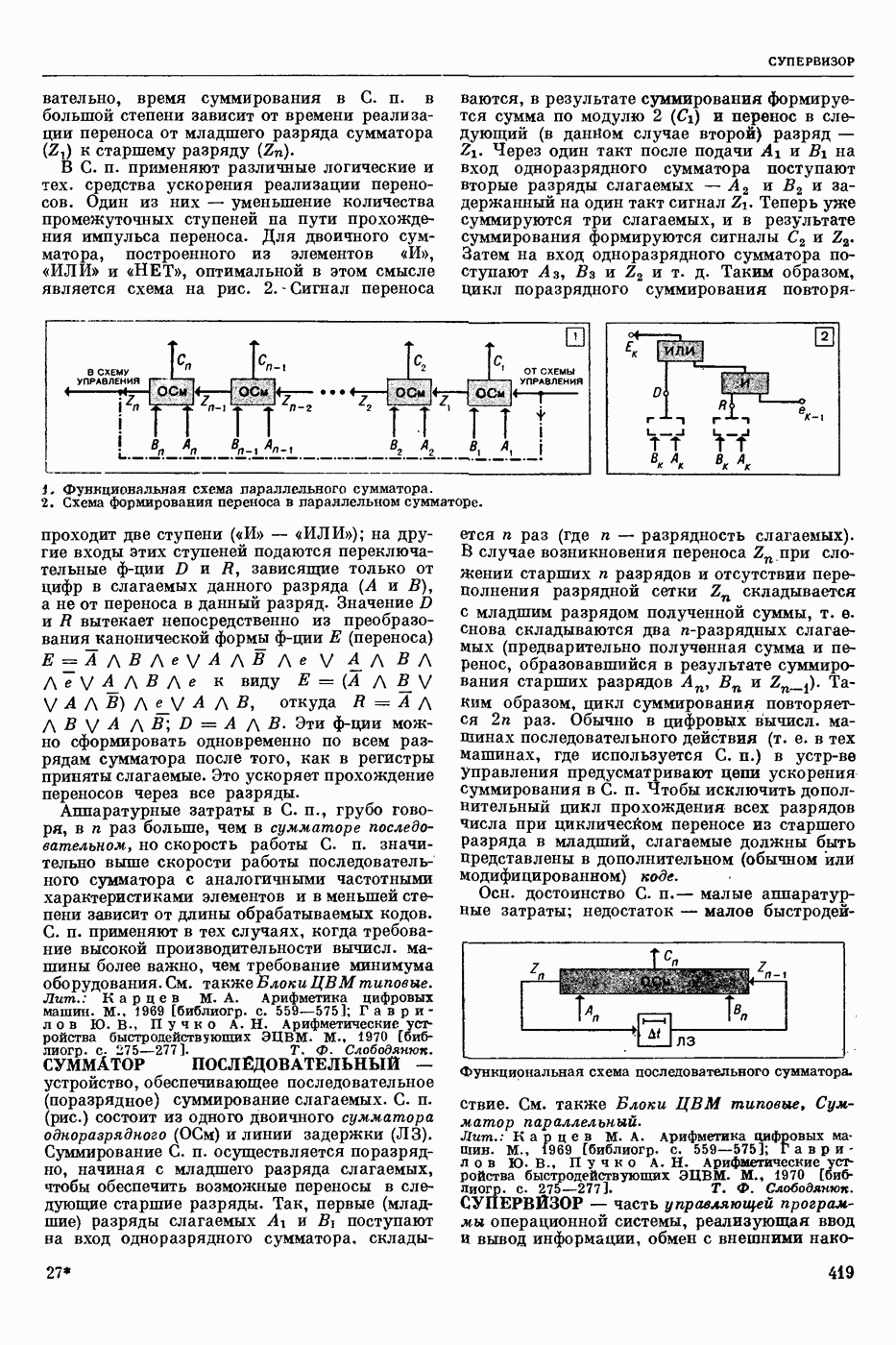
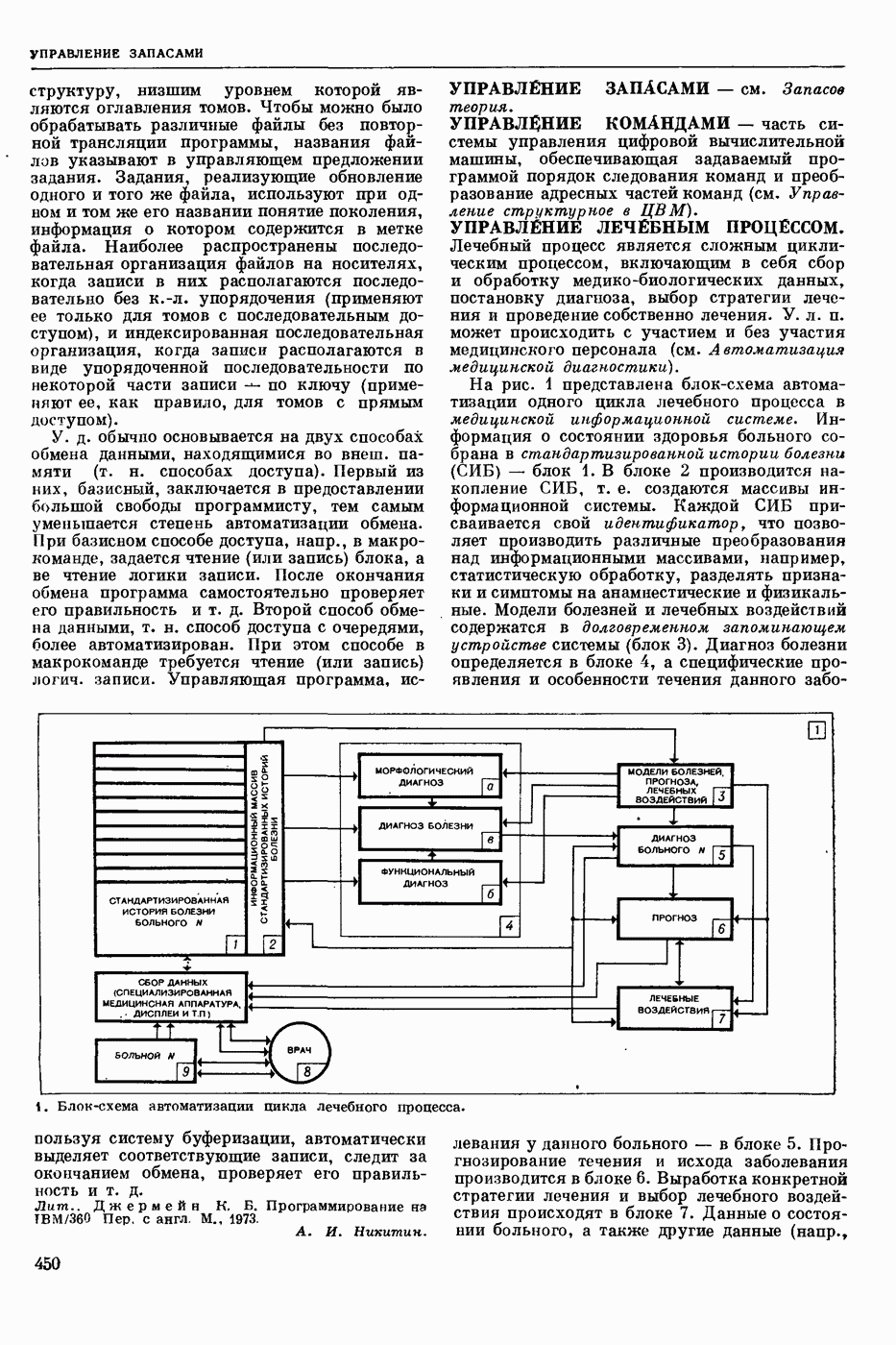
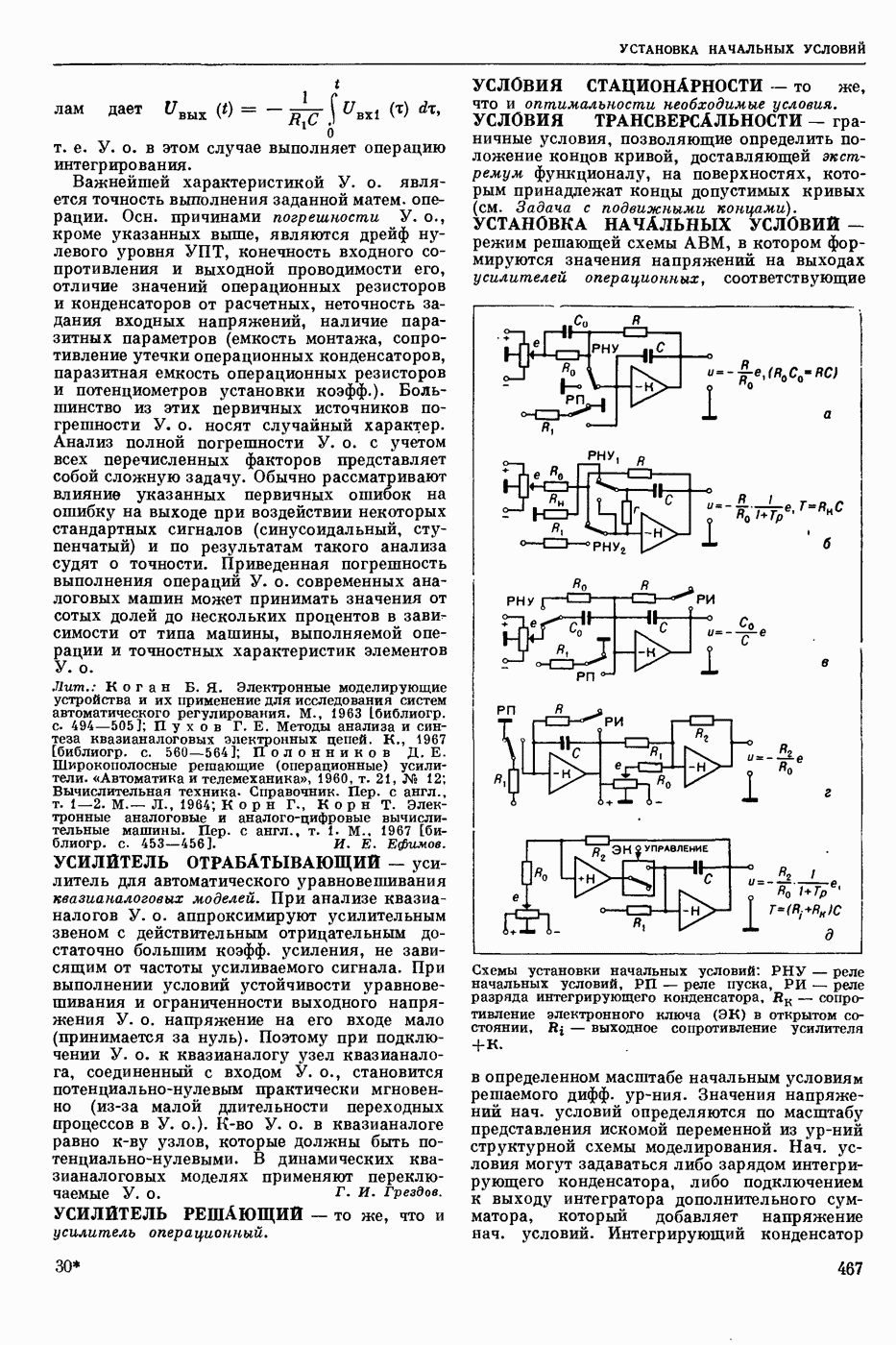
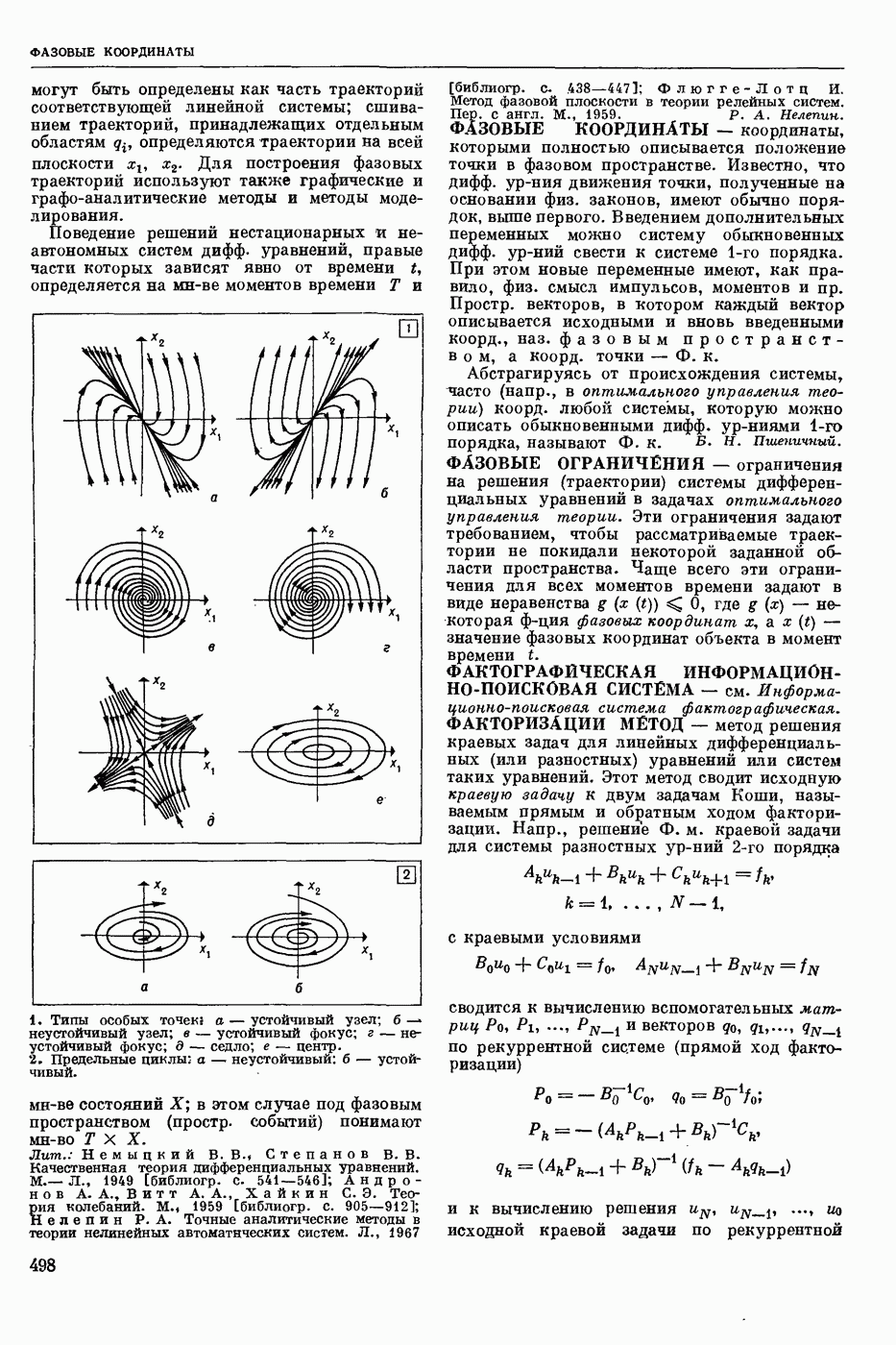
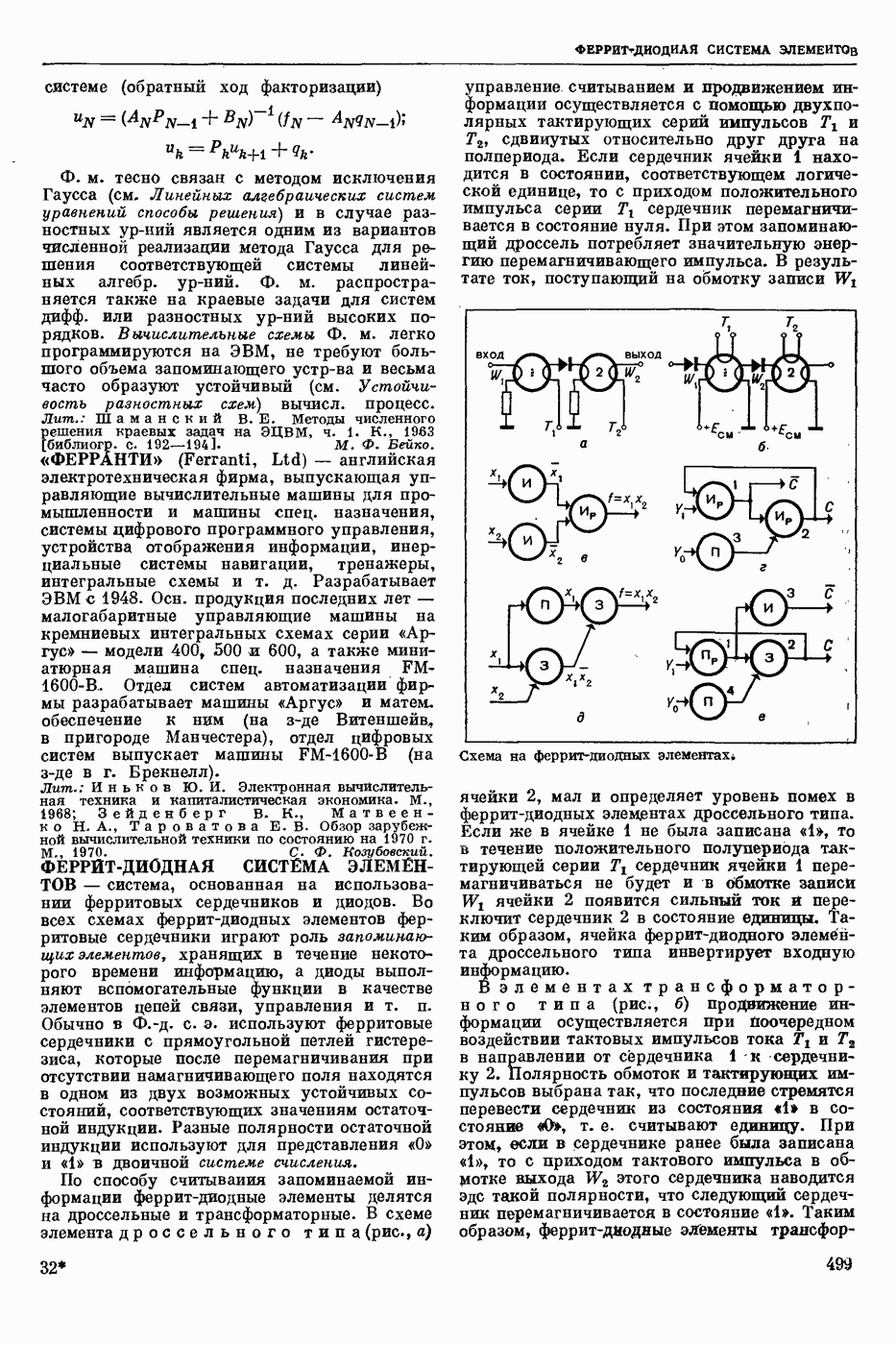
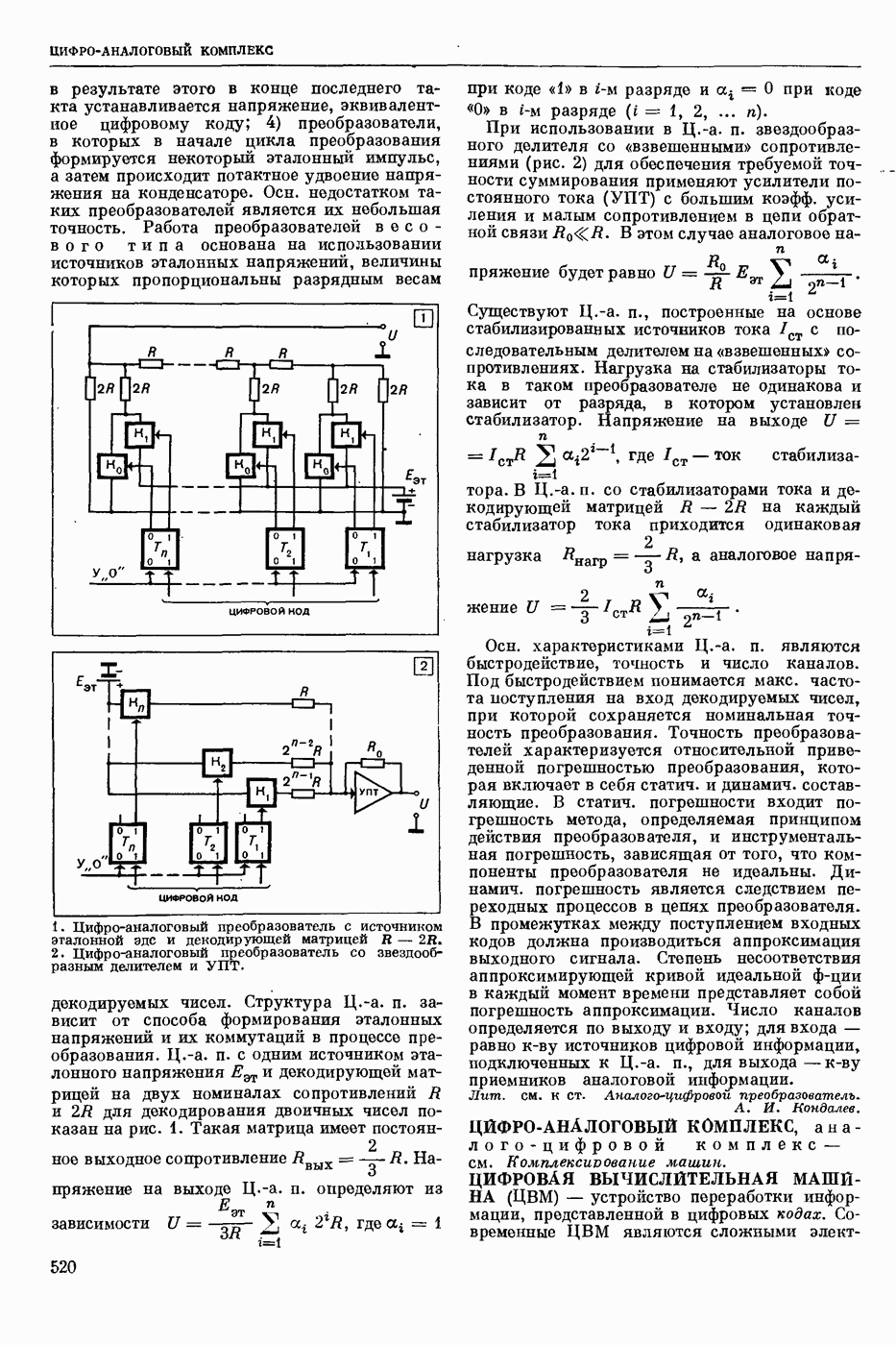
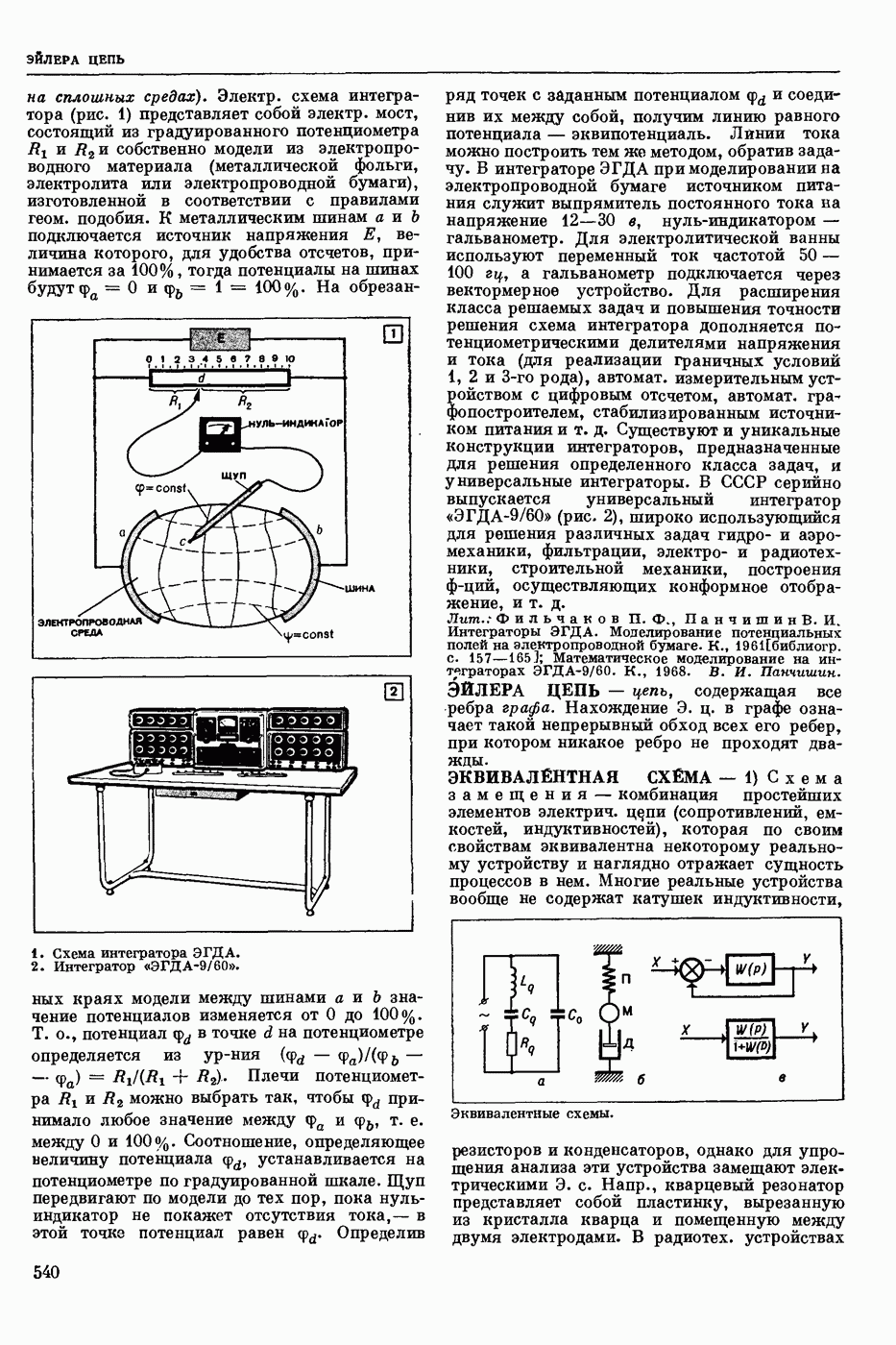
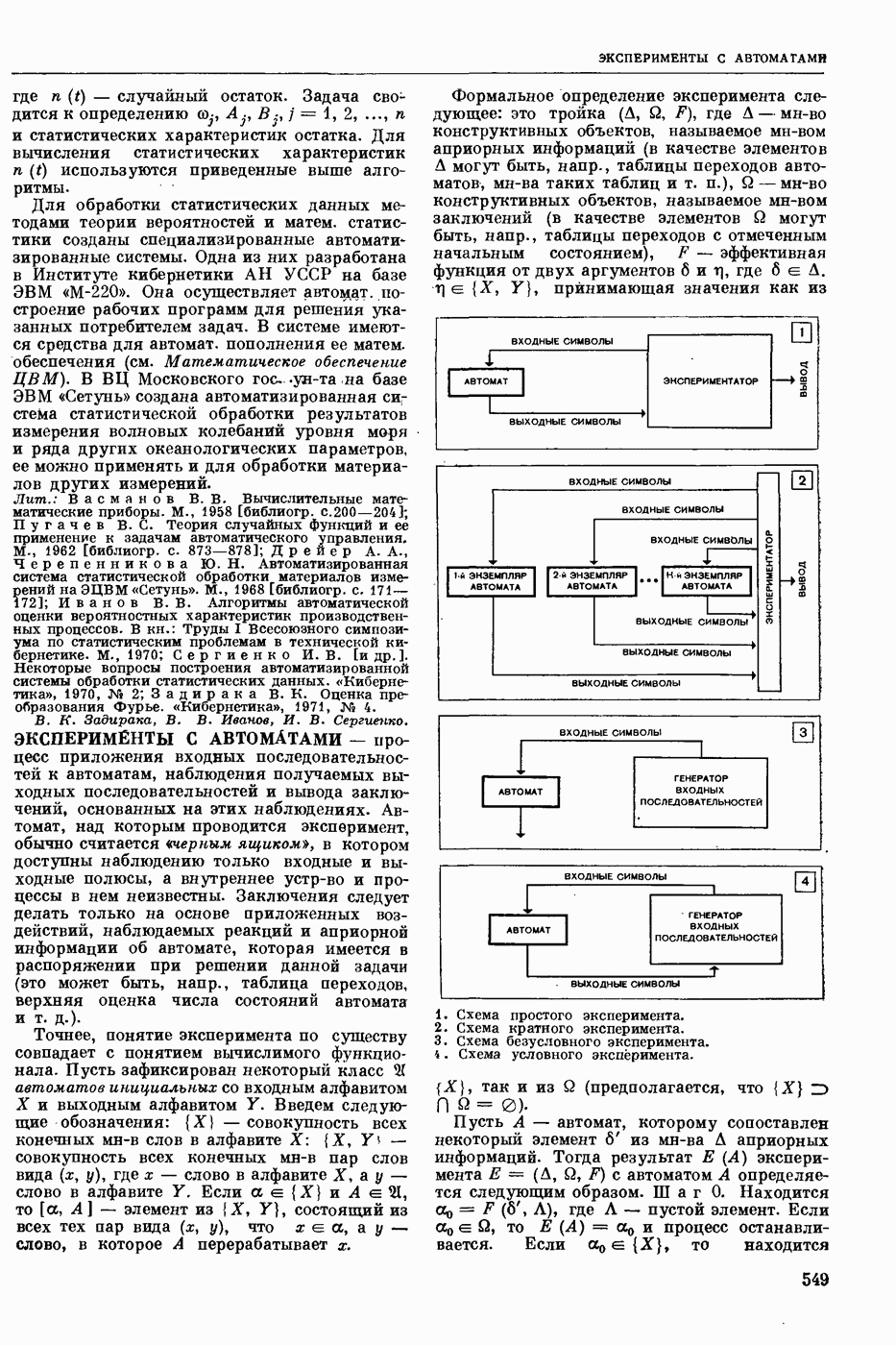
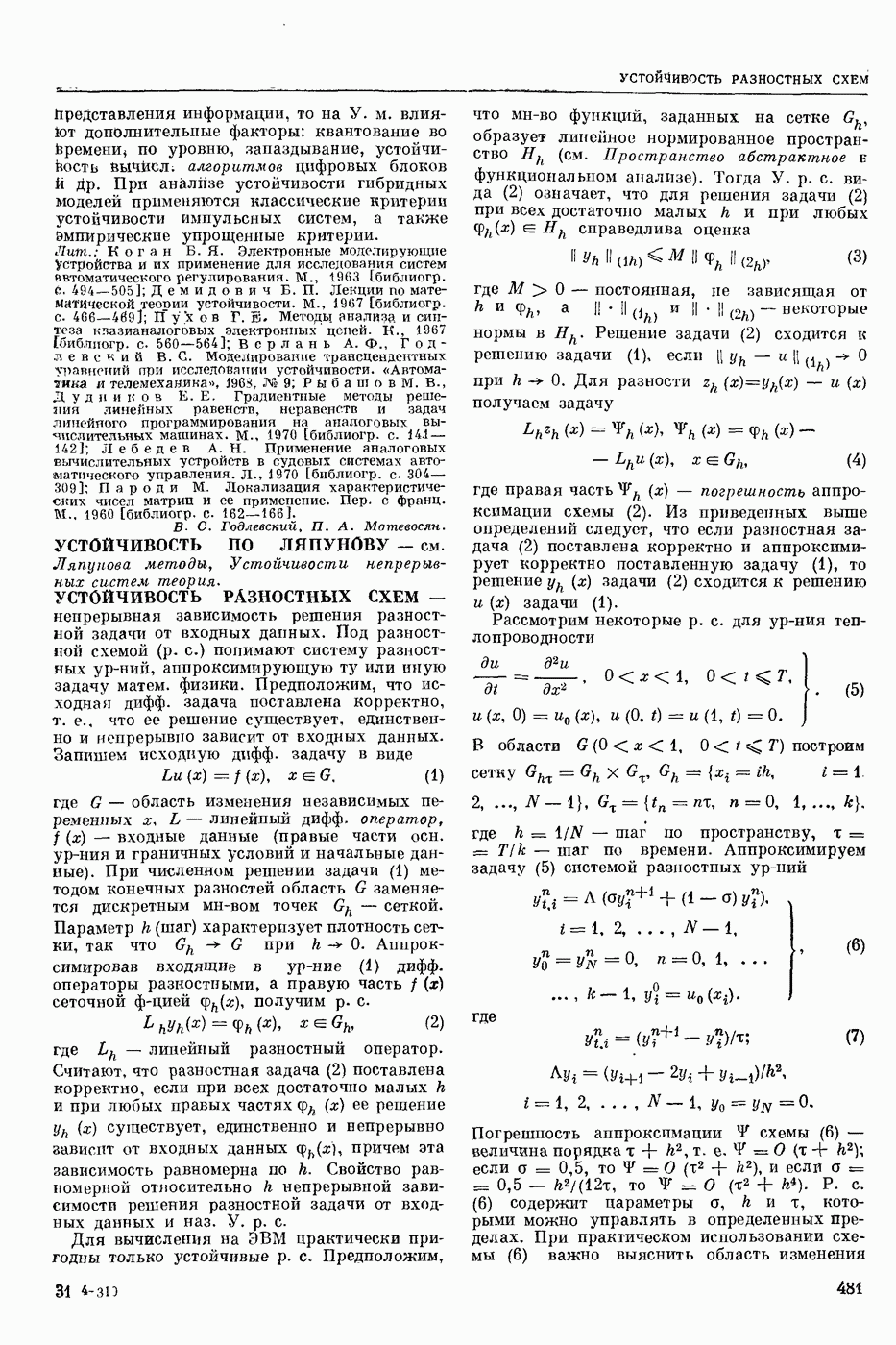СЛОВАРНЫЙ ПОИСК
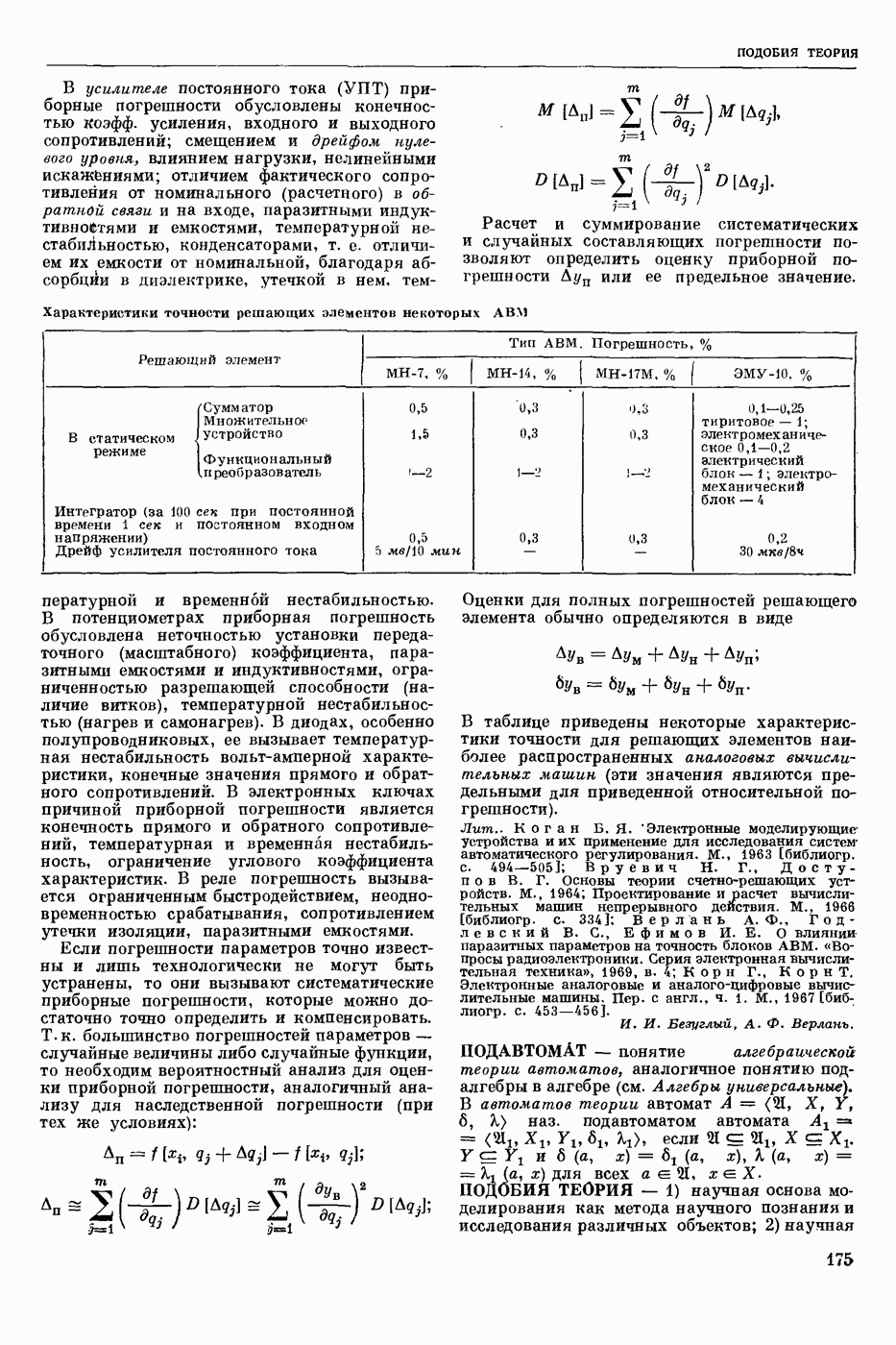
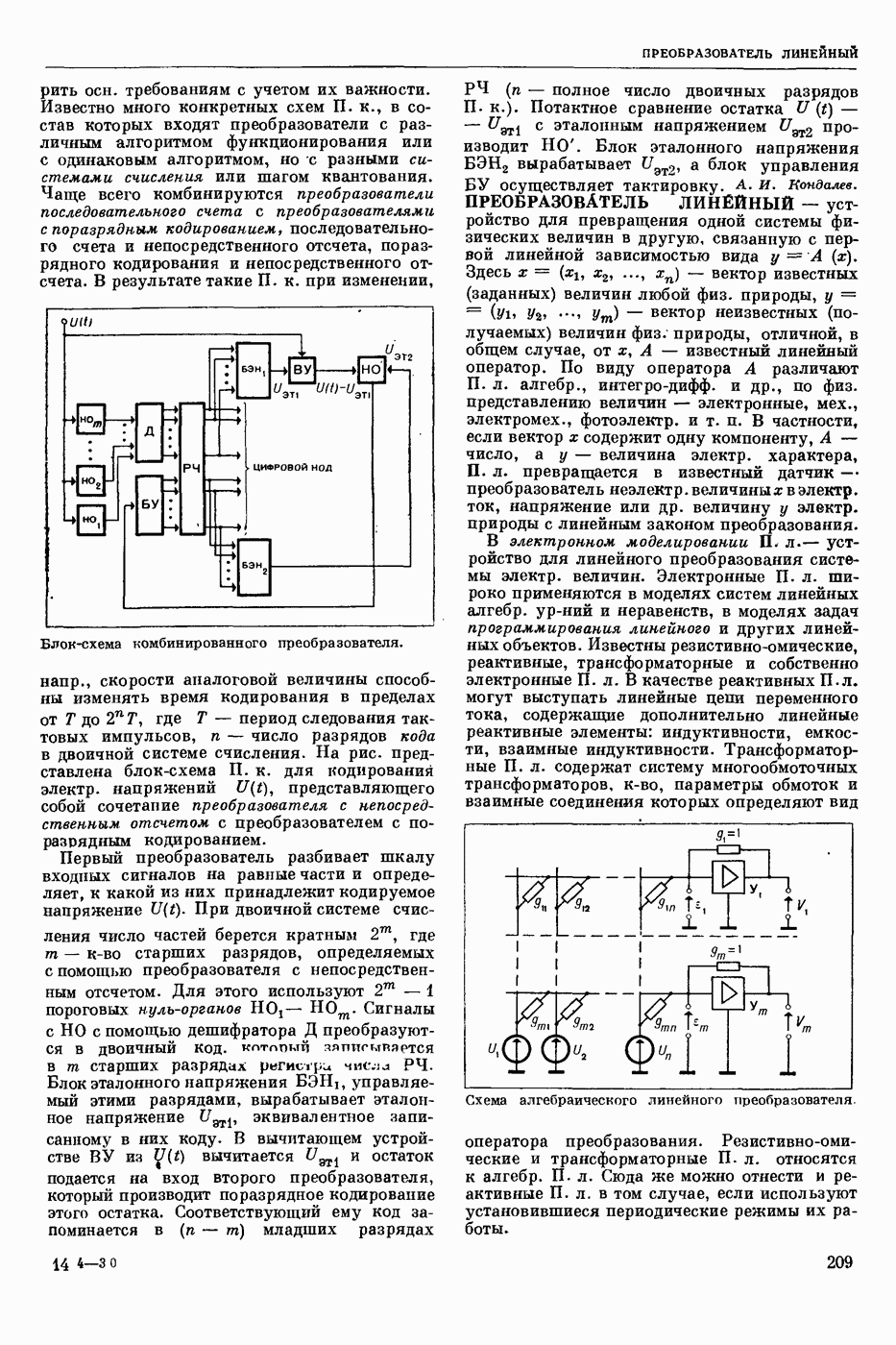
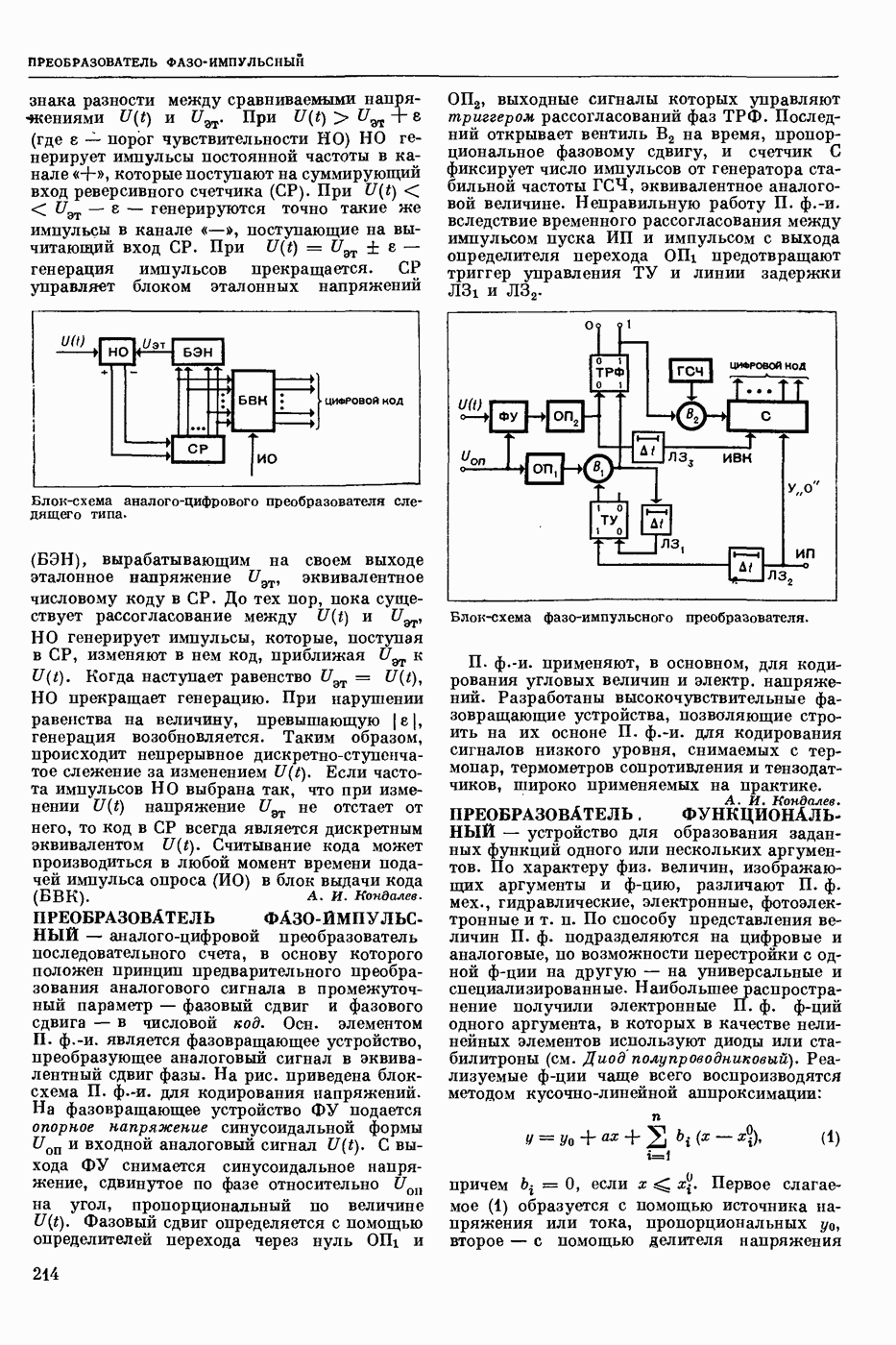
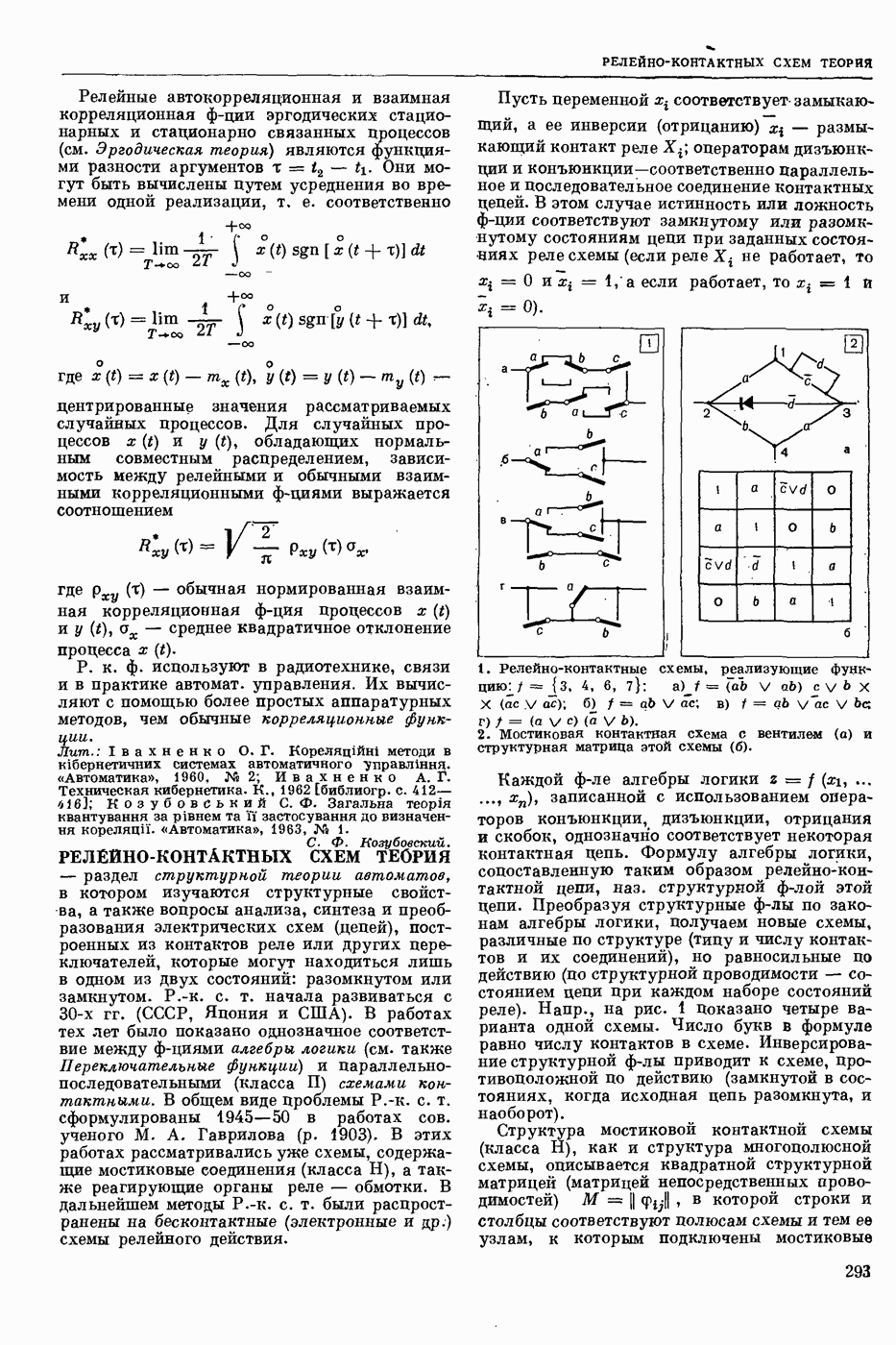
— нахождение для слова (лексической единицы) входного текста соответствующей словарной статьи в словаре автоматическом, причем поиск ведется в соответствии с некоторым алгоритмом. С. п. можно разбить на два этапа: предварительную обработку текста для сокращения суммарного времени поиска, когда это выгодно (когда поиск ведется в словаре большого объема для текстов большой длины), и собственно поиск словарных статей. Известны следующие виды предварительной обработки текста: расположение словоформ текста в алфавитном или ином порядке; составление списка слов текста без повторений; выделение основы у слов текста (при поиске в словаре основ).
При поиске словарной статьи отыскиваются заглавия словарных статей, соответствующие словоформам из текста или предварительно составленного списка. Критерием соответствия может быть: 1) совпадение словоформы текста и словоформы словаря (при поиске в словаре словоформ), либо выделенной основы и словарной основы (при поиске в словаре основ); 2) выполнение определенного соотношения между заглавием словарной статьи и словоформой текста (напр., заглавие вкладывается в данную словоформу или заглавие можно вложить в словоформу, применив к нему правила чередования); 3) совпадение числового кода, вычисляемого по словоформе текста, с кодом заглавия или адресом статьи. В случаях 2) и 3) заглавий, соответствующих искомому слову, может быть несколько.
Выбор алгоритма поиска зависит от того, как устроен словарь, в котором осуществляется поиск. Однако для всех алгоритмов поиска в словарях, в которых используется побуквенное кодирование заглавий, характерно следующее: сначала стараются по возможности более простым и экономным способом выделить зону поиска, внутри же выделенной зоны поиск ведется простым перебором или с помощью дихотомии — последовательного деления зоны поиска пополам. Несмотря на то, что метод дихотомических проб достаточно экономичен по времени (для поиска в словаре из  словарных статей требуется выполнить не более
словарных статей требуется выполнить не более  проверок), в чистом виде, т. е. без предварительного определения более узкой зоны поиска, он не применяется, т. к. предполагает одновременное хранение в ОЗУ всего словаря. Напр., при составлении словаря словоформ рус. языка (230 000 словарных статей), рассчитанного на матем. тексты, в Уэйнском ун-те (США) применялся следующий метод. При записи словаря на диски магнитные автоматически составлялась таблица, в которой отмечались первые пять букв той рус. словоформы, которая записывалась последней на каждую дорожку (на диске — 250 дорожек). При поиске сначала по первым пяти буквам слова определяется номер нужной дорожки, после этого применяется метод дихотомических проб.
проверок), в чистом виде, т. е. без предварительного определения более узкой зоны поиска, он не применяется, т. к. предполагает одновременное хранение в ОЗУ всего словаря. Напр., при составлении словаря словоформ рус. языка (230 000 словарных статей), рассчитанного на матем. тексты, в Уэйнском ун-те (США) применялся следующий метод. При записи словаря на диски магнитные автоматически составлялась таблица, в которой отмечались первые пять букв той рус. словоформы, которая записывалась последней на каждую дорожку (на диске — 250 дорожек). При поиске сначала по первым пяти буквам слова определяется номер нужной дорожки, после этого применяется метод дихотомических проб.
При поиске в словаре основ, если основа слова выделяется предварительно, используются точно такие же методы поиска, что и при поиске в словаре словоформ. Если же никакой предварительной обработки словоформы текста не делается, то С. п. тесно переплетается с морфологическим анализом. Напр., отыскивают такую основу (заглавие словарной статьи), которая вкладывается в данную словоформу. То, что при этом остается от словоформы, считается аффиксом. Возможны несколько вариантов разбиения словоформы на основу и аффиксы. Из них выбирают те, в которых полученные аффиксы «допустимы» при данной основе (информация о допустимых аффиксах записывается в словаре при основе). Такой метод поиска используется, напр., в системе рус.-франц. перевода в группе СЕТА (Гренобль, Франция), где поиск в словаре основ осуществляют две программы. Первая разбивает словоформу на основу и аффиксы, вторая — отбирает среди этих разбиений допустимые и выдает о них соответствующую словарную информацию.
Если С. п. осуществляется в словаре, где для записи заглавий применяются методы сжатого кодирования (появившиеся как следствие недостаточного объема памяти машин), то код каждой словоформы текста спец. алгоритмами преобразуется в некоторое число, по которому определяется адрес словарной статьи. Для случая совпадения адресов, полученных при сжатии различных слов, предусматриваются способы различения этой искусственной омонимии.
Лит.: Братчиков И. Л., Фитиалов С: Я., Цейтин Г. С. О структуре словаря и кодировке
информации для машинного перевода. В кн.: Материалы по машинному переводу, сб. 1. Л., 1958; Бут Э., Бут К. Автоматические цифровые машины. Пер. с англ. М., 1959 [библиогр. с. 288—315].
Я. Г. Арсентьева.